-
新的按人口比例的邮政编码
上次写信是什么时候?已经多久没用过邮政编码了?随着科技的进步,现在的人们似乎已经不再写信了,取而代之的是电子邮件、微信等。而且,手写字体识别功能,做为人工智能的入门级应用,也已经很成熟了。似乎不需要邮政编码也能把信寄到,只需让机器识别地址就行了。虽然纸质的信件少了,但是快递多了,设计一套类似于邮政编码的体系,还是有使用场景的。本文就设计了一套这样的编码,它是按人口比例来进行编码的,人口多的地区分配较多的编码。
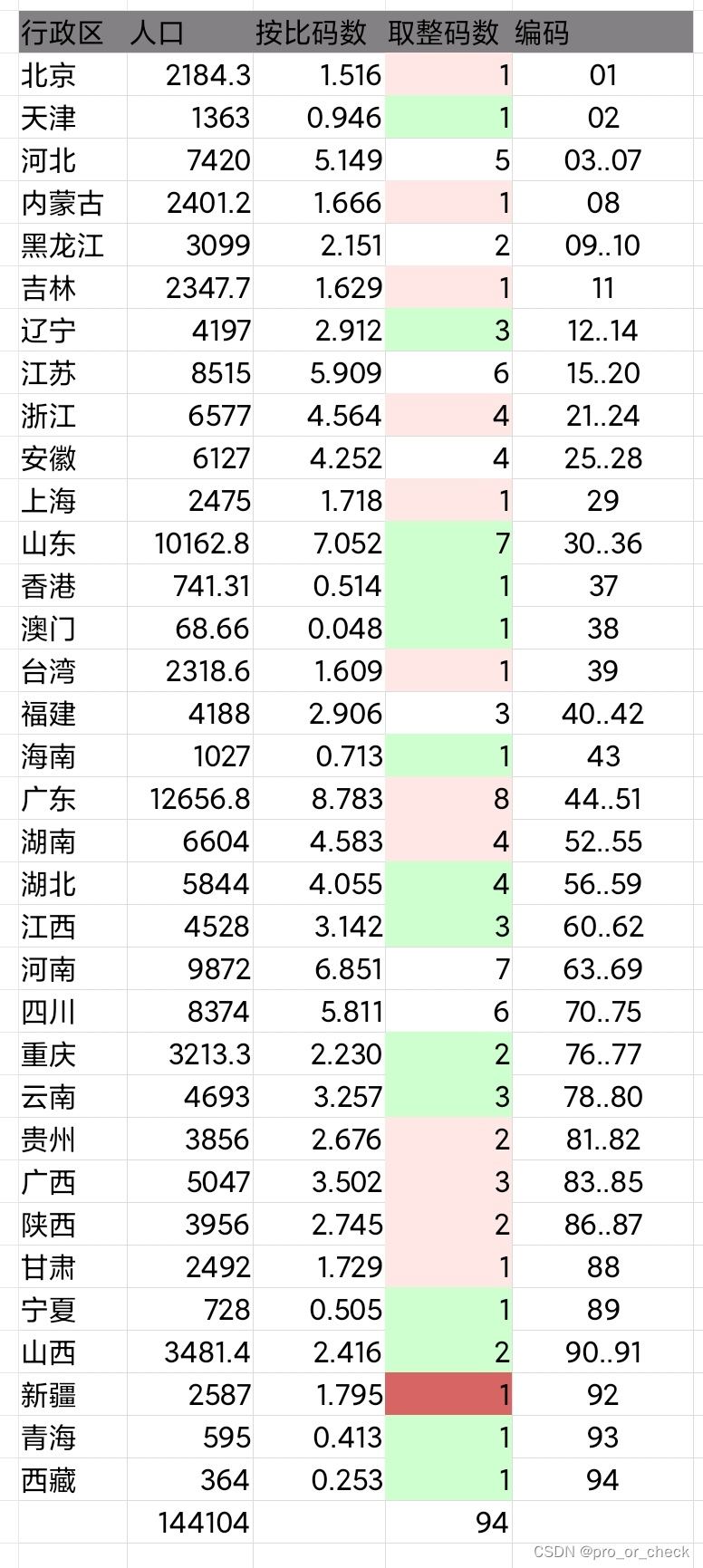
第一步,是统计人口。从网上获取人口数据,成为表格中的A列、B列。
第二步,是计算。计划用2位数表示省级行政单位,共有100个位置,用某省的人口,除以总人口,再乘以100,得到“按比码数”,对它四舍五入,得到“取整码数”。发现取整码数的总和大于100了,这时,采用五舍六入、六舍七入等尝试一下,最终,决定使用七舍八入,保证码数总和不大于100。
第三步,分配编码。这一步容易实现,北京01,天津02,河北03至07。为河北分配了5个编码,这是根据人口分配的结果。以往的邮政编码,一个省只分配一个编号,新的编码体系中,要记住03至07都是河北省。
至此,省级行政单位的编码完成,下一步是县级行政单位。再加2位数,表示县。以北京为例,加2位数之后,有100个位置。北京有16个区县,每个区县分配5个编码,总共占用16×5=80个编码。以河北为例,加2位数后,有500个位置,167个县,167×2=334,这么分配可以。或者是继续上文的方法,按人口比例给河北的各县分配编码。
补充,从按比码数到取整码数,不能直接四舍五入,这很麻烦。修改算法,计算按比码数时,不要取得太满,例如,有100个位置,可以按80个来计算。这样一来,按四舍五入算出来的取整码数,就大概是90个左右的样子。保留一些位置,供以后扩充也是好的。
总结
虽然纸质的信件少了,但快递多了,研究邮政编码依然有用。按人口比例分配编码,更科学。因为各省人口差距悬殊,一省一码,应该放弃。例如,记住03至07都是河北省,0101至0105都是北京市东城区。按照本文的做法,邮政编码可以扩充到6位,甚至8位、10位,精确到村,或是户。
-
相关阅读:
SpringBoot-42-注册Web原生组件
system verilog(1) --- 数据类型
SSL及GMVPN握手协议详解
【conda】解决 An HTTP error occurred when trying to retrieve this URL.问题
FastAdmin列表实现自定义搜索及传值
lunatic亚毫秒 Web 框架的LiveView实时视图
间歇性禁食 & 肠道菌群 & 心血管代谢疾病
非零基础自学Java (老师:韩顺平) 第10章 面向对象编程(高级部分) 10.5 final关键字
CMake 学习笔记
【重温基础算法】内部排序之希尔排序法
- 原文地址:https://blog.csdn.net/proorck2019/article/details/134544665