-
Redis跳表详解(附面试题)
面试问题
redis有哪些数据结构?
常用的有:string、hash、list、set、zset
zset主要用什么应用场景?
ZS是有序集合,是一组按关联积分有序的字符串集合,这里的分数是一个抽象概慨念,任何指标都可以抽象为分数。
积分相同的情况下,按字典排序。
相比于se类型多了一个排序属性(score)。
对于有序集合ZSt来说,每个存储元素相当于有两个值组成的,一个是有序集合的元素值,一个是排序值。
有序集合保留了集合不能有重复成员的特性(分值可以重复),但不同的是,有序集合中的元素可以排序。比如:计时器和过期处理,排行榜,范围查找..
那它的底层的数据结构有了解过么?
zset底层结构
压缩链表:当参数的数量达到128以后会转到跳表
跳表:在链表的基础上增加了多级索引,实现快速查找
所以zset有两种数据结构:压缩链表和跳表
跳表概念
跳表(Skip List)是一种基于链表的数据结构,用于实现有序的键值对集合。跳表通过添加多级索引来加速搜索、插入和删除操作,是一种随机化的数据结构。
跳表的基本思想是在底层的链表上添加多级索引,通过跳过一些节点,从而减少搜索的时间复杂度。每个索引级别都是链表的一个子集,其中每个节点都指向下一个索引级别中具有相同或更大键值的节点。最底层索引即为原始链表。
redis跳表结构

回顾一下链表
普通的链表结构,假设要查找某个数据只能从头到尾的查看,这样效率就会很低,是一个O(n)的效率
链表:
-增删快,查改慢
链表适用于写操作多,读操作少的场景。

redis在链表的结构上做了优化
跳表数据结构的案例,跳表就是在链表的基础上加上了多级索引
我会采用伪代码的方式,帮助理解跳表的增删查
查
条件:
1:如果当前节点的key与查询的key相等--返回当前节点
2:如果key不相等,且右侧为null--向下走
3:如果key不相等,且右侧查询的key大于当前查询的key--向下走
4:如果key不相等,且右侧查询的key小于或等于当前查询的key--同级往右走
5:如果key不相等,且右侧不为null,且右侧节点key大于待查询的key。 (说名如果有结果则在这个索引和下个索引之间)查不到则返回null




 这样我们到16的时候就满足第一个条件,返回当前节点
这样我们到16的时候就满足第一个条件,返回当前节点当我们理解怎么查的,剩下的就比较好理解了
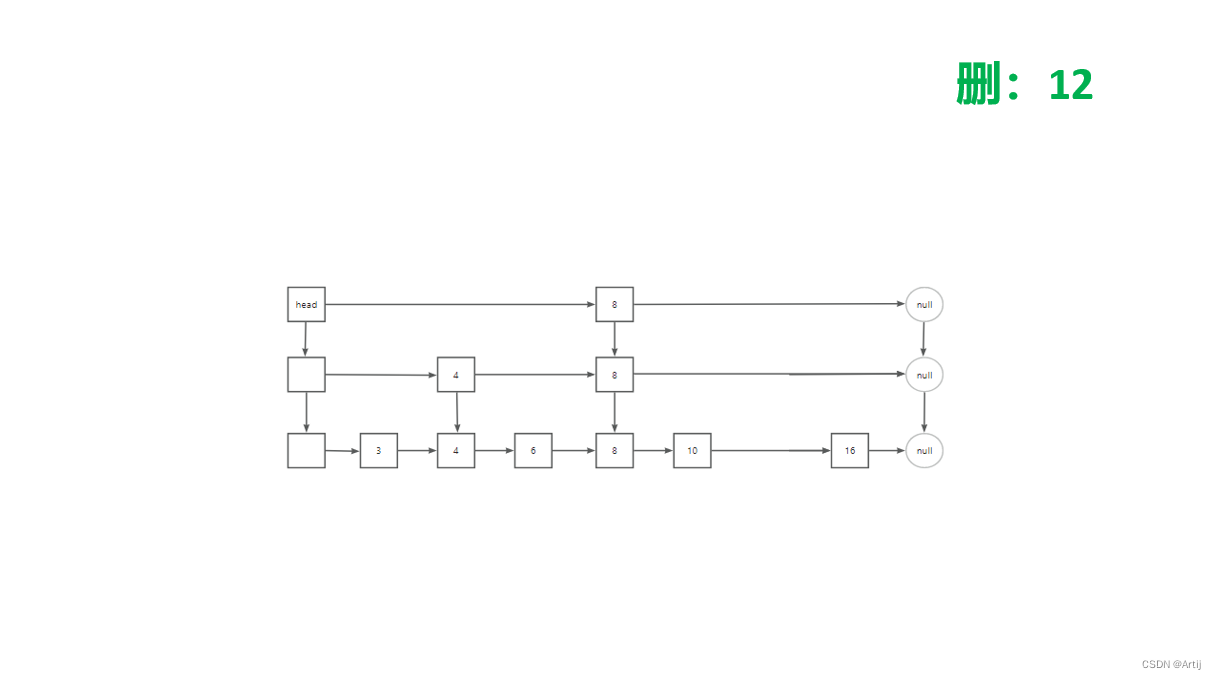
删

删和查很像但还是有点不一样的,当我们到了第三步的时候,他会删除同级12的同时并且向下走

下来以后继续查找12,找到后删除
增
增的时候会体现出随机化数据结构



找到待插入的左节点,然后开始1/2随机的向上添加索引。

1/2随机的向上添加索引。

最终的结构,head永远在最高层。
-
相关阅读:
SettingsIntelligence
vue el-form表单嵌套组件时正则校验不生效
C/C++、Qt开发,跨平台CMake判断当前平台是Linux还是Windows,操作系统判断
MySQL总结(DDL、DML、TPL、DCL)
基于Java web的医院分诊管理系统文档
Mac系列之:Mac安装tesseract和python使用pytesseract、pillow包提取图片中中文
Redis学习笔记9
idea中导入eclipse的javaweb项目——tomact服务(保姆级别)
入门力扣自学笔记119 C++ (题目编号640)
Jenkins自动化部署
- 原文地址:https://blog.csdn.net/Artij/article/details/132640979