-
小土堆-pytorch-神经网络-搭建小实战和Sequential 09_笔记
sequential
Sequential 是 Keras 中的一种神经网络框架,可以被认为是一个容器,其中封装了神经网络的结构。Sequential 模型只有一组输入和一组输出。各层之间按照先后顺序进行堆叠。前面一层的输出就是后面一次的输入。通过不同层的堆叠,构建出神经网络。
实战实现目标:从inputs到outputs
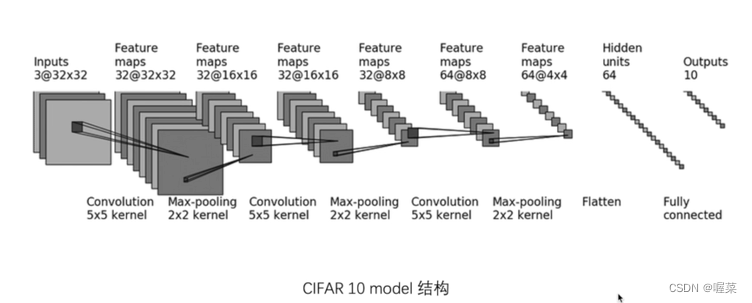
#bitch_size=64 想象成有64张图片不使用sequential创建网络,使用正常方法
import torch from torch import nn from torch.nn import Conv2d, MaxPool2d, Flatten, Linear class Tudui(nn.Module): def __init__(self): super(Tudui, self).__init__() self.conv1=Conv2d(3,32,5,padding=2) # padding是通过公式计算得来的 self.maxpool1=MaxPool2d(2) self.conv2=Conv2d(32,32,5,padding=2) self.maxpool2=MaxPool2d(2) self.conv3=Conv2d(32,64,5,padding=2) self.maxpool3=MaxPool2d(2) self.flatten=Flatten() self.linear1=Linear(1024,64) self.linear2=Linear(64,10) def forward(self,x): x=self.conv1(x) x=self.maxpool1(x) x=self.conv2(x) x=self.maxpool2(x) x=self.conv3(x) x=self.maxpool3(x) x=self.flatten(x) x=self.flatten(x) x=self.linear1(x) x=self.linear2(x) return x tudui =Tudui() print(tudui) input=torch.ones((64,3,32,32)) output=tudui(input) print(output.shape)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
运行结果截图:

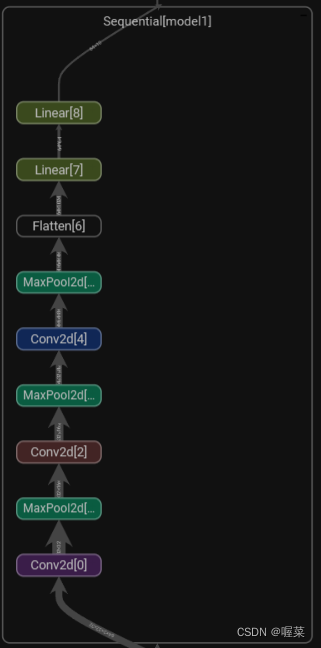
使用sequential简化代码
import torch from torch import nn from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential from torch.utils.tensorboard import SummaryWriter class Tudui(nn.Module): def __init__(self): super(Tudui, self).__init__() self.model1 = Sequential( Conv2d(3, 32, 5, padding=2), MaxPool2d(2), Conv2d(32, 32, 5, padding=2), MaxPool2d(2), Conv2d(32, 64, 5, padding=2), MaxPool2d(2), Flatten(), Linear(1024, 64), Linear(64, 10) ) def forward(self,x): x=self.model1(x) return x tudui =Tudui() print(tudui) input=torch.ones((64,3,32,32)) output=tudui(input) print(output.shape) # 增加可视化 writer=SummaryWriter("../logs_seq") writer.add_graph(tudui,input) writer.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
运行结果截图:
-
相关阅读:
Java-KoTime:接口耗时监测与邮件通知接口耗时情况
MFC 鼠标悬停提示框
1978-2021年全国各省有效灌溉面积数据
助力智慧交通,开发构建道路交通场景下智能车辆检测识别系统
《Java编程思想》读书笔记(五)
ren域名有价值吗?值不值得投资?ren域名的应用范围有哪些?
SystemC入门之测试平台编写完整示例:全加器
华为机试:敏感字段加密
认识并安装WSL
RTMP摄像头直播-CameraX数据采集处理
- 原文地址:https://blog.csdn.net/weixin_62613321/article/details/132611775
