-
神经网络中BN层简介及位置分析
1. 简介
Batch Normalization是深度学习中常用的技巧,Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift (Ioffe and Szegedy, 2015) 第一次介绍了这个方法。
这个方法的命名,明明是Standardization, 非要叫Normalization, 把本来就混用、意义不明的两个词更加搅得一团糟。那standardization 和 Normalization有什么区别呢?
一般是下面这样(X是输入数据集):
- normalization(也叫 min-max scaling),一般译做 “归一化”:

- standardization,一般译做 “标准化”:
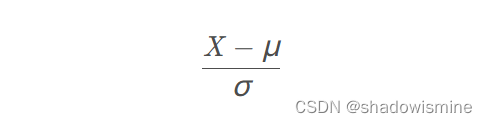
Batch-Norm 是一个网络层,对中间结果作上面说的 standardization 操作。实际上 standardization 也可以叫做 Z-score normalization。所以可以这样理解,standardization 是一种特殊的 normalization。normalization 作为一个 scaling 的大类,包括 min-max scaling,standardization 等。
2. BatchNorm
对输入进行标准化的时候,计算每个特征在样本集合中的均值、方差;然后将每个样本的每个特征减去该特征的均值,并除以它的方差。用数学公式表示,即:

而所谓的BatchNorm, 就是神经网络中间,在一小撮batch样本中进行标准化。具体如下(B: batch size)

注意,BatchNorm作为神经网络的一层,是有两个参数
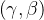 要训练的,分别称为拉伸和偏移参数。可能你会有疑问,既然已经对
要训练的,分别称为拉伸和偏移参数。可能你会有疑问,既然已经对 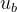 作了标准化得到了
作了标准化得到了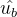 ,为什么还要用
,为什么还要用 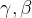 将它“还原”呢?
将它“还原”呢?实际上,设置这两个参数是为了给神经网络足够的自由度。如果经过训练
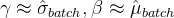 , 说明神经网络认为,不需要进行批标准化即可使loss function最小化,我们也充分“尊重”它的选择。
, 说明神经网络认为,不需要进行批标准化即可使loss function最小化,我们也充分“尊重”它的选择。3. BN 的特点
- 使用 BatchNorm,我们可以尝试更大的学习率,从而加速收敛,但一般不会改变模型的精度;
- BatchNorm 的效果依赖于 Batch size;一般需要较大的 Batch size(>16)才能有好的效果
- 和 Dropout 一样,BatchNorm 在训练和推理时有不同的行为:训练时,它基于每个 batch 计算均值和方差,因此 batch size 必须足够大才能较好反映统计性质;推理时,BatchNorm 则直接用训练集整体的均值和方差进行标准化。
训练集整体的均值和方差如何得到?——在每个batch的均值和方差计算中,通过移动平均估算得到。
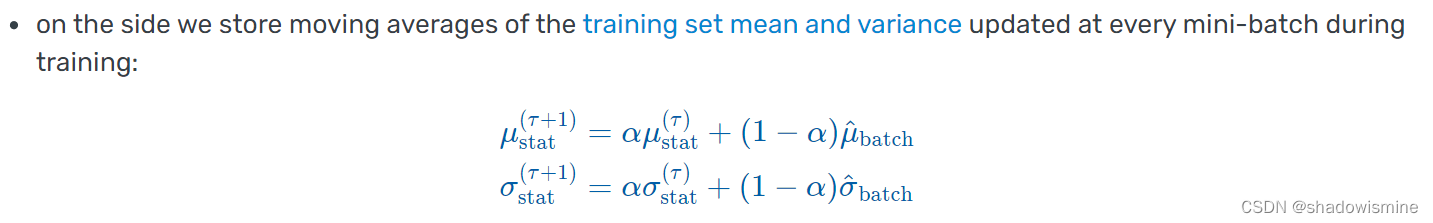
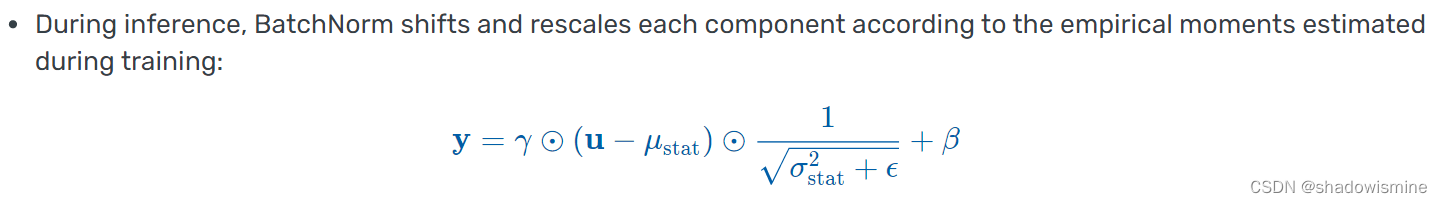
4. BN 的位置
BatchNorm 究竟应该放在哪,现在还存在争议。很多人说应该放在激活函数之前,但也有声音说应该放在激活函数之后。思考一下,两种说法都有道理。举个简单的例子。
前一种说法是要对
 作BatchNorm,这样可以保证 在0附近,
作BatchNorm,这样可以保证 在0附近,  不至于太小;后一种说法 BatchNorm 的作用对象则直接是
不至于太小;后一种说法 BatchNorm 的作用对象则直接是 ,这样可以控制梯度
,这样可以控制梯度 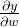 在合理的范围内,不会因为 的极端取值而波动过大。
在合理的范围内,不会因为 的极端取值而波动过大。但现在看来,前一种声音是占上风的:将 BatchNorm 作用在全连接层和卷积层的输出上,激活函数之前。在全连接网络中,顺序是:线性组合+BatchNorm+Activation
对于全连接层,BatchNorm 作用在特征维上。假设输入矩阵大小是 m×n —— m 等于 batch size,即这个小批量中的样本数, n 表示特征数。我们要在每个特征上计算 m 个样本的均值和方差,也就是对每一列做计算。
在卷积神经网络中,顺序是:卷积层+BatchNorm+Activation+池化+全连接。要注意一点是,如果卷积层有K个卷积核(即K个通道),要对每个通道的输出分别做批标准化,且每个通道都拥有独立的拉伸和偏移参数。
对于卷积层,BatchNorm 作用在通道维上。我们先考虑一个 1×1 的卷积层,通道数为 k 。它其实就等价于神经元个数为 k 的全连接层。图片中每个像素点都由一个 k 维的向量表示,可以看作是像素点的 k 个特征。同一批量各个图片的各个像素点,就是不同的样本,共有 m×p×q 个样本, m,p,q 分别为 batch size、高、宽。
类比全连接层 BatchNorm 作用在特征维上,要在每个通道(即每个特征)上计算 m×p×q 个样本的均值和方差。
设小批量中有m个样本。在单个通道上,假设卷积计算输出的高和宽分别为p和q。我们需要对该通道中m×p×q个元素同时标准化:对这些元素做标准化计算时,我们使用相同的均值和方差,即该通道中m×p×q个元素的均值和方差。——卷积神经网络之Batch Normalization(一)
5. BN的理解与延伸
BN 效果好是因为 BN 的存在会引入 mini-batch 内其他样本的信息,就会导致预测一个独立样本时,其他样本信息相当于正则项,使得 loss 曲面变得更加平滑,更容易找到最优解。相当于一次独立样本预测可以看多个样本,学到的特征泛化性更强,更加 general。
Conv+BN+Relu 是卷积网络的一个常见组合。在模型推理时,BN 层的参数已经固定下来,本质就是一个线性变换。我们可以把 Conv+BN+Relu 进行算子融合,以加速模型推理。
除了BN层,还有GN(Group Normalization)、LN(Layer Normalization、IN(Instance Normalization)这些个标准化方法,每个标注化方法都适用于不同的任务。
这个图很好地说明了BatchNorm、LayerNorm、InstanceNorm、GroupNorm的区别。N代表batch size;C代表卷积核个数(通道个数);H,W代表卷积结果的高和宽。
BatchNorm: 计算均值和方差时,考虑N * H * W 个元素;对每个通道分别做标准化
LayerNorm:计算均值和方差时,考虑C * H * W 个元素;对batch中的每个instance分别做标准化
InstanceNorm:计算均值和方差时,考虑H * W 个元素;对每个通道、batch中的每个instance分别做标准化
GroupNorm:介于LayerNorm和InstanceNorm二者之间,将C个通道分组,然后进行标准化。
直觉上来讲,GroupNorm把提取到类似特征的不同卷积核分到同一个group中。对这些卷积核进行标准化,确实make sense. 而且GroupNorm摆脱了对batch size的依赖。
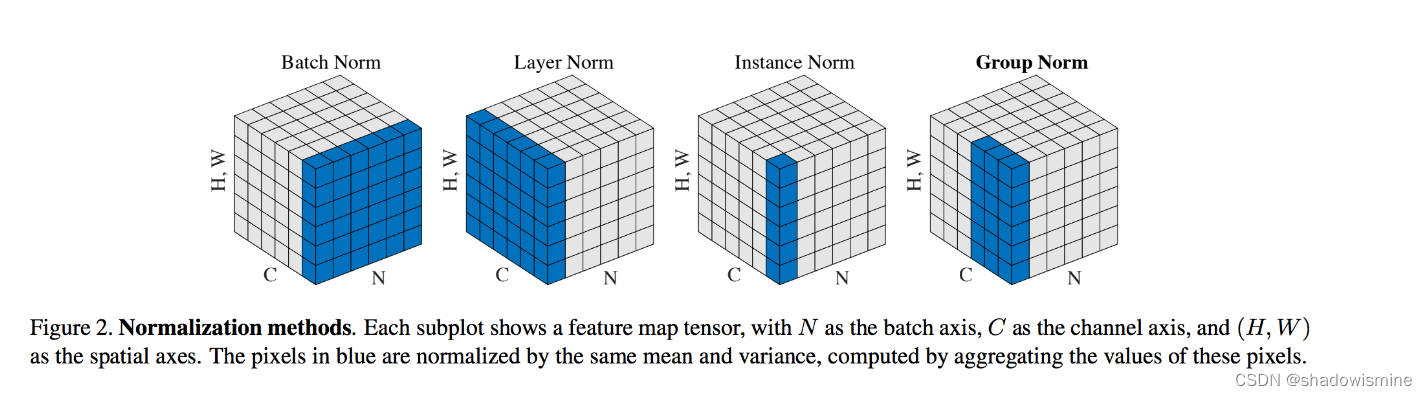
GN在训练集上表现最好,在测试集上稍逊于BN(引自 Group Normalization (Yuxin & Kaiming, 2018))
6. BN vs LN
Transformer模型中用到了LayerNorm,着重对比一下LayerNorm和BatchNorm。
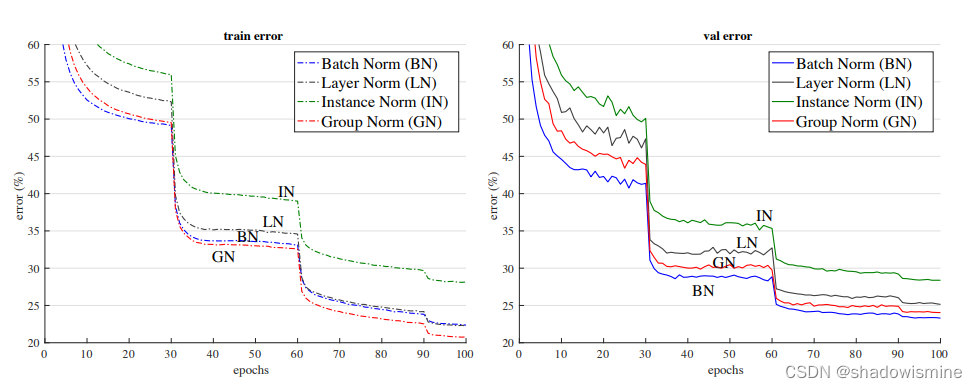
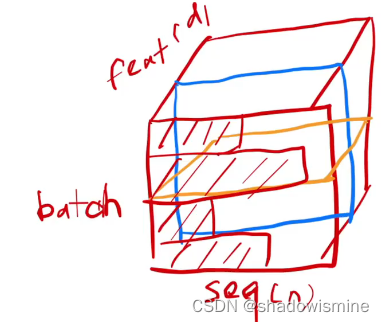
对于一个输入序列 (x1,x2,...,xn) ,每一个 xi 都是 d 维的向量。譬如输入序列是一个句子,每个单词 xi 都用一个 d 维的向量表示。
X轴是序列长度(n),Y轴是特征个数(d),Z轴是Batch size
此时BatchNorm是对图中蓝色框作标准化处理,就像我们上面说的——对每个特征分别做标准化;而LayerNorm针对每一个输入序列,对图中黄色框作标准化处理。总结来说,BatchNorm盯住每一个特征;而LayerNorm盯住的是每一个样本。
那么为什么Transformer模型要用LayerNorm而不是BatchNorm呢?
实际上,序列模型的背景下,BatchNorm有一个天然的硬伤,这使得它在所有序列模型中都不吃香:输入序列的长度(n)可能不一致。一般来说,我们会规定一个最长的序列长度,长度不够的序列用0填充。譬如下图这样,Batch中的序列长短不一。
如果用BatchNorm,以一个feature为例,它的标准化有效范围是蓝色的图,其余用0填充;如果是LayerNorm,对于4个序列,它们的标准化有效范围是黄色的图。
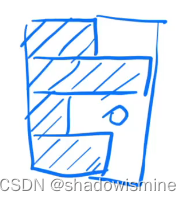

直觉上来说,对于BatchNorm的计算方法,当Batch中序列长度差距过大时,均值和方差的波动也会很大。
但这个问题对于LayerNorm来说并不存在,因为它是在每一个序列内部计算均值和方差的。
这样,我们可以直观地理解,为什么BatchNorm对于序列模型并不好用;为什么Transformer要采用LayerNorm
7. BN代码实现
我们翻一翻常见的backbone的结构。可以看到在官方Pytorch的
resnet.py的class BasicBlock中,forward时的基本结构是Conv+BN+Relu:- # 省略了一些地方
- class BasicBlock(nn.Module):
- def __init__(self,...) -> None:
- ...
- self.conv1 = conv3x3(inplanes, planes, stride)
- self.bn1 = norm_layer(planes)
- self.relu = nn.ReLU(inplace=True)
- self.conv2 = conv3x3(planes, planes)
- self.bn2 = norm_layer(planes)
- self.downsample = downsample
- self.stride = stride
- def forward(self, x: Tensor) -> Tensor:
- identity = x
- # 常见的Conv+BN+Relu
- out = self.conv1(x)
- out = self.bn1(out)
- out = self.relu(out)
- # 又是Conv+BN+relu
- out = self.conv2(out)
- out = self.bn2(out)
- if self.downsample is not None:
- identity = self.downsample(x)
- out += identity
- out = self.relu(out)
- return out
resnet作为我们常见的万年青backbone不是没有理由的,效果好速度快方便部署。当然还有很多其他优秀的backbone,这些backbone的内部结构也多为
Conv+BN+Relu或者Conv+BN的结构。参考资料:BatchNorm and its variants - 知乎normalization 和 standardization 到底什么区别?_为什么batch normalization使用standardization而不是normaliz-CSDN博客不论是训练还是部署都会让你踩坑的Batch Normalization - 知乎
-
相关阅读:
使用物联网进行智能能源管理的10大优势
Django admin 站点管理
【微信小程序】WXML的模板语法与WXSS模板样式
c语言实现三子棋
Problem C: 凯撒加密
TensorFlow 的基本概念和使用场景
【线性代数/机器学习】矩阵的奇异值与奇异值分解(SVD)
【RTOS训练营】继续程序框架、tick中断补充、预习、课后作业和晚课提问
Spring/IoC、DI、Bean
Java项目:SSM网吧计费管理系统
- 原文地址:https://blog.csdn.net/shadowismine/article/details/134532182
