-
win10 环境下Python 3.8按装fastapi paddlepaddle 进行图片文字识别1
###按装
用conda 创建python 3.8的环境,可参看本人python下的其它文章。
在pycharm开发环境下按装相关的模块:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple fastapi pip install -i https://pypi.tuna.tsinghua.edu.cn/simple "uvicorn[standard]" pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple pip install "paddleocr>=2.0.1" -i https://mirror.baidu.com/pypi/simple pip install shapely -i https://mirror.baidu.com/pypi/simple- 1
- 2
- 3
- 4
- 5
###开发代码:
# 导入requests库,用于发送HTTP请求 import requests # 导入FastAPI库,用于构建高性能的Web应用程序 from fastapi import FastAPI # 导入PaddleOCR及其draw_ocr方法,PaddleOCR是一个使用PaddlePaddle深度学习框架的OCR工具 from paddleocr import PaddleOCR, draw_ocr # 导入BytesIO,用于在内存中处理二进制流 from io import BytesIO # 导入PIL库中的Image模块,用于处理图像 from PIL import Image import os # 初始化PaddleOCR实例,配置使用方向分类器、不使用GPU、识别中文 ocr = PaddleOCR(use_angle_cls=True, use_gpu=False, lang="ch") # 创建一个FastAPI应用实例 app = FastAPI() # 定义一个异步的GET请求处理函数,路径为"/",接收一个名为url的查询参数 @app.get("/") async def root(url: str): try: # 使用requests库发送GET请求,获取指定URL的图片,stream=True表示以流的形式下载大文件 response = requests.get(url, stream=True) # 如果HTTP请求返回的状态码不是200,则引发HTTPError异常 response.raise_for_status() # 检查响应头中的content-type是否包含'image',以确认返回的内容是图片 if 'image' not in response.headers.get('content-type', ''): # 如果不是图片,返回错误信息,HTTP状态码为400(Bad Request) return {"error": "The provided URL does not point to an image."}, 400 # 使用BytesIO将响应内容转换为二进制流 image_bytes = BytesIO(response.content) # 使用PIL库打开二进制流中的图像 image = Image.open(image_bytes) # 将图像保存到临时文件中(这里是为了适应PaddleOCR可能需要文件路径的API) # 注意:这里的代码实际上有一个逻辑错误,因为image.save()应该放在with语句块内以确保文件正确关闭 temp_image_path = "temp_image.jpg" with open(temp_image_path, "wb") as image_file: image.save(image_file, format='JPEG') # 调用PaddleOCR的ocr方法进行OCR处理,cls=True表示使用分类器 result = ocr.ocr(temp_image_path, cls=True) if os.path.exists(temp_image_path): os.remove(temp_image_path) results = [] # 遍历最外层的列表 for item in result: # 遍历内层的列表 for sub_item in item: # 提取文本和可能性 text = sub_item[1][0] # 文本位于第二个子列表的第一个位置 probability = sub_item[1][1] # 可能性位于第二个子列表的第二个位置 # 将提取的文本和可能性作为一个元组添加到结果列表中 results.append((text, probability)) # 返回OCR处理结果,封装在message字段中(注意:这里没有删除临时文件,可能会导致磁盘空间被占用) return {"message": results} except requests.exceptions.RequestException as e: # 如果在发送HTTP请求过程中发生异常,捕获异常并返回错误信息,HTTP状态码为500(Internal Server Error) return {"error": f"An error occurred while downloading the image: {str(e)}"}, 500 except Exception as e: # 如果在处理过程中发生其他类型的异常,同样捕获异常并返回错误信息,HTTP状态码为500 return {"error": f"An error occurred during OCR processing: {str(e)}"}, 500- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
在网上找一张图片:
https://img-s-msn-com.akamaized.net/tenant/amp/entityid/BB1ifoqa.img?w=768&h=662&m=6
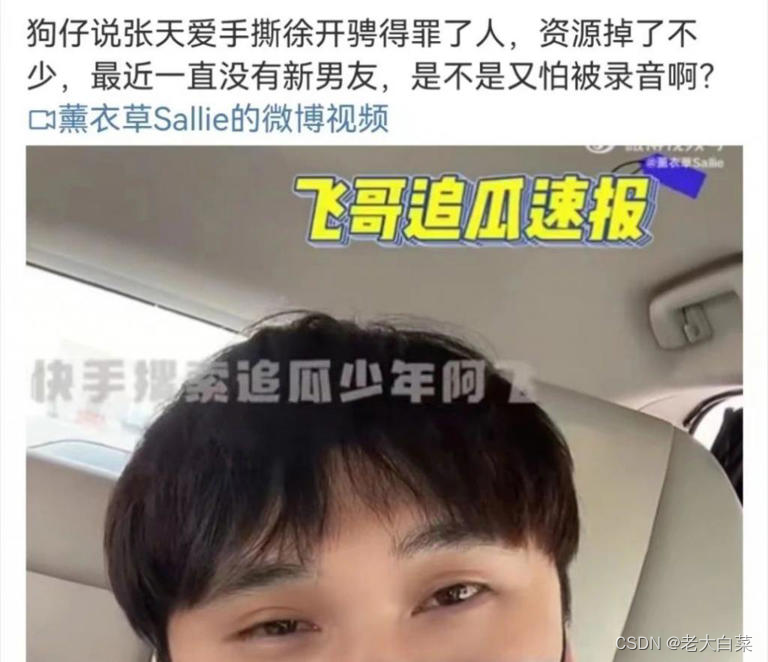
运行代码:uvicorn main:app --reload- 1
返回结果:
{ "message": [ [ "狗仔说张天爱手撕徐开骋得罪了人,资源掉了不", 0.9765021800994873 ], [ "少,最近一直没有新男友,是不是又怕被录音啊?", 0.9926691055297852 ], [ "C薰衣草Sallie的微博视频", 0.9560778737068176 ], [ "飞哥追瓜速报", 0.9982643723487854 ], [ "快手搜索追瓜少年阿", 0.8913857936859131 ] ] }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24

-
相关阅读:
DLP是如何防止数据泄露的?
zabbix 代理服务器 与 zabbix-snmp 监控
Springboot引入jasypt实现加解密
C++基础(3)——类与对象
记录Centos7.9 安装mongodb 6.0 过程遇到的坑和解决办法
【OpenGL】五、光照
RCNN系列1:RCNN介绍
数仓面试题(1)
开源文档预览项目 kkFileView (9.9k star) ,快速入门
Vue3.3 的新功能的体验(下):泛型组件(Generic Component) 与 defineSlots
- 原文地址:https://blog.csdn.net/hzether/article/details/136117420
