-
flink state原理,TTL,状态后端,数据倾斜一文全
flink state原理
- 1. 状态、状态后端、Checkpoint 三者之间的区别及关系?
- 2 算子状态与键控状态的区别
- 3 HashMapStateBackend 状态后端
- 4 EmBeddedRocksDbStateBackend 状态后端
- 5 状态数据结构介绍
- 6 Reducing 聚合状态
- 7 广播状态
- 8. flink重启时,修改并行度,state会发生什么变化?键值状态分区策略,解决数据倾斜
- 9.Flink State TTL 是怎么做到数据过期的?首先我们来想想,要做到 TTL 的话,要具备什么条件呢?
- 10.Flink SQL API State TTL 的过期机制是 onCreateAndUpdate 还是onReadAndWrite
- 5.operator-state 和 keyed-state 两者的区别?最大并行度又和它们有什么关系?举个生产环境中经常出现的案例,当用户停止任务、更新代码逻辑并且改变任务并发度时,两种 state 都是怎样进行恢复的?
- 11.ValueState 和 MapState 各自适合的应用场景?
1. 状态、状态后端、Checkpoint 三者之间的区别及关系?
拿五个字做比喻:“铁锅炖大鹅”,铁锅是状态后端,大鹅是状态,Checkpoint 是炖的动作。
-
状态:本质来说就是数据,在 Flink 中,其实就是 Flink 提供给用户的状态编程接口。比如 flink 中的 MapState,ValueState,ListState。
-
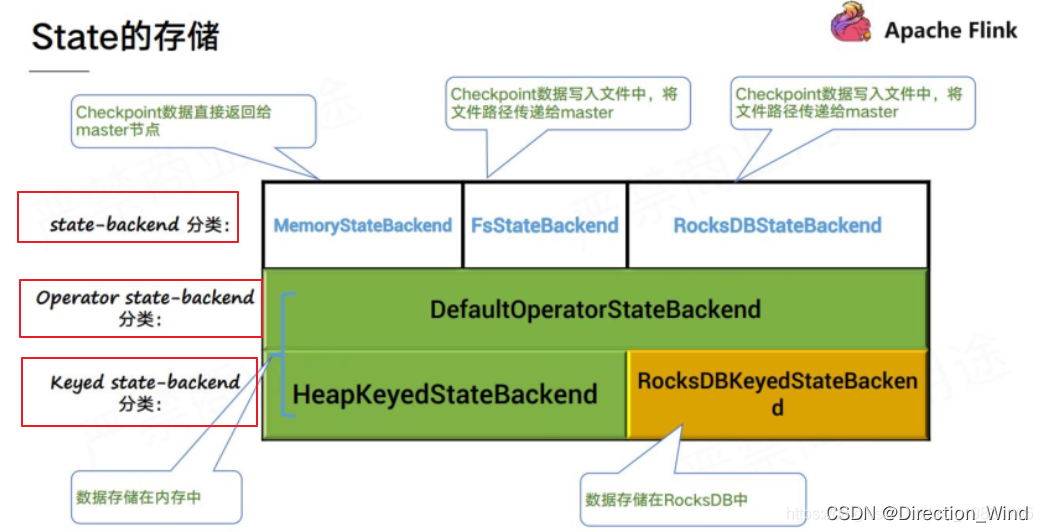
状态后端:Flink 提供的用于管理状态的组件,状态后端决定了以什么样数据结构,什么样的存储方式去存储和管理我们的状态。Flink 目前官方提供了 memory、filesystem,rocksdb 三种状态后端来存储我们的状态。
但!flink1.13后 对状态后端做了整合,只有这两种了
- HashMapStateBackend
- EmbeddedRocksDBStateBackend
老版本(flink-1.12 版及以前) Fsstatebackend MemoryStatebackend RocksdbStateBackend
新版本中,Fsstatebackend 和 MemoryStatebackend 整合成了 HashMapStateBackend 而且 HashMapStateBackend 和 EmBeddedRocksDBStateBackend 所生成的快照文件也统一了格式,因而 在 job 重新部署或者版本升级时,可以任意替换 statebackend- Checkpoint(状态管理):Flink 提供的用于定时将状态后端中存储的状态同步到远程的存储系统的组件或者能力。为了防止 long run 的 Flink 任务挂了导致状态丢失,产生数据质量问题,Flink 提供了状态管理(Checkpoint,Savepoint)的能力把我们使用的状态给管理起来,定时的保存到远程。然后可以在 Flink 任务 failover 时,从远程把状态数据恢复到 Flink 任务中,保障数据质量。
2 算子状态与键控状态的区别
2.1 算子状态
- 算子状态,是每个 subtask 自己持有一份独立的状态数据(但如果在失败恢复后,算子并行度发 生变化,则状态将在新的 subtask 之间均匀分配);
- 算子函数实现 CheckpointedFunction 后,即可使用算子状态;
- 算子状态,通常用于 source 算子中;其他场景下建议使用 KeyedState(键控状态);
- 算子状态,在逻辑上,由算子 task 下所有 subtask 共享; 如何理解:正常运行时,subtask 自己读写自己的状态数据;而一旦 job 重启且带状态算子发生了并行度的变化,则 之前的状态数据将在新的一批 subtask 间均匀分配
2.2 键控状态
- 键控状态,只能应用于 KeyedStream 的算子中(keyby 后的处理算子中);
- 算子为每一个 key 绑定一份独立的状态数据;

2.3 算子状态api
要使用算子状态(operator state),需要让算子函数实现 CheckpointedFunction 接口;
/*** * @author hunter.d * @qq 657270652 * @wx haitao-duan * @date 2022/4/10 **/ public class OperatorStateTest { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.setString("execution.savepoint.path", "D:\\ckpt\\27270525e8f166834f2bbf7c617ad6d3\\chk-11"); StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(conf); env.enableCheckpointing(2000); env.getCheckpointConfig().setCheckpointStorage("file:///d:/ckpt"); DataStreamSource<String> source = env.socketTextStream("localhost", 9999); //以下两个 map 算子,其中一个是带状态的 // 如果修改代码逻辑(如调整两个 map 算子顺序),且没有设置 uid,则从 savepoints 恢复时将失败 source.map(new StatefulMapFunc()).uid("stateful-mapfunc-001").setParallelism(2).map(new NoStateMapFunc()).setParallelism(1).print().setParallelism(1); env.execute(); } public static class NoStateMapFunc implements MapFunction<String, String> { @Override public String map(String value) throws Exception { return value.toUpperCase(); } } // 带状态的 map 函数(将接收的字符串记在状态中,以不断拼接新数据返回) public static class StatefulMapFunc extends RichMapFunction<String, String> implements CheckpointedFunction { ListState<String> lstState; /*** 正常的 map 映射逻辑方法 */ @Override public String map(String value) throws Exception { lstState.add(value); StringBuilder sb = new StringBuilder(); for (String s : lstState.get()) { sb.append(s).append(","); } return sb.toString(); } /*** checkpoint 触发时会调用的方法 */ @Override public void snapshotState(FunctionSnapshotContext context) throws Exception { } /*** 初始化算子任务时会调用的方法,以加载、初始化状态数据 */ @Override public void initializeState(FunctionInitializationContext context) throws Exception { lstState = context.getOperatorStateStore().getListState(new ListStateDescriptor<String>("lst", String.class)); int indexOfThisSubtask = getRuntimeContext().getIndexOfThisSubtask(); Iterable<String> iter = lstState.get(); Iterator<String> it = iter.iterator(); // 用于观察 task 失败恢复后的状态恢复情况 System.out.println("-------" + indexOfThisSubtask + " - 初始化时,打印状态:-----"); while (it.hasNext()) { System.out.println(indexOfThisSubtask + ":" + it.next()); } System.out.println("-------" + indexOfThisSubtask + " -初始化时,打印状态:-----"); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
2.4 键控状态api
要使用键控状态(Keyed State),需要在实现 RichFunction 的函数中;
public class _15_ChannelEventsCntMapFunc extends RichMapFunction<EventLog, String> { ValueState<Integer> valueState; @Override public void open(Configuration parameters) throws Exception { StateTtlConfig ttlConfig = StateTtlConfig.newBuilder(Time.milliseconds(2000)).cleanupFullSnapshot().neverReturnExpired().useProc essingTime().updateTtlOnReadAndWrite().build(); ValueStateDescriptor<Integer> desc = new ValueStateDescriptor<>("cnt", Integer.class); desc.enableTimeToLive(ttlConfig); // 获取单值状态管理器 valueState = getRuntimeContext().getState(desc); } @Override public String map(EventLog eventLog) throws Exception { // 来一条数据,就对状态更新 valueState.update((valueState.value() == null ? 0 : valueState.value()) + 1); return eventLog.getChannel() + " : " + valueState.value(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
3 HashMapStateBackend 状态后端
HashMapStateBackend:
-
状态数据是以 java 对象形式存储在 heap 内存中;
-
内存空间不够时,也会溢出一部分数据到本地磁盘文件;
-
可以支撑大规模的状态数据;(只不过在状态数据规模超出内存空间时,读写效率就会明显降低)
-
对于 KeyedState 来说:
HashMapStateBackend 在内存中是使用 CopyOnWriteStateMap 结构来存储用户的状态数据; 注意,此数据结构类,名为 Map,实非 Map,它其实是一个单向链表的数据结构 -
对于 OperatorState 来说:

可以清楚看出,它底层直接用一个 Map 集合来存储用户的状态数据:状态名称 --> 状态 List
4 EmBeddedRocksDbStateBackend 状态后端
- 状态数据是交给 rocksdb 来管理;
- Rocksdb 中的数据是以序列化的 kv 字节进行存储;
- Rockdb 中的数据,有内存缓存的部分,也有磁盘文件的部分;
- Rockdb 的磁盘文件数据读写速度相对还是比较快的,所以在支持超大规模状态数据时,数据的 读写效率不会有太大的降低
注意:上述 2 中状态后端,在生成 checkpoint 快照文件时,生成的文件格式是完全一致的; 所以,用户的 flink 程序在更改状态后端后,重启时依然可以加载和恢复此前的快照文件数据;
老版本中,状态与状态后端的关系是:
5 状态数据结构介绍
5.1 算子状态提供的数据结构
ListState , UnionListState
UnionListState 和普通 ListState 的区别:- UnionListState 的快照存储数据,在系统重启后,list 数据的重分配模式为: 广播模式; 在每个 subtask 上都拥有一份完整的数据;
- ListState 的快照存储数据,系统重启后,list 数据的重分配模式为: round-robin 轮询平均分配
5.2 键控状态提供的数据结构
ValueState ListState MapState ReducingState AggregateState
6 Reducing 聚合状态
用户传入一个增量聚合函数后,状态实现自动增量聚合(输入数据与聚合结果类型必须一致)
// 获取一个 reduce 聚合状态 reduceState =runtimeContext.getReducingState(new ReducingStateDescriptor<Integer>("reduceState",new ReduceFunction<Integer>() { @Override public Integer reduce (Integer value1, Integer value2) throws Exception { return value1 + value2; } },Integer .class));- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
7 广播状态
/*** * @author hunter.d * @qq 657270652 * @wx haitao-duan * @date 2022/4/10 **/ public class OperatorStateTest { // 主数据流 SingleOutputStreamOperator<Student> s1; // 待广播出去的流 SingleOutputStreamOperator<StuInfo> s2; // 定义广播状态的状态描述对象 MapStateDescriptor<Integer, StuInfo> stateDescriptor = new MapStateDescriptor<>("info", Integer.class, StuInfo.class); // 将 s2 流广播出去 BroadcastStreamstuInfoBroadcastStream =s2.broadcast(stateDescriptor); // 用主数据流 connect 连接 广播数据流,并处理 s1.connect(stuInfoBroadcastStream). process(new BroadcastProcessFunction<Student, StuInfo, String>() { @Override public void processElement (Student student, ReadOnlyContext readOnlyContext, Collector < String > collector) throws Exception { // 对 "主流" 中的元素进行处理 readOnlyContext.getBroadCastState(); // 只读状态 } @Override public void processBroadcastElement (StuInfo stuInfo, Context context, Collector < String > collector) throws Exception { // 对 "广播流" 中的元素进行处理 context.getBroadCastState(); // 可读可写 } }); } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
8. flink重启时,修改并行度,state会发生什么变化?键值状态分区策略,解决数据倾斜
假设原来是3个并行度

重启之后给两个并行度,state会发生什么呢?他依然可以加载之前的快照数据
这里面引入一下 : subtask 是什么呢,相当于 每一个算子,就是一个subtask,像下面的 4个sink 就是4个subtask,4个并行度。

那么说回来,3个并行度 改成了两个,少了一个,这个subtask上存储的state 要怎么办呢。
假设你用的是liststate。重启的时候 ,会自动做分配到剩余的两个state里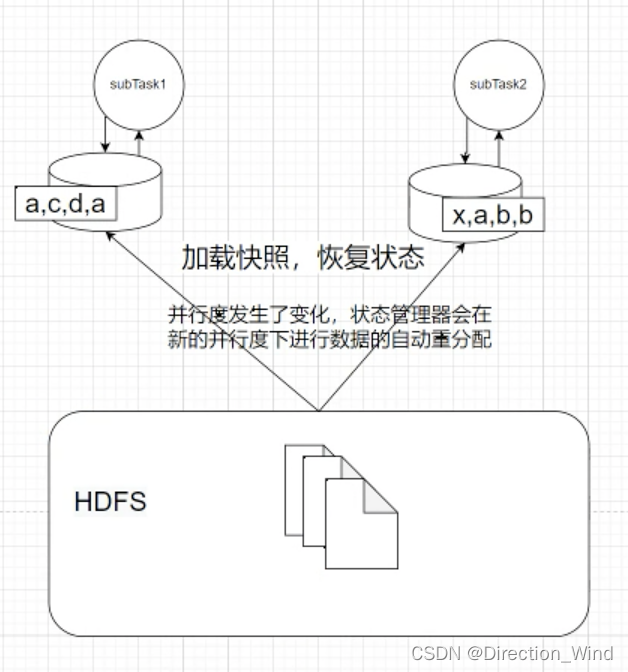
也可能是,直接重新分配给某一个state,以前 三个并行度,分别读kafka的三个分区,1分区 1000,2 分区 500, 3分区 800
重新分配后,就变成了 1分区 1000+3分区 800 ; 2 分区 500 这种情况。在键值状态API的设计思路小节中,我们提到键值状态在重分布时要和KeyedStream的哈希数据分区策略保持完全一致。原理理解起来简单,但实际上Flink键值状态重分布的机制在此基础上还做了很多的性能优化,本节我们就详细剖析键值状态重分布的过程,掌握这部分知识将会对我们在生产环境中解决数据倾斜问题有很大的帮助。
我们以电商场景中计算每种商品累计销售额的场景为例,逻辑数据流为Source→KeyBy\Map→Sink,我们在KeyBy\Map算子中使用键值状态ValueState来保存每种商品的累计销售额。
接下来我们看看ValueState键值状态在KeyBy\Map算子并行度从2变为3时键值状态的重分布过程。如图6-28所示,我们用parallelism代表算子并行度,假设KeyedStream的哈希数据分区策略的计算公式为SubTask(key)=hash(key)%parallelism(符号%代表取余计算),该计算公式用于计算某个key的数据要被发往KeyBy\Map算子的SubTask下标。
当KeyBy\Map算子的并行度为2时,哈希数据分区策略就为SubTask(key)=hash(key)%2,假设这时经过计算后,key为商品3的数据会被发送到KeyBy\Map[1]中,那么商品3的累计销售额的状态数据就会存储在KeyBy\Map[1]本地。当用户将KeyBy\Map算子的并行度扩展为3后,哈希数据分区策略就变为了SubTask(key)=hash(key)%3,由于数据分区策略的计算公式变化了,因此每一个key的数据要发往的SubTask也会发生改变。假设这时key为商品3的数据会被发送到KeyBy\Map[0]中,那么商品3的累计销售额状态数据必然要被重分布到KeyBy\Map[0]中,如图所示。

虽然键值状态的重分布策略能够降低用户的开发成本,但是这种重分布策略却对键值状态重分布的性能提出了巨大的挑战。如图6-28所示,当算子并行度为2时,每个SubTask在执行快照时会将本地的状态数据顺序地写入到远程分布式文件系统中,SubTask0和SubTask1分别写入文件1和文件2。当算子并行度变为3后,根据新的Hash分区策略计算,key为商品0、商品3、商品6和商品9的数据要被恢复到SubTask0中,那么SubTask0就要同时读取文件1和文件2,SubTask1和SubTask2的恢复过程也相同,都分别需要从文件1和文件2中恢复一部分key的状态数据。这时我们发现如果要让每个SubTask都完整且正确的恢复状态数据,就需要让每个SubTask都从分布式文件系统中读取到所有的快照文件,然后再过滤出属于当前SubTask的key的状态数据,但是按照这样的流程执行,就会出现以下两个问题。
- 状态恢复时的性能问题:在算子以新的并行度启动并从快照恢复时,算子的每个SubTask都会读取大量不属于当前SubTask的key的状态数据,同时还需要从中筛选出属于当前SubTask的状态数据,而这会导致SubTask的启动过程耗费大量的时间,作业的恢复过程很漫长。举例来说,如果算子的并行度为500,每一个SubTask中都有100万个key的状态数据,那么整个作业总计会有5亿个key,这时如果我们将算子并行度扩展为1000,那么对这1000个SubTask来说,每一个SubTask都要读取到这5亿个key的快照文件,然后再过滤出属于自己的key的状态数据,但是平均下来每个SubTask最终只会保留50万个key的状态数据,其余的4.995亿个key的数据都会被过滤。
- 分布式文件系统的稳定性问题:在算子从快照时,所有的SubTask都会对分布式文件系统发起大量读取相同文件的请求,这对分布式文件系统稳定性也会造成影响,并且随着算子并行度的增大,这种情况会越来越严重。
综上所述,使用该方案来恢复状态数据时,性能是无法达到预期的。其低效的原因就在于从状态恢复时,SubTask不知道分布式文件系统中的每一份快照文件中存储了哪些key的状态数据,也不知道这些key的状态数据在快照文件中的偏移量,所以只能全量读取后再按照key一个一个的进行过滤。
这里插一句,在20240125 此时此刻,flink计划做的2.0中最核心的一块就是状态的存算分离,解决的就是大状态的性能场景问题,与这里引出的状态重分配导致的问题,本质上是一个情况,所以这个问题正常情况来说,flink2.0上线以后,可以解决。
9.Flink State TTL 是怎么做到数据过期的?首先我们来想想,要做到 TTL 的话,要具备什么条件呢?
想想 Redis 的 TTL 设置,如果我们要设置 TTL 则必然需要给一条数据给一个时间戳,只有这样才能判断这条数据是否过期了。
在 Flink 中设置 State TTL,就会有这样一个时间戳,具体实现时,Flink 会把时间戳字段和具体数据字段存储作为同级存储到 State 中。
举个例子,我要将一个 String 存储到 State 中时:
- ⭐ 没有设置 State TTL 时,则直接将 String 存储在 State 中
- ⭐ 如果设置 State TTL 时,则 Flink 会将
接下来以 FileSystem 状态后端下的 MapState 作为案例来说:
⭐ 如果没有设置 State TTL,则生产的 MapState 的字段类型如下(可以看到生成的就是 HeapMapState 实例):

⭐ 如果设置了 State TTL,则生成的 MapState 的字段类型如下(可以看到使用到了装饰器的设计模式生成是 TtlMapState):

注意:
任务设置了 State TTL 和不设置 State TTL 的状态是不兼容的。这里大家在使用时一定要注意。防止出现任务从 Checkpoint 恢复不了的情况。但是你可以去修改 TTL 时长,因为修改时长并不会改变 State 存储结构。注意:
存活时长的计时器可以在数据被读、写时重置;
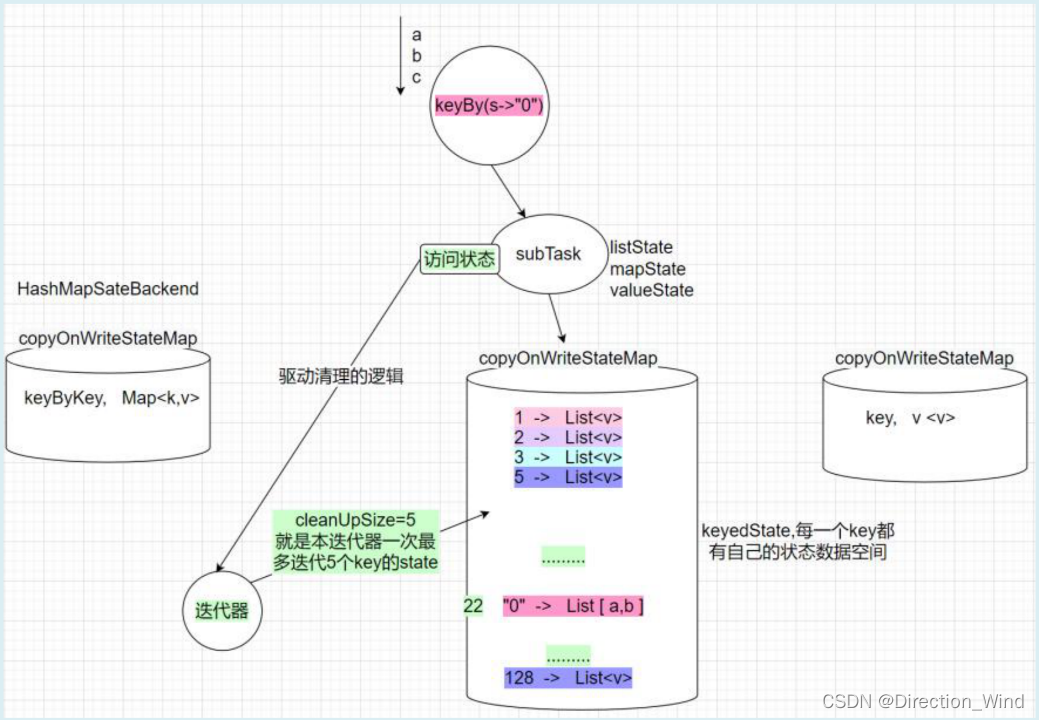
Ttl 存活管理粒度是到元素级的(如 liststate 中的每个元素,mapstate 中的每个 entry)cleanupStrategies(过期数据清理策略,目前支持的策略有)
-
cleanupIncrementally : 增量清除 每当访问状态时,都会驱动一次过期检查(算子注册了很多 key 的 state,一次检查只针对其中一部分: 由参数 cleanupSize 决定) 算子持有一个包含所有 key 的迭代器,每次检查后,迭代器都会向前 advance 指定的 key 数量; 本策略,针对“本地状态空间”,且只用于 HashMapStateBackend
-
cleanupFullSnapshot
在进行全量快照(checkpoint)时,清理掉过期数据; 注意:只是在生成的 checkpoint 数据中不包含过期数据;在本地状态空间中,并没有做清理; 本策略,针对“快照”生效 -
cleanupInRocksdbCompactFilter 只针对 rocksdbStateBackend 有效; 它是利用 rocksdb 的 compact 功能,在 rocksdb 进行 compact 时,清除掉过期数据; 本策略,针对“本地状态空间”,且只用于 EmbeddedRocksDbStateBackend
10.Flink SQL API State TTL 的过期机制是 onCreateAndUpdate 还是onReadAndWrite
⭐ 结论:Flink SQL API State TTL 的过期机制目前只支持 onCreateAndUpdate,DataStream API 两个都支持

⭐ 剖析:- onCreateAndUpdate:是在创建 State 和更新 State 时【更新 State TTL】
- onReadAndWrite:是在访问 State 和写入 State 时【更新 State TTL】
⭐ 实际踩坑场景:Flink SQL Deduplicate 写法,row_number partition by user_id order by proctime asc,此 SQL 最后生成的算子只会在第一条数据来的时候更新 state,后续访问不会更新 state TTL,因此 state 会在用户设置的 state TTL 时间之后过期。
5.operator-state 和 keyed-state 两者的区别?最大并行度又和它们有什么关系?举个生产环境中经常出现的案例,当用户停止任务、更新代码逻辑并且改变任务并发度时,两种 state 都是怎样进行恢复的?
⭐ 总结如下:
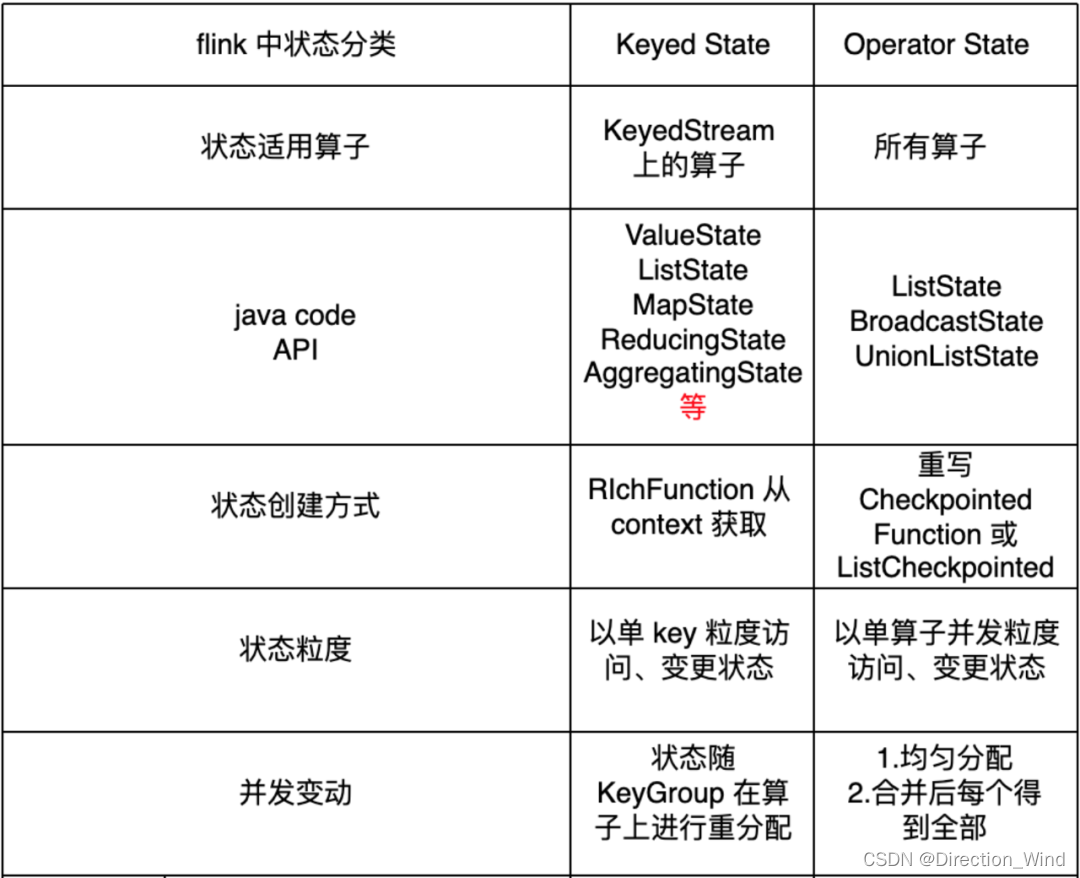
⭐ operator-state:

-
⭐ 状态适用算子:所有算子都可以使用 operator-state,没有限制。
-
⭐ 状态的创建方式:如果需要使用 operator-state,需要实现 CheckpointedFunction 或 ListCheckpointed 接口
-
⭐ DataStream API 中,operator-state 提供了 ListState、BroadcastState、UnionListState 3 种用户接口
-
⭐ 状态的存储粒度:以单算子单并行度粒度访问、更新状态
-
⭐ 并行度变化时:a. ListState:均匀划分到算子的每个 sub-task 上,比如 Flink Kafka Source 中就使用了 ListState 存储消费 Kafka 的 offset,其 rescale 如下图

-
BroadcastState:每个 sub-task 的广播状态都一样 c. UnionListState:将原来所有元素合并,合并后的数据每个算子都有一份全量状态数据
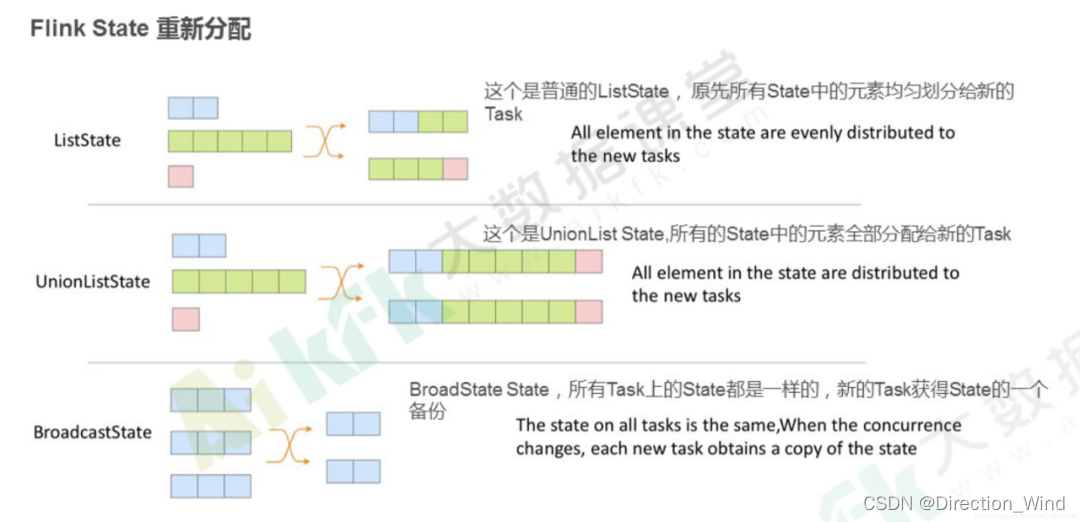
⭐ keyed-state:

- ⭐ 状态适用算子:keyed-stream 后的算子使用。注意这里很多同学会犯一个错误,就是大家会认为 keyby 后面跟的所有算子都使用的是 keyed-state,但这是错误的 ❌,比如有 keyby.process.flatmap,其中 flatmap 中使用状态的话是 operator-state
- ⭐ 状态的创建方式:从 context 接口获取具体的 keyed-state
- ⭐ DataStream API 中,keyed-state 提供了 ValueState、MapState、ListState 等用户接口,其中最常用 ValueState、MapState
- ⭐ 状态的存储粒度:以单 key 粒度访问、更新状态。举例,当我们使用 keyby.process,在 process 中处理逻辑时,其实每一次 process 的处理 context 都会对应到一个 key,所以在 process 中的处理都是以 key 为粒度的。这里很多同学会犯一个错 ❌,比如想在 open 方法中访问、更新 state,这是不行的,因为 open 方法在执行时,还没有到正式的数据处理环节,上下文中是没有 key 的。
- ⭐ 并行度变化时:keyed-state 的重新划分是随着 key-group 进行的。其中 key-group 的个数就是最大并发度的个数。其中一个 key-group 处理一段区间 key 的数据,不同 key-group 处理的 key 是完全不同的。当任务并行度变化时,会将 key-group 重新划分到算子不同的 sub-task 上,任务启动后,任务数据在做 keyby 进行数据 shuffle 时,依然能够按照当前数据的 key 发到下游能够处理这个 key 的 key-group 中进行处理,如下图所示。注意:最大并行度和 key-group 的个数绑定,所以如果想恢复任务 state,最大并行度是不能修改的。大家需要提前预估最大并行度个数。

11.ValueState 和 MapState 各自适合的应用场景?
- ⭐ ValueState
- 应用场景:简单的一个变量存储,比如 Long\String 等。如果状态后端为 RocksDB,极其不建议在 ValueState 中存储一个大 Map,这种场景下序列化和反序列化的成本非常高,这种常见适合使用 MapState。其实这种场景也是很多小伙伴一开始使用 State 的误用之痛,一定要避免。
- TTL:针对整个 Value 起作用
- ⭐ MapState
- 应用场景:和 Map 使用方式一样一样的
- TTL:针对 Map 的 key 生效,每个 key 一个 TTL
-
相关阅读:
【算法优选】 前缀和专题——贰
搭建网课查题公众号教程 内含接口
leetcode刷题(126)——1289. 下降路径最小和 II
Impala时间转换to_date、to_timestamp
Complete Probability Spaces
AMBA协议—AHB协议
sed编辑器
Fe3+-多巴胺修饰Pluronic的多功能性水凝胶/多巴胺修饰聚丙烯微孔膜表面的研究
【网络编程】模仿Wireshark制作的抓包程序
实例删除后volume仍然为in-use解决方法
- 原文地址:https://blog.csdn.net/Direction_Wind/article/details/136185889