-
【追求卓越01】数据结构--数组
引导
这一章节开始,正式进入数据结构与算法的学习过程中。由简到难,先开始学习最基础的数据结构--数组。
我相信对于数组,大家肯定是不陌生,因为数组在大多数的语言中都有,也是大家在编程中常常会接触到的。我不会说数组有多困难,但是它绝对不是像我们所想的那么简单而已。
带着问题进入今天的课题:为什么数组的下表从0开始,而不是从1开始?
什么是数组
我们还是从专业的角度来介绍一下数组:数组是一种线性表数据结构。它用一组连续的内存空间,来储存一组相同类型的数据。其中有几个知识点是需要我们了解的。
第一点是线性结构的概念。线性结构具有以下几个特点:
- 有唯一的首元素
- 有唯一的尾元素
- 除了首元素,所有的元素都有唯一的前驱
- 除了尾元素,所有的元素都有唯一的后继
- 数据元素之间存在“一对一”的关系
只要不满足以上特点的,就是非线性表。
常见的线性结构有:栈,数组,队列,堆,链表
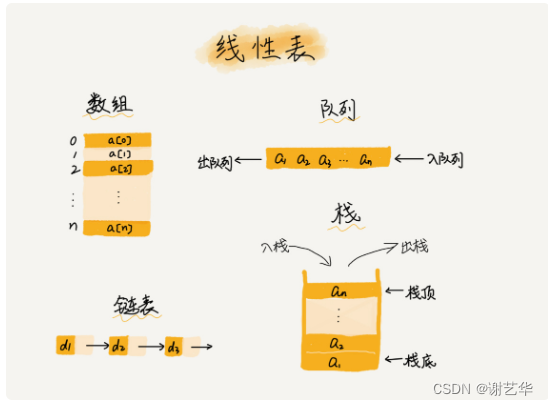
常见的非线性结构有:树,图

第二点是连续的内存空间和相同类型的数据结构。这两点正是数据数组强大的主要原因--高效的访问操作(随机访问)。我们知道数组在查询操作中具有很高的效率。但是原因是什么呢?我们一起来分析一下。
例: 我们定义一个int 类型的数组,长度为10。假设首地址是base_address是1000。,那么它在内存中的分布应该如下图:
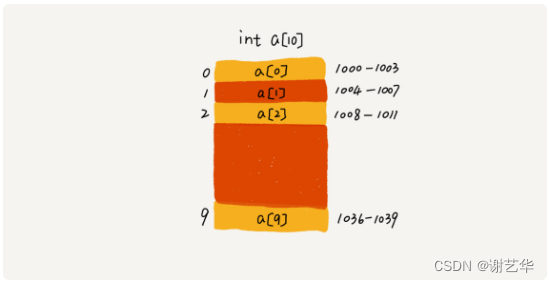
比如我现在要访问数组中第5个数据a[4] (数组下标从0开始)。操作系统就会从 base_address+4*sizeof(int) 地址进行取值。正是通过这个公式实现数组的随机访问。
其实在这里,我们就可以回答刚开始导入的问题了:为什么数组的下表从0开始,而不是从1开始?
原因有二:
- 我们知道数组的随机访问是通过base_address+i*sizeof(data_type_size)公式计算的。如果数组的下表从1开始,数据在内存中的分布是不会改变的。上面的例子就是:访问数组中第5个数据a5。操作系统就会从base_address+(i-1)*sizeof(data_type_size)这个地址进行取值。相对于上面的公式,多了一个减法操作。(这种常用操作,对于CPU而言,性能的提升可能是很大的)。但这并不是主要原因,因为也有语言中数组的下表不是从0开始。
- 历史原因,因为C语言作为最早出现的高级语言,它的数组下标就是从0开始的。后面java等其它高级语言在创建之初,就继承了这一特性。(大部分人都已习惯从0开始)
数组的增删查
数组的最大优势就是高效的查询。但是这其中也存在一定的坑。比如:数组的查询复杂度是O(1)。这句话是正确的吗?
错误的,因为即使是有序的数组,采用二分法。查询的复杂度也应该是O(logn)。准确的说法应该是:数组根据下标查询的复杂度是O(1)。
数组的增加和删除是比较低效的操作了。因为增加一个或者是删除一个你要保证内存数据的连续性。
数组的越界
数组的越界总是会发生一些意想不到的问题。我们看分析一下该代码,看看是什么现象。
int main(int argc, char* argv[]){
int i = 0;
int arr[3] = {0};
for(; i<=3; i++){
arr[i] = 0;
printf("hello world\n");
}
return 0;
}现象是无限的打印“hello world”。我相信代码的错误点,大家肯定是知道的————数组越界访问。但是为什么会造成无限打印呢?这需要了解linux 虚拟内存分布以及栈的概念了。
我们首先要知道linux进程的虚拟内存为4G,并且不同的地址分配着不同的资源。可参考下图:

其中各个空间分布,我就不再赘述了。只介绍该题需要分析的栈。需要注意以下几点:
- 栈也是一个数据结构,它的特点是先进后出。
- 并且它是向下连续增长的
- 一个线程中,是共享一个栈的。(线程中的栈大小是有限制)
我们知道局部变量是分布在栈中的,根据上面的代码,我们可以开始分析。
- int i=0;//i变量入栈,假设地址为1000
- int arr[3]={0};//arr数组入栈,arr[0]地址为988,arr[1]地址为992,arr[2]地址为996。
分析到这里,我们就知道了,当访问arr[3]时,计算机根据base_address+3*data_type_size公式,实际上访问的是i变量,将i设置为了0,导致重新循环开始。所以一直无限打印“hello world”。
总结
该篇简单介绍了数组这个数据结构。分析了它为什么能够实现随机访问。以及数组越界可能会带来的一些问题。数组比较适合用来查询,但是删除和增加,就比较低效了。
对于超级大的数组,每次删除都会搬移其它数据。如果删除操作比较频繁。那么就是比较低效的。为了减少搬移数据的次数,我们可以将删除的变量进行标记(已使用或未使用),当内存不足时,再进行释放。这样就减少了搬移次数,提高效率。其实这也是JVM标记清除垃圾算法的思想。
-
相关阅读:
JS中的闭包
微信小程序源码-高校学生事务管理系统的计算机毕业设计(附源码+演示录像+LW)
ClickHouse(01)什么是ClickHouse,ClickHouse适用于什么场景
AM@邻域@极限定义中的符号说明
找准边界,吃定安全 | 流量剧增?看山石网科如何打破传统限制
Web前端开发技术课程大作业——南京旅游景点介绍网页代码html+css+javascript
可变电阻元件封装
Docker - Docker挂载mysql
AutoSAR入门:开发工具链介绍
Go语言关于协程何时退出的问题
- 原文地址:https://blog.csdn.net/xieyihua1994/article/details/134555363