-
【机器学习笔记】11 支持向量机
支 持 向 量 机 ( Support Vector Machine,SVM )
支 持 向 量 机 是 一 类 按 监 督 学 习 ( supervisedlearning)方式对数据进行二元分类的广义线性分类器(generalized linear classifier),其决策边界是对学习样本求解的最大边距超平面(maximum-margin hyperplane) 。与逻辑回归和神经网络相比,支持向量机,在学习复杂的非线性方程时提供了一种更为清晰,更加强大的方式。
- 算法思想
找到集合边缘上的若干数据(称为支持向量(Support Vector)),用这些点找出一个平面(称为决策面),使得支持向量到该平面的距离最大。
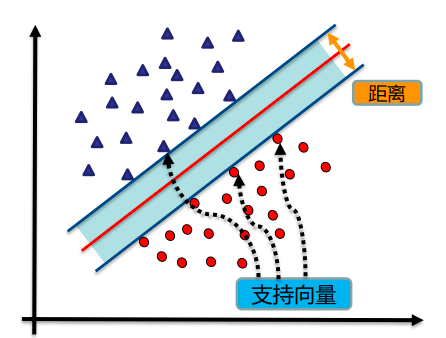
假如数据是完全的线性可分的,那么学习到的模型可以称为硬间隔支持向量机。换个说法,硬间隔指的就是完全分类准确,不能存在分类错误的情况。软间隔,就是允许一定量的样本分类错误。

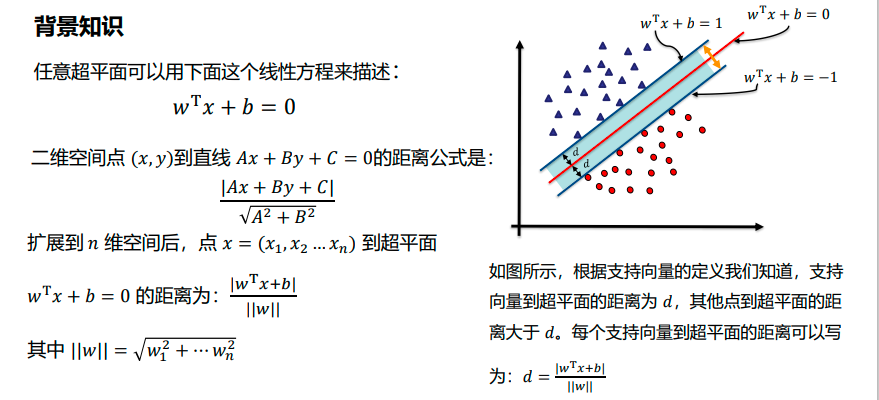
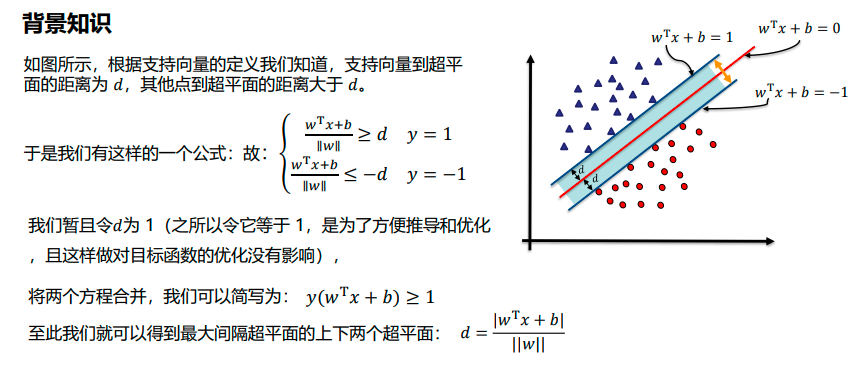
线性可分支持向量机
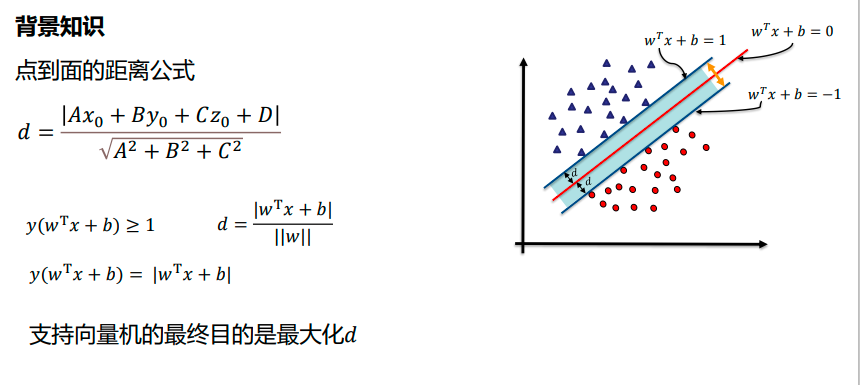



线性支持向量机



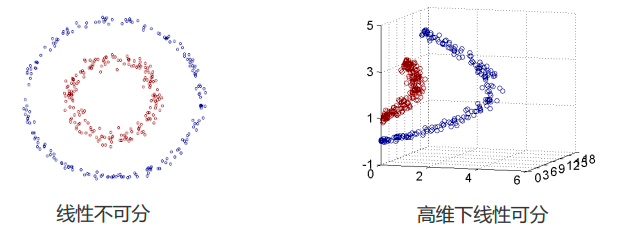
线性不可分支持向量机
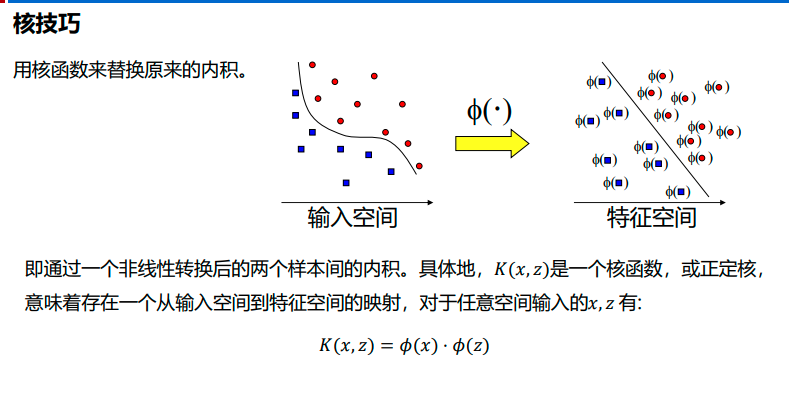
核技巧
在低维空间计算获得高维空间的计算结果,满足高维,才能在高维下线性可分。 我们需要引入一个新的概念:核函数。它可以将样本从原始空间映射到一个更高维的特质空间中,使得样本在新的空间中线性可分。这样我们就可以使用原来的推导来进行计算,只是所有的推导是在新的空间,而不是在原来的空间中进行,即用核函数来替换当中的内积。


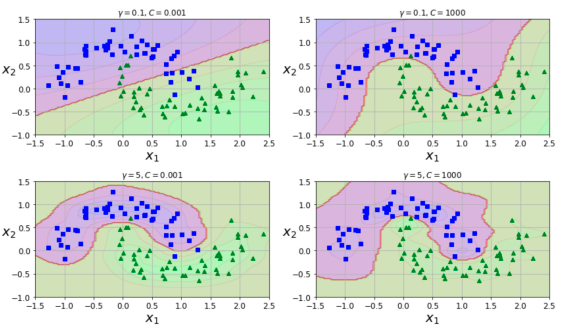
SVM的超参数
𝛾越大,支持向量越少,𝛾值越小,支持向量越多。其中 C是惩罚系数,即对误差的宽容度。 C越高,说明越不能容忍出现误差,容易过拟合。C越小,容易欠拟合。
SVM普遍使用的准则:
𝑛为特征数,𝑚为训练样本数。
(1)如果相较于𝑚而言,𝑛要大许多,即训练集数据量不够支持我们训练一个复杂的非线性模型,我们选用逻辑回归模型或者不带核函数的支持向量机。
(2)如果𝑛较小,而且𝑚大小中等,例如𝑛在 1-1000 之间,而𝑚在10-10000之间,使用高斯核函数的支持向量机。
(3)如果𝑛较小,而𝑚较大,例如𝑛在1-1000之间,而𝑚大于50000,则使用支持向量机会非常慢,解决方案是创造、增加更多的特征,然后使用逻辑回归或不带核函数的支持向量机。 - 算法思想
-
相关阅读:
详解nginx的root与alias
电子书(chm)-加载JS--CS上线
C#二叉树结构定义、添加节点值
React学习--- 事件处理
使用R语言进行Logistic回归分析(2)
ubuntu18.04环境下部署ROS2 docker镜像全步骤
图书信息管理系统(二)
Oracle GoldenGate(OGG)到入土
MySQL - 为什么InnoDB选择B+树索引?Change buffer?
pikachu下载及安装-图文详解+phpStudy配置
- 原文地址:https://blog.csdn.net/qq_44894943/article/details/136139017