-
高并发Server的基石:reactor反应堆模式
业务开发同学只关心业务处理流程。但是我们开发的程序都是运行服务端server上,服务端server接收到IO请求后,是如何处理请求并最终进入业务流程的呢?这里不得不提到reactor反应堆模型。reactor反应堆模型来源于大师Doug Lea在 《Sacalable io in java》中的设计。nginx tomcat redis nodejs dubbo netty 等软件的网络处理模型都是用的reactor反应堆模型。
前置知识
通用网络请求处理流程
一般所有的网络服务,一般分为如下几个步骤:
- 读请求(read request)
- 读解析(read decode)
- 处理程序(process service)
- 应答编码 (encode reply)
- 发送应答(send reply)
C10K问题
C10K 问题是这样的:如何在一台物理机上同时服务 10000 个用户?这里 C 表示并发,10K 等于 10000。C10K问题早已解决,现在面临的是C10M问题。
网络IO

一次完整的网络IO流程
- 用户A发起网络写操作
- 用户B发起网络读操作
- 数据准备阶段:内核等待IO设备准备好数据
- 数据拷贝阶段:将数据从内核缓冲区拷贝到用户空间缓冲区
阻塞IO
读数据时,如果内核缓冲区没有数据,执行read()操作的线程会挂起在这里,不能做其他的事情
多路复用IO
IO多路复用是一种高效的IO模型,它的特点是可以同时监控多个文件描述符,提高了应用程序对输入输出操作的管理能力。当用户进程使用select、poll或epoll等系统调用时,它会将需要监控的文件描述符传递给内核,然后内核会在所有文件描述符中寻找就绪的文件描述符,并返回给用户进程。用户进程再根据就绪的文件描述符进行相应的读写操作。
IO多路复用的优点是可以使用一个线程或进程来处理多个文件描述符,避免了多线程或多进程的开销,提高了系统的并发性和可伸缩性。IO多路复用的缺点是需要额外的系统调用来管理文件描述符,而且在数据拷贝阶段仍然是阻塞的。IO多路复用比较适合网络编程,比如服务器端的并发处理。

两类经典的网络模式
基于线程(进程)的 Thread(Process)-per-connection
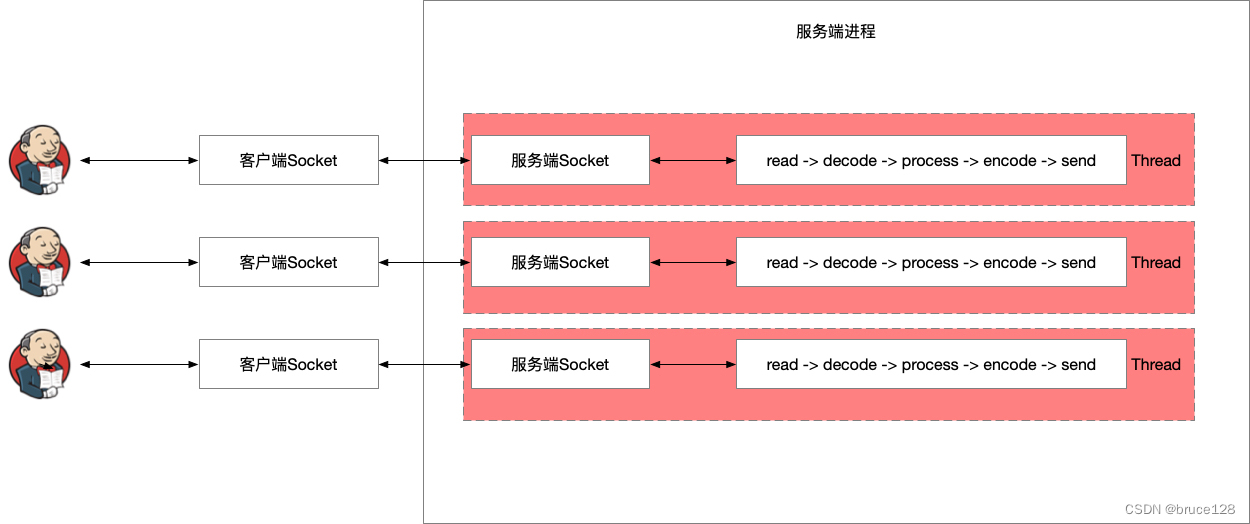
TPC是Thread Per Connection的缩写,其含义是指每次有新的连接就新建一个线程去专门处理这个连接的请求。
缺点:
- 每新增一个客户端需要服务端新开一个线程支持,线程是很重的资源。
- 线程多了后,线程上下文切换很耗cpu
- 连接建立后,如果当前线程暂时没有数据可读,则线程就阻塞在 Read 操作上,造成线程资源浪费。
基于事件驱动的Reactor模式
单reactor单线(进)程

使用场景:客户端的数量有限,业务处理非常快速,比如 Redis ,6.0版本前的redis采用此方案
所有的线程都在同一个线程中循环处理。如果某个请求耗时很长,那么其他的请求只能阻塞等待。
单reactor多线程

为了解决单reactor单线程模型的缺陷,多线程模型应运而生。多线程模型引入worker线程池来处理请求的业务逻辑。
绝大部分请求的耗时都是在process这个阶段,因此引入worker线程池对性能的改善十分有效。
当然,这种模型也有明显缺点,连接建立、IO 事件读取以及事件分发完全有单线程处理;比如当某个连接通过系统调用正在读取数据,此时相对于其他事件来说,完全是阻塞状态,新连接无法处理、其他连接的 IO、查询 IO 读写以及事件分发都无法完成。
多reactor多线(进)程

在多线程模型中,我们提到,其主要缺陷在于同一时间无法处理大量新连接、IO就绪事件;因此,将主从模式应用到这一块,就可以解决这个问题。
主从 Reactor 模式中,分为了主 Reactor 和 从 Reactor,分别处理 新建立的连接、IO读写事件/事件分发。
- 一来,主 Reactor 可以解决同一时间大量新连接,将其注册到从 Reactor 上进行IO事件监听处理
- 二来,IO事件监听相对新连接处理更加耗时,此处我们可以考虑使用线程池来处理。这样能充分利用多核 CPU 的特性,能使更多就绪的IO事件及时处理。
简言之,主从多线程模型由多个 Reactor 线程组成,每个 Reactor 线程都有独立的 Selector 对象。MainReactor 仅负责处理客户端连接的 Accept 事件,连接建立成功后将新创建的连接对象注册至 SubReactor。再由 SubReactor 分配线程池中的 I/O 线程与其连接绑定,它将负责连接生命周期内所有的 I/O 事件。
类比
3 种模式可以用个比喻来理解:(餐厅常常雇佣前台接待员负责迎接顾客,当顾客入坐后,服务员专门为这张桌子服务,点好菜后,厨师负责做饭)
- 1)单 Reactor 单线程,前台接待员、服务员、厨子是同一个人,全程为顾客服务;
- 2)单 Reactor 多线程,前台接待员和服务员是一个人,厨师有多个;
- 3)主从 Reactor 多线程,一个前台接待员负责,多个服务员,多个厨师
reactor线程模型

- Acceptor:请求接收者,作用是在特定端口建立监听。
- Main Reactor Thread Pool:主 Reactor 模型,主要负责处理 OP_ACCEPT 事件(创建连接),通常一个监听端口使用一个线程。在具体实践时,如果创建连接需要进行授权校验(Auth)等处理逻辑,也可以直接让 Main Reactor 中的线程负责。
- Subreactor Thread Group( IO 线程组):在 Reactor 模型中也叫做从 Reactor,主要负责网络的读与写。当 Main Reactor Thread 线程收到一个新的客户端连接时,它会使用负载均衡算法从 NIO Thread Group 中选择一个线程,将 OP_READ、OP_WRITE 事件注册在 NIO Thread 的事件选择器中。接下来这个连接所有的网络读与写都会在被选择的这条线程中执行。
- IO Thread:IO 线程。负责处理网络读写与解码。IO 线程会从网络中读取到二进制流,并从二进制流中解码出一个个完整的请求。业务线程池:通常 IO 线程解码出的请求将转发到业务线程池中运行,业务线程计算出对应结果后,再通过 IO 线程发送到客户端。
- Worker thread pool: 业务线程池,处理具体的业务。业务开发同学的代码通常在这个线程池工作。
reactor bio对比
NIO 模型更适合需要大量在线活跃连接的场景,常见于服务端;BIO 模型则适合只需要支持少量连接的场景,数据库连接池使用的事这个模型。
reactor的代码实现:https://github.com/bruce256/NIO
参考资料
- https://gee.cs.oswego.edu/dl/cpjslides/nio.pdf Doug Lea的论文
- https://time.geekbang.org/column/article/532729 NIO:手撸一个简易的主从多Reactor线程模型
-
相关阅读:
MySQL的增删查改(CRUD)
luffy项目后端轮播图接口
剑指 Offer II 042. 最近请求次数-队列法
如何在 Spring 或 Spring Boot 中使用键集分页
【ros学习笔记】-9 ros基本概念
openstack 遇到的error
【1day】用友移动管理系统任意文件上传漏洞学习
NeuralProphet之一:安装与使用
表设计的18条军规
FPGA ——Verilog语法示例
- 原文地址:https://blog.csdn.net/bruce128/article/details/136257122