-
PyTorch 之 Dataset 类入门学习
PyTorch 之 Dataset 类入门学习
Dataset 类简介
-
PyTorch中的Dataset类是一个抽象类,用来表示数据集。通过继承Dataset类可以进行自定义数据集的格式、大小和其它属性,供后续使用;

-
可以看到官方封装好的数据集也是直接或间接的继承自
Dataset类
自定义数据集逻辑
- 继承 Dataset 类;
- 重写 init():构造函数,可自定义数据读取方法以及进行数据预处理;
- 重写 len():返回数据集大小;
- 重写 getitem_():索引数据集中的某一个数据
代码实现
import torch from torch.utils.data import Dataset # 自定义数据集继承 pytorch 内置的 Dataset 类 class GreenDataset(Dataset): """ 重写构造函数 Args: data_tensor 数据或数据集合 target_tensor 数据标签或数据标签集合 """ def __init__(self, data_tensor, target_tensor): self.data_tensor = data_tensor self.target_tensor = target_tensor # 重写 len 方法: return 数据集大小 def __len__(self): return self.data_tensor.size(0) # 重写 getitem 方法:基于索引,return 对应的数据及其标签,组合成 1 个元组返回 def __getitem__(self, index): return self.data_tensor[index], self.target_tensor[index] def test_data_set(): """ 自定义数据集测试 """ # 生成数据集和标签集 (数据元素长度=标签元素长度) # 10 行 3 列数据,可以理解为 10 个元素,每个元素是一维的 3个元素列表 data_tensor = torch.randn(10, 3) # 对应方法 torch.randint(low, high, size)标签是 0 或 1 的 10 个元素 # low ( int , optional ) – 要从分布中提取的最小整数。默认值:0 # high ( int ) – 高于要从分布中提取的最高整数 # size ( tuple ) – 定义输出张量形状的元组 # 以下示例中 low 取默认值 0 target_tensor = torch.randint(2, (10,)) # 将数据封装成自定义数据集的 Dataset my_dataset = GreenDataset(data_tensor, target_tensor) # 调用方法:查看数据集大小 print('dataset size info:', len(my_dataset)) # 根据索引获取数据 print('tensor_data[0]: ', my_dataset[0]) # 打印数据集 for i, my_dataset in enumerate(my_dataset): print('索引值:%s 数据:%s' % (i, my_dataset)) if __name__ == '__main__': test_data_set()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
重点函数
-
torch.randn()

-
torch.randint()
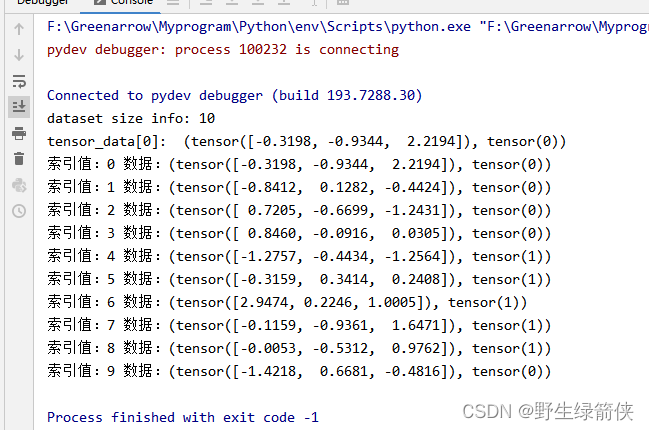
执行结果
-
-
相关阅读:
JAVA经典百题之求平均分
创品牌强农精品培育消费引领 国稻种芯百团计划行动发布
皕杰报表之语义层
[Linux] 如何查看内核 Kernel 版本(查多个Kernel的方法)
无法启动此程序,因为计算机中“找不到msvcp140.dll”的解决方法
JavaScript之事件
ctfshow-XXE(web373-web378)
S7-1200通过CM CANopen模块与KINCO伺服连接
golang开发:go并发的建议
Code For Better 谷歌开发者之声——盘点大家用过的Google 产品
- 原文地址:https://blog.csdn.net/Greenarrow961224/article/details/134524486
