-
稳定的音频来了 — 使用人工智能创作音乐(for free)
今天,以稳定扩散(Stable Diffusion)和StableLM等开源AI工具和模型而闻名的Stability AI公司推出了其首个音乐和声音生成AI产品——StableAudio。音乐产业以其难以打入而闻名。即使您拥有才华和动力,您仍然需要创作和制作音乐所需的技能和资源。但如果您一点都不需要这些呢?如果您只需拥有创造力和一个好的AI提示就能创作音乐呢?
StableAudio是一种可以从零开始生成音乐的AI工具。您只需要提供一些简单的指示,AI将完成其余工作。官方链接在这里:https://stableaudio.com/
什么是StableAudio?
StableAudio是一种独创性的AI工具,使用生成式AI技术来创作高质量的音乐和音效。要使用StableAudio,您只需提供一个描述性文本提示和所需的音频长度。例如,您可以输入“后摇、吉他、鼓组、贝斯、弦乐、欢愉、振奋、忧郁、流畅、原始、史诗、感伤、125 BPM”来生成一首95秒的后摇风格曲目。StableAudio非常适合希望在其音乐中创建样本的音乐人。您可以用它来创建音效、背景音乐,甚至是您自己的原创作品。
自己试一试
转到StableAudio仪表板并注册:
 StableAudio
StableAudio然后,转到“生成音乐”仪表板,开始生成您自己的音乐:
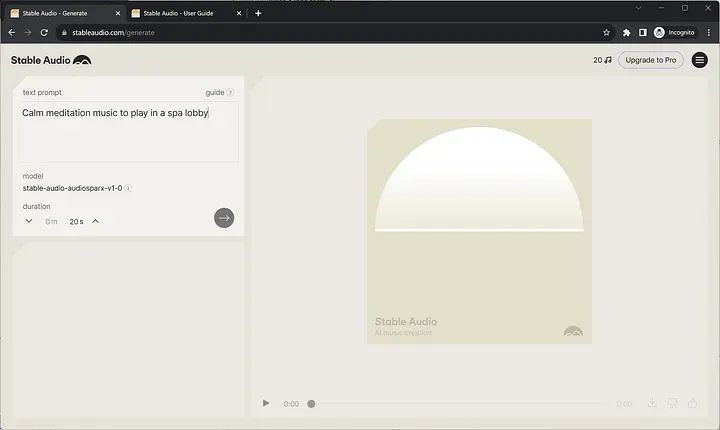 StableAudio
StableAudio输入您的提示并设置持续时间。请注意,免费订阅的音频最大长度为20秒。
点击右箭头按钮开始音频生成。
 StableAudio
StableAudio与此同时,您可以在StableAudio的“用户指南”部分中探索提供的示例:
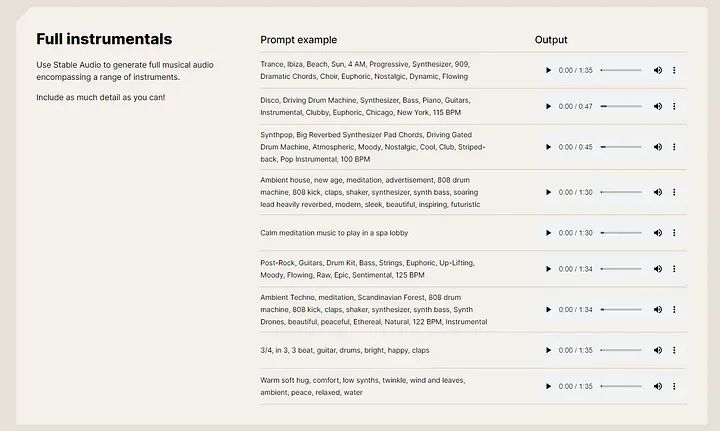 StableAudio
StableAudio它是如何工作的
以下是StableAudio工作的一些关键技术细节:
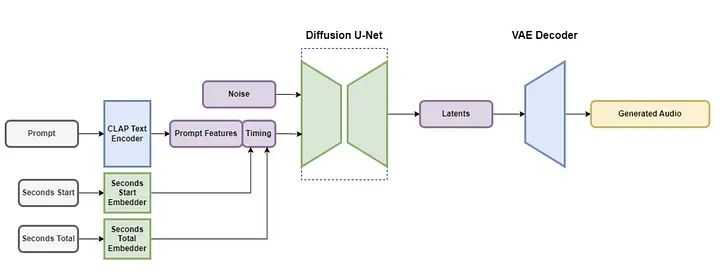 StableAudio技术背景
StableAudio技术背景VAE将立体声音频压缩成数据压缩、抗噪和可逆的有损潜在编码,使生成和训练比直接使用原始音频样本更快。
文本编码器用于从文本提示中提取特征。然后,使用这些特征来调节扩散模型。
扩散模型是一个基于U-Net的模型,使用残差层、自注意层和交叉注意层的组合来去噪输入并重构所需的音频。
另一个重要的信息是,StableAudio模型使用了超过800,000个音频文件的数据集,包括音乐、音效和单乐器音轨。这相当于超过19,500小时的音频。
最后的想法
总的来说,我对这个新的AI工具印象深刻。音频的质量与由人类专业人员创造的音频相媲美。StableAudio是一个改变游戏规则的工具,它可能会颠覆整个音乐和音效行业。
· END ·
HAPPY LIFE

本文仅供学习交流使用,如有侵权请联系作者删除
-
相关阅读:
SpringBoot2-mssql2008
基于openEuler虚拟机本地执行mugen测试脚本
离婚协议中的几个重点
交换机堆叠 配置(H3C)堆叠中一台故障如何替换
【String类的常用方法】
从 1.5 开始搭建一个微服务框架——日志追踪 traceId
selenium_webdriver自动化测试指南
以矩阵的形式,对点或线段或多边形绕固定点旋转方法
day02 springmvc
GitHub的下载超时问题
- 原文地址:https://blog.csdn.net/weixin_38739735/article/details/134680372