数据的预处理是数据分析,或者机器学习训练前的重要步骤。
通过数据预处理,可以
- 提高数据质量,处理数据的缺失值、异常值和重复值等问题,增加数据的准确性和可靠性
- 整合不同数据,数据的来源和结构可能多种多样,分析和训练前要整合成一个数据集
- 提高数据性能,对数据的值进行变换,规约等(比如无量纲化),让算法更加高效
本篇介绍的标准化处理,可以消除数据之间的差异,使不同特征的数据具有相同的尺度,
以便于后续的数据分析和建模。
1. 原理
数据标准化的过程如下:
- 计算数据列的算术平均值(
mean) - 计算数据列的标准差(
sd) - 标准化处理:\(new\_data = (data - mean) / sd\)
data 是原始数据,new_data 是标准化之后的数据。
根据原理,实现的对一维数据标准化的示例如下:
import numpy as np
# 标准化的实现原理
data = np.array([1, 2, 3, 4, 5])
mean = np.mean(data) # 平均值
sd = np.std(data) # 标准差
# 标准化
data_new = (data-mean)/sd
print("处理前: {}".format(data))
print("处理后: {}".format(data_new))
# 运行结果
处理前: [1 2 3 4 5]
处理后: [-1.41421356 -0.70710678 0. 0.70710678 1.41421356]
使用scikit-learn库中的标准化函数scale,得到的结果也和上面一样。
from sklearn import preprocessing as pp
data = np.array([1, 2, 3, 4, 5])
pp.scale(data)
# 运行结果
array([-1.41421356, -0.70710678, 0. , 0.70710678, 1.41421356])
scikit-learn库中的标准化函数scale不仅可以处理一维的数据,也可以处理多维的数据。
2. 作用
标准化处理的作用主要有:
2.1. 消除数据量级的影响
数据分析时,不一样量级的数据放在一起分析会增加很多不必要的麻烦,比如下面三组数据:
data_min = np.array([0.001, 0.002, 0.003, 0.004, 0.005])
data = np.array([1, 2, 3, 4, 5])
data_max = np.array([10000, 20000, 30000, 40000, 50000])
三组数据看似差距很大,但是标准化处理之后:
from sklearn import preprocessing as pp
print("data_min 标准化:{}".format(pp.scale(data_min)))
print("data 标准化:{}".format(pp.scale(data)))
print("data_max 标准化:{}".format(pp.scale(data_max)))
# 运行结果
data_min 标准化:[-1.41421356 -0.70710678 0. 0.70710678 1.41421356]
data 标准化:[-1.41421356 -0.70710678 0. 0.70710678 1.41421356]
data_max 标准化:[-1.41421356 -0.70710678 0. 0.70710678 1.41421356]
标准化处理之后,发现三组数据其实是一样的。
将数据转化为相同的尺度,使得不同变量之间的比较更加方便和有意义,避免对分析结果产生误导。
2.2. 增强可视化效果
此外,标准化之后的数据可视化效果也会更好。
比如下面一个对比学生们数学和英语成绩的折线图:
math_scores = np.random.randint(0, 150, 10)
english_scores = np.random.randint(0, 100, 10)
fig, ax = plt.subplots(2, 1)
fig.subplots_adjust(hspace=0.4)
ax[0].plot(range(1, 11), math_scores, label="math")
ax[0].plot(range(1, 11), english_scores, label="english")
ax[0].set_ylim(0, 150)
ax[0].set_title("标准化之前")
ax[0].legend()
ax[1].plot(range(1, 11), pp.scale(math_scores), label="math")
ax[1].plot(range(1, 11), pp.scale(english_scores), label="english")
ax[1].set_title("标准化之后")
ax[1].legend()
plt.show()
随机生成10个数学和英语的成绩,数学成绩的范围是0~150,英语成绩的范围是0~100。
标准化前后的折线图对比如下: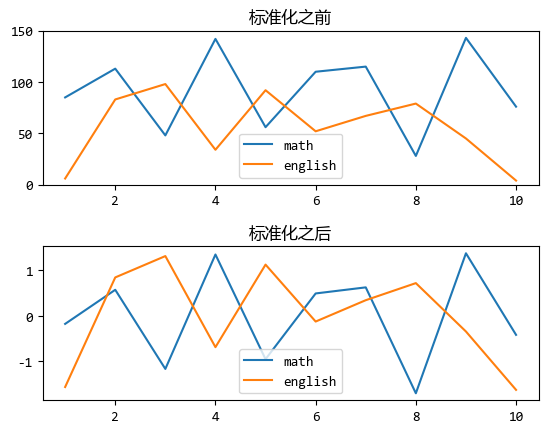
标准化之前的对比,似乎数学成绩要比英语成绩好。
而从标准化之后的曲线图来看,其实两门成绩是差不多的。
这就是标准化的作用,使得可视化结果更加准确和有意义。
2.3. 机器学习的需要
许多机器学习算法对输入数据的规模和量纲非常敏感。
如果输入数据的特征之间存在数量级差异,可能会影响算法的准确性和性能。
标准化处理可以将所有特征的数据转化为相同的尺度,从而避免这种情况的发生,提高算法的准确性和性能。
3. 总结
总的来说,数据标准化处理是数据处理中不可或缺的一步,它可以帮助我们消除数据之间的差异,提高分析结果的性能和稳定性,增加数据的可解释性,从而提高我们的决策能力。