-
带哨兵位的单链表
认识
链表分为两种:带头结点的和不带头结点的
之前我们学习了不带哨兵位的单链表,并实现了相关代码
现在我们认识一下带哨兵位头结点的单链表:

plist指向带哨兵位的头结点
这个结点不存储有效数据
如果为空链表:
- 不带头:plist指向NULL
- 带头:plist指向head,一定不会指向NULL
优势
带哨兵位的单链表也有他自己的优势,我们用一道题来证明一下:
题目描述:

题目分析
假设有下面这个链表,给定数字5

那么排序后就是这样,不改变原来是数据顺序
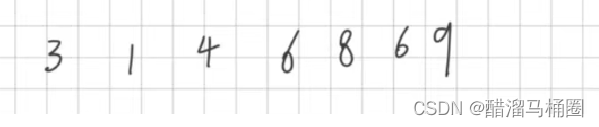
可以分割成两个链表,plist1和plist2,小于x的结点尾插到plist1,否则尾插到plist2
当链表的数据全部尾插结束后,将plist2头结点尾插到plist1,这个时候带哨兵位的头结点就非常有优势了
我们可以定义两个头结点head和head2,分别作为两个链表的哨兵位,再定义两个尾结点tail1和tail2方便两个链表的尾插,定义cur遍历链表,和x值做比较
代码示例
我们思路清晰了就可以写代码了:
- /*
- struct ListNode {
- int val;
- struct ListNode *next;
- ListNode(int x) : val(x), next(NULL) {}
- };*/
- #include
- class Partition {
- public:
- ListNode* partition(ListNode* pHead, int x) {
- // write code here
- struct ListNode* head1,* head2,* tail1,* tail2;
- head1=(struct ListNode*)malloc(sizeof(struct ListNode));
- head2=(struct ListNode*)malloc(sizeof(struct ListNode));
- tail1=head1;
- tail2=head2;
- struct ListNode* cur=pHead;
- while(cur)
- {
- if(cur->val{tail1->next=cur;tail1=tail1->next;}else{tail2->next=cur;tail2=tail2->next;}cur=cur->next;}tail1->next=head2->next;tail2->next=NULL;pHead=head1->next;free(head1);free(head2);return pHead;}};
由于该题只能用c++,但是我们可以完全按照C语言的语法规则写内部,最后就可以通过了;
- 相关阅读:
jvm关闭时的钩子函数
centos7下docker的安装
jar包,引入依赖
Java并发编程: Thread常见方法
单日 5000 亿行 / 900G 数据接入,TDengine 3.0 在中国地震台网中心的大型应用
205、使用消息队列实现 RPC(远程过程调用)模型的 服务器端 和 客户端
使用rest — assured框架优雅实现接口测试断言
HDU - 2859 Phalanx(DP)
高级工程师评审:高级工程师有哪些专业?高级工程师职称专业分类
pytest一些常见的插件
- 原文地址:https://blog.csdn.net/m0_74722801/article/details/134484671
