代码
原文地址
预备知识:
1.什么是对比学习?
对比学习是一种机器学习范例,将未标记的数据点相互并列,以教导模型哪些点相似,哪些点不同。 也就是说,顾名思义,样本相互对比,属于同一分布的样本在嵌入空间中被推向彼此。 相比之下,属于不同分布的那些则相互拉扯。
摘要
神经模型在关系抽取(RE)的基准任务上表现出色。但是,我们还不清楚文本中哪些信息对现有的RE模型的决策有影响,以及如何进一步提升这些模型的性能。为了解决这个问题,本文实证地分析了文本中两个主要的信息源:文本上下文和实体提及(名称)对RE的作用。本文发现,虽然上下文是预测的主要依据,但RE模型也高度依赖于实体提及中的信息,其中大多数是类型信息;以及现有的数据集可能通过实体提及暴露了一些浅层的启发式规则,从而使RE基准任务上的性能看起来很高。基于这些分析,本文提出了一种基于实体掩码对比预训练的框架,用于RE,旨在在避免对实体的死记硬背或对提及中的表面线索的利用的同时,对文本上下文和类型信息有更深入的理解。本文进行了大量的实验来支持本文的观点,并证明该框架可以在不同的RE场景下提高神经模型的有效性和鲁棒性。
1 Introduction

通常,在典型的RE设置中,文本中有两个主要的信息来源,可能会对RE模型的关系分类有帮助:那就是文本上下文和实体提及(名称)。
文本上下文中存在一些能够表达关系事实的可解释模式。比如,在图1中,“... be founded ... by ...”就是一个能够表示 founded by 关系的模式。早期的RE系统把这些模式形式化成字符串模板,然后通过匹配模板来识别关系。后来的神经模型则更倾向于把这些模式编码成分布式表示,再通过比较表示来预测关系。相比于刚性的字符串模板,神经模型使用的分布式表示具有更好的泛化能力,也有更高的性能。
实体提及对于关系分类也有很多信息价值。如图1所示,可以从实体提及中获得实体的类型信息,这可以帮忙排除一些不符合逻辑的关系。另外,如果这些实体能够和知识图谱(KGs)建立链接,模型就可以利用知识图谱中的外部知识来辅助RE(Zhang等人, 2019; Peters等人, 2019)。此外,对于近期广泛使用的RE模型中的预训练语言模型,它们在预训练过程中可能已经隐含地学习了一些实体相关的知识(Petroni等人, 2019)。
本文通过大量的实验来研究RE模型依赖于两种信息源的程度。发现:
-
文本上下文和实体提及都是RE的关键因素。实验表明,上下文是支持分类的主要来源,而实体提及也提供了重要的信息,尤其是实体的类型信息。
-
现有的RE基准数据集可能通过实体提及泄露了一些浅层的线索,导致现有模型的高性能。实验显示,即使只给定实体提及作为输入,模型仍然可以达到高性能,这说明这些数据集中存在一些来自实体提及的有偏的统计线索。
基于以上的观察结果,本文提出了一种进一步改进RE模型的方法:应该通过更好地理解上下文和利用实体类型来增强模型的能力,同时防止模型简单地记忆实体或利用提及中的有偏线索。为此,本文探索了一种针对RE的实体掩码对比预训练框架,使用Wikidata来收集可能表达相同关系的句子,并让模型通过对比目标来学习哪些句子在关系语义上是接近的,哪些是不接近的。在这个过程中,随机地掩盖实体提及,以避免模型被它们所影响。在不同的设置和基准数据集上展示了这种预训练框架的有效性,本文认为更好的预训练技术是朝着更好的RE的可靠方向。
2 Pilot Experiment and Analysis
2.1 Models and Dataset
本文选取以下三个模型进行实验分析:
-
CNN:本文采用了Nguyen和Grishman (2015)提出的 卷积神经网络 ,并参考了Zhang等人(2017)的做法,用词性、命名实体识别和位置嵌入来丰富输入。
-
BERT:本文遵循 Baldini Soares等人(2019)的方法,使用BERT进行RE,用特殊的标记来突显句子中的实体提及,并用实体表示的拼接来进行分类。
-
Matching the blanks (MTB): MTB (Baldini Soares等人,2019)是一个基于BERT的面向RE的预训练模型。它通过对两个句子是否提及相同的实体对进行分类来进行预训练,其中实体提及被随机地 遮盖 。它和BERT一样,用相同的方式进行RE的微调。由于它没有公开发布,本文自行预训练了一个
 版本的MTB,并在附录A中给出了细节。
版本的MTB,并在附录A中给出了细节。
本文使用的基准数据集是 TACRED, 它是一个有监督的RE数据集,具有106,264个实例和42个关系,它还为每个实体提供类型注释。
2.2 Experimental Settings
本文使用不同的输入格式来进行RE,以便在可控的实验中观察上下文和实体提及的影响。前两种格式是以前的文献采用的,也比较接近真实的RE场景:
-
上下文+提及(C+M):这是最常用的RE设置,其中提供了整个句子(包括上下文和突出显示的实体提及)。为了让模型知道实体提及的位置,本文对CNN模型使用位置嵌入(Zeng et al., 2014),对预训练的BERT使用特殊的实体标记。
-
上下文+类型(C+T):本文用TACRED提供的类型替换实体提及。使用特殊的标记来表示它们:例如,使用[person]和[date]来分别表示类型为person和date的实体。不同于Zhang et al. (2017),本文不会重复特殊标记来匹配实体的长度,以避免泄露实体长度信息。
-
仅上下文(OnlyC):为了分析文本上下文对RE的贡献,本文用特殊的标记[SUBJ]和[OBJ]替换所有的实体提及。在这种情况下,实体提及的信息源完全被阻断。
-
仅提及(OnlyM):在这种设置下,本文只提供实体提及,丢弃所有其他的文本上下文作为输入。
-
仅类型(OnlyT):这与仅提及类似,只不过本文只提供实体类型。
2.3 Result Analysis

表1展示了不同的输入格式和模型在TACRED上的关系分类性能的详细比较。从结果中可以得出以下结论:
-
文本上下文和实体提及都是关系分类的关键信息源,而实体提及中最重要的信息是它们的类型。如表1所示,OnlyC,OnlyM和OnlyT相比于C+M和C+T都有显著的性能损失,说明单一的信息源是不足以支持正确的预测的,上下文和实体提及都是必不可少的。此外,还可以发现C+T在TACRED上与C+M在BERT和MTB上达到了相近的效果。这表明实体提及中的大部分有用信息是它们的类型信息。
-
在现有的RE数据集中,实体提及存在一些表面的线索,这可能导致RE模型的过高的性能。在TACRED上发现OnlyM在所有三个模型上都有很高的性能,这种现象在其他数据集中也有体现(见表5)。本文还对OnlyC相比于C+M的性能降低进行了深入的分析,在第2.4节中发现,在一些模型难以理解上下文的情况下,它们会倾向于利用实体提及的浅层启发。这促使本文进一步改进模型在从上下文中提取关系的能力,同时避免它们对实体提及的死记硬背。
可以注意到CNN的结果与BERT和MTB有一些不一致:CNN在OnlyC上的性能几乎与OnlyM相同,而C+M比C+T低5%。本文认为这主要是因为CNN的编码能力较弱,不能充分利用上下文的信息,而且更容易对数据集中实体提及的浅层线索产生过拟合。
2.4 Case Study on TACRED

为了进一步了解不同输入格式对性能的影响,本文对TACRED数据集进行了详细的案例研究,选择了BERT作为示例,因为BERT代表了当前最先进的模型类别,而且在MTB数据集上也观察到了类似的结果。
首先,本文比较了C+M和C+T两种输入格式,发现C+M和C+T有95.7%的正确预测是一致的,而C+M的68.1%的错误预测也和C+T相同。这表明模型从实体提及中获取的大部分信息是它们的类型信息。本文还在表2中列出了一些C+M和C+T的不同错误。C+M可能受到训练集中实体分布的影响。在表2中的两个例子中,“Washington”只出现在per:stateorprovince of residence这个关系中,“Bank of America Corp.”只出现在no relation这个关系中,这种偏见可能导致模型的错误。另一方面,C+T可能在缺少具体实体提及的情况下,难以正确理解文本。如例子所示,用类型替换提及后,模型被“general assembly”误导了,无法检测出“Ruben”和“Ruben van Assouw”之间的关系。这表明实体提及除了类型之外,还提供了其他信息来帮助模型理解文本。
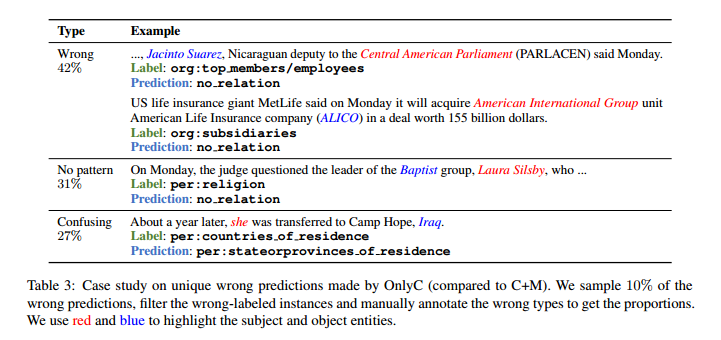
本文还研究了为什么OnlyC相比于C+M有如此明显的性能下降。在表3中,将OnlyC(相比于C+M)的所有独有错误预测分为三类。“Wrong”表示句子中有明显的关系模式,但被模型误解了。“No pattern”意味着在掩盖实体提及后,即使是人类也很难判断是什么关系。“Confusing”表示在掩盖实体后,句子变得模糊不清(例如,混淆城市和国家)。如表3所示,在OnlyC的独有错误预测中,有近一半(42%)的句子有明确的关系模式,但模型无法识别出来,这表明在C+M中,模型可能依赖于实体提及的浅层启发来正确预测句子。在其余的情况下,实体提及确实提供了分类的关键信息。
3 Contrastive Pre-training for RE
3.1 Relational Contrastive Example Generation

为了提高RE的效果,本文模型在预训练阶段就专注于从文本中学习关系和实体的表示。本文采用了对比学习的方法,通过让“邻居”之间的表示更相似,而让“非邻居”之间的表示更不同。在这里,“邻居”是指在知识图谱(KGs)中具有相同关系实体对的句子,而“非邻居”是指没有相同关系实体对的句子。
这里的知识图谱(KG)是由一些关系事实构成的。从中随机选择两个句子 和
和 ,它们各自包含了两个实体
,它们各自包含了两个实体 和
和 。如果有一个关系
。如果有一个关系 ,使得
,使得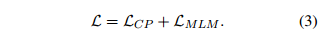 和
和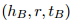 都在KG里,就把和称为“邻居”。本文用Wikidata作为KG,因为它和用来预训练的Wikipedia语料库很容易对应起来。在训练过程中,先按照KG里的关系分布来采样一个关系
都在KG里,就把和称为“邻居”。本文用Wikidata作为KG,因为它和用来预训练的Wikipedia语料库很容易对应起来。在训练过程中,先按照KG里的关系分布来采样一个关系 ,然后再采样一个和有关的句子对
,然后再采样一个和有关的句子对 。为了做对比学习,还要随机采样
。为了做对比学习,还要随机采样 个句子
个句子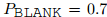
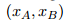 ,让它们和组成个负样本对。模型的任务是在所有正负样本中,找出和有相同关系的那个句子。
,让它们和组成个负样本对。模型的任务是在所有正负样本中,找出和有相同关系的那个句子。
和,它们各自包含了两个实体和。如果有一个关系,使得和都在KG里,就把和称为“邻居”。本文用Wikidata作为KG,因为它和用来预训练的Wikipedia语料库很容易对应起来。在训练过程中,先按照KG里的关系分布来采样一个关系,然后再采样一个和有关的句子对。为了做对比学习,还要随机采样个句子,让它们和组成个负样本对。模型的任务是在所有正负样本中,找出和有相同关系的那个句子。为了防止在预训练时过度依赖实体提及或仅提取它们的表面特征,本文用特殊符号 [BLANK] 随机替换了一些实体提及。用  表示替换的实体比例,并参考 Baldini Soares 等人 (2019) 的方法设置。注意,预训练时完全遮盖所有实体提及也不合适,因为这会导致预训练和微调之间的不一致,也会使预训练模型无法利用实体提及的信息(比如,学习实体类型)。
表示替换的实体比例,并参考 Baldini Soares 等人 (2019) 的方法设置。注意,预训练时完全遮盖所有实体提及也不合适,因为这会导致预训练和微调之间的不一致,也会使预训练模型无法利用实体提及的信息(比如,学习实体类型)。
表示替换的实体比例,并参考 Baldini Soares 等人 (2019) 的方法设置。注意,预训练时完全遮盖所有实体提及也不合适,因为这会导致预训练和微调之间的不一致,也会使预训练模型无法利用实体提及的信息(比如,学习实体类型)。用一个例子来说明数据生成过程:在图 2 中,有两个句子“SpaceX was founded in 2002 by Elon Musk”和“As the co-founder of Microsoft, Bill Gates ...””,其中 (SpaceX, founded by, Elon Musk) 和 (Microsoft, founded by, Bill Gates) 都是KG中的关系。本文希望这两个句子能够有相似的表示,体现出 founded by 这个关系。而对于图中右边的另外两个句子,由于它们的实体对之间没有 founded by 这个关系,它们被认为是负样本,应该与左边的句子有不同的表示。在预训练时,每个实体提及都有的概率被替换为 [BLANK]。
的概率被替换为 [BLANK]。句子中可能没有明确地表达出实体之间的关系,或者表达出的关系与期望的不一致。比如,一个句子提到了“SpaceX”和“Elon Musk”,它们之间可能有 founded by、CEO 或 CTO 等关系,也可能没有任何关系。例如,“Elon Musk answers reporters’questions on a SpaceX press conference”这个句子就没有体现出两者之间的关系。但是,本文认为这种噪声对本文的预训练框架的影响不大:本文的目的是相比于原始的预训练模型,如 BERT,得到更适合RE的表示,而不是直接用于下游任务的关系抽取模型,所以可以容忍数据中的一些噪声。
本文的模型利用生成的关系对比例子,提高了从提及中获取类型信息和从文本上下文中理解关系语义的能力。
(1)模型通过对比两个涉及不同实体对但关系相同的句子,来识别实体提及之间的关系信息。 同时,使用实体掩码策略,避免了对实体的简单记忆,而是更多地关注实体类型信息。
(2)通过学习一组表达相同关系的不同文本上下文,提取出关系的多样化表达模式。MTB采用了更严格的规则,只采样了两个包含相同实体对的句子。这种方法虽然可以减少噪声,但也限制了数据的多样性,影响了模型学习类型信息的能力。
3.2 Training Objectives
本文的对比式预训练使用了与 BERT相同的 Transformer 架构。用 ENC 表示 Transformer 编码器,用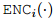 表示第 i 个位置的输出。对于输入格式,参考了 Baldini Soares等人(2019) 的方法,用特殊的标记来突出实体提及。例如,对于句子“SpaceX was founded by Elon Musk.”,输入序列是““[CLS][E1] SpaceX [/E1] was founded by [E2] Elon Musk [/E2] . [SEP]”。
表示第 i 个位置的输出。对于输入格式,参考了 Baldini Soares等人(2019) 的方法,用特殊的标记来突出实体提及。例如,对于句子“SpaceX was founded by Elon Musk.”,输入序列是““[CLS][E1] SpaceX [/E1] was founded by [E2] Elon Musk [/E2] . [SEP]”。
表示第 i 个位置的输出。对于输入格式,参考了 Baldini Soares等人(2019) 的方法,用特殊的标记来突出实体提及。例如,对于句子“SpaceX was founded by Elon Musk.”,输入序列是““[CLS][E1] SpaceX [/E1] was founded by [E2] Elon Musk [/E2] . [SEP]”。在预训练过程中,有两个目标:对比式预训练目标和遮蔽语言建模目标。
对比式预训练目标
如图 2 所示,给定正样本句子对和负样本句子对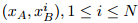 ,首先用 Transformer 编码器得到
,首先用 Transformer 编码器得到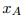 在
在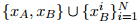 中的关系感知表示:
中的关系感知表示:
和负样本句子对,首先用 Transformer 编码器得到在中的关系感知表示: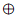
其中 和是特殊标记 [E1] 和 [E2] 的位置,表示拼接。有了句子表示,就有了以下的训练目标:
和是特殊标记 [E1] 和 [E2] 的位置,表示拼接。有了句子表示,就有了以下的训练目标:
和是特殊标记 [E1] 和 [E2] 的位置,表示拼接。有了句子表示,就有了以下的训练目标: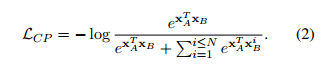
通过优化模型使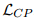 最小化,本文期望 和
最小化,本文期望 和  的表示更加接近,最终具有相似关系的句子会有相似的表示。
的表示更加接近,最终具有相似关系的句子会有相似的表示。
最小化,本文期望 和 的表示更加接近,最终具有相似关系的句子会有相似的表示。遮蔽语言建模目标
为了保持从 BERT 继承的语言理解能力,并避免灾难性遗忘,本文也采用了 BERT 的遮蔽语言建模 (MLM) 目标。MLM 随机地遮蔽输入中的一些词,然后让模型预测被遮蔽的词,从而学习包含丰富语义和句法知识的上下文表示。用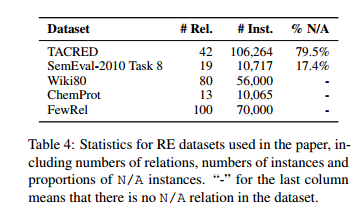 表示 MLM 的损失函数。
表示 MLM 的损失函数。
表示 MLM 的损失函数。最终,有以下的训练损失:
4 Experiment
4.1 RE Tasks
Supervised RE
这是RE中最广泛采用的设置,其中有一个预定义的关系集合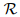 ,数据集中的每个句子
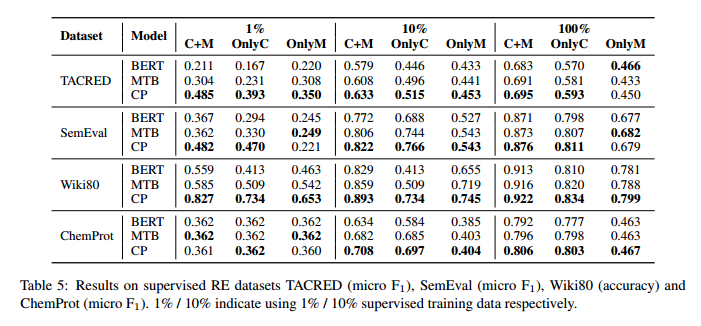
,数据集中的每个句子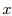 都表达了中的某个关系。在一些基准测试中,有一种特殊的关系叫做或,表示句子中没有表达给定实体之间的任何关系,或者它们的关系不包含在中。对于有监督的 RE 数据集,本文使用 TACRED,SemEval-2010 Task 8 ,Wiki80和 ChemProt 。表 4 显示了数据集之间的比较。本文还添加了 1% 和 10% 的设置,意味着只使用训练集的 1% / 10% 的数据。这是为了模拟低资源的情况,并观察模型性能在不同的数据集和设置下的变化。注意,ChemProt 只有 4169 个训练实例,这导致了表 5 中 1% ChemProt 的异常结果。在附录 B 中给出了这个问题的详细说明。
都表达了中的某个关系。在一些基准测试中,有一种特殊的关系叫做或,表示句子中没有表达给定实体之间的任何关系,或者它们的关系不包含在中。对于有监督的 RE 数据集,本文使用 TACRED,SemEval-2010 Task 8 ,Wiki80和 ChemProt 。表 4 显示了数据集之间的比较。本文还添加了 1% 和 10% 的设置,意味着只使用训练集的 1% / 10% 的数据。这是为了模拟低资源的情况,并观察模型性能在不同的数据集和设置下的变化。注意,ChemProt 只有 4169 个训练实例,这导致了表 5 中 1% ChemProt 的异常结果。在附录 B 中给出了这个问题的详细说明。
,数据集中的每个句子都表达了中的某个关系。在一些基准测试中,有一种特殊的关系叫做或,表示句子中没有表达给定实体之间的任何关系,或者它们的关系不包含在中。对于有监督的 RE 数据集,本文使用 TACRED,SemEval-2010 Task 8 ,Wiki80和 ChemProt 。表 4 显示了数据集之间的比较。本文还添加了 1% 和 10% 的设置,意味着只使用训练集的 1% / 10% 的数据。这是为了模拟低资源的情况,并观察模型性能在不同的数据集和设置下的变化。注意,ChemProt 只有 4169 个训练实例,这导致了表 5 中 1% ChemProt 的异常结果。在附录 B 中给出了这个问题的详细说明。Few-Shot RE
少样本学习(Few-shot learning)是一个近期出现的研究主题,它探讨如何用少量的样本来训练一个模型,使其能够处理新的任务。少样本关系抽取(Few-shot RE)的一个典型设置是 N-way K-shot RE,其中在每个评估阶段,从 N 个关系类型中采样 K 个样本,以及一些查询样本(都属于 N 个关系中的一个),并要求模型根据给定的 N ×K 个样本来对查询样本进行分类。本文使用 FewRel 作为数据集,并在表 4 中列出了它的统计信息。使用原型网络(Prototypical Networks)作为模型,参考前 的方法,并做了一些改动:(1)使用第 3.2 节描述的表示方法,而不是使用 [CLS]。 (2)使用点积(dot production)而不是欧氏距离(Euclidean distance)来衡量样本之间的相似度。本文发现这种方法比原始原型网络有很大的提升。
4.2 RE Models
本文在 2.1 节介绍了 BERT 和 MTB 两种预训练模型,用于(RE。除此之外,本文还提出了一种新的对比预训练框架 (CP),并对其进行了评估。所有模型的预训练和微调过程的详细超参数设置,都写在了附录 A 和 B 中。值得注意的是,由于 MTB 和 CP 都使用了 Wikidata 作为预训练数据,而 Wiki80 和 FewRel 这两个数据集也是基于 Wikidata 构建的,所以在预训练时排除了这两个数据集测试集中的所有实体对,以防止测试集泄露的问题。
4.3 Strength of Contrastive Pre-training
表 5 和 6 对 BERT、MTB 和本文对比预训练模型进行了详细的比较。无论是在不同的设置还是不同的数据集上,MTB 和 CP 都能显著提升模型的性能,体现了面向关系抽取的预训练的强大作用。相较于 MTB,CP 获得了更优的结果,证明了对比预训练框架的有效性。具体来说,本文发现:
(1) CP 在 C+M、OnlyC 和 OnlyM 这三种设置下都能提高模型的性能,说明本文的预训练框架能够同时增强模型对上下文的理解和对类型信息的抽取能力。
(2) CP 在 C+M 和 OnlyC 这两种设置下的性能提升是普遍的,即使是在来自生物医学领域的 ChemProt 和 FewRel 2.0 数据集上也是如此。其在维基百科上训练的模型在生物医学数据集上也有良好的表现,说明 CP 学习到了跨领域的关系模式。
(3) CP 在 OnlyM 这种设置下也有显著的改进,特别是在与维基百科密切相关的 TACRED、Wiki80 和 FewRel 1.0 数据集上。这表明本文的模型在从提及中抽取类型信息方面有更好的能力。上下文和提及的双重提升最终使得 CP 的关系抽取结果更好(更好的 C+M 结果)。
(4) 本文的对比预训练模型在低资源和少样本的设置下的性能提升更为明显。对于 C+M,观察到在 10-way 1-shot FewRel 1.0 上的提升为 7%,在 TACRED 的 1% 设置上的提升为 18%,在 Wiki80 的 1% 设置上的提升为 24%。OnlyC 和 OnlyM 也有类似的趋势。在低资源和少样本的设置下,由于训练数据的不足,模型更难从上下文中学习到关系模式,更容易过拟合于提及的表面线索。但是,通过对比预训练,本文的模型可以更好地利用文本上下文,同时避免被实体所影响,从而大幅度地超过了其他的基线模型。