-
Linux——编译器gcc/g++、调试器gdb以及自动化构建工具makefile&&make详解
编译器—gcc/g++、调试器—gdb以及自动化构建工具—makefile&&make
文章目录
本章思维导图:
 注:本章思维导图对应的
注:本章思维导图对应的
.xmind和.png文件都已同步导入至 资源1. 编译器——gcc/g++
安装命令:
- gcc:
sudo yum install -y gcc - g++:
sudo yum install -y gcc-c++
- gcc只能编译C语言代码,g++既可以编译C语言代码也可以编译C++代码
- 推荐用gcc编译C语言代码
注:gcc和g++的选项一致,下面的讲解都以gcc为例
1.1 生成可执行文件与修改默认可执行文件
我们可以直接用gcc编译器将一个
.c文件直接编译成可执行文件命令:
gcc filename在这种情况下,会默认生成一个
a.out可执行文件
如果我们想要指定生成的可执行文件的名字,可以加入
-o选项gcc -o newName filename
当然,如果想要对gcc编译器做更多的了解,上面的操作显然是不够的,我们需要结合程序的翻译过程来进行学习。
1.2 程序的翻译过程以及对应的gcc选项
众所周知,程序的翻译分为了四个步骤:预处理、编译、汇编、链接。要学会只用Linux的编译器:gcc/g++,固然也需要理解这四个步骤
关于这四个步骤,博主已经在程序的翻译环境和运行环境做了较为详细的阐述,故下面只对这四个步骤做简单的讲解:
1.2.1 预处理 gcc -E
在这一过程,编译器会进行头文件展开、宏替换、条件编译等过程
对应的gcc命令为:
gcc -E -o file.i file-E:即为预处理的gcc选项。表示预处理完后就停止- 预处理完后生成的文件后缀一般为
.i
演示:

可以看到,所谓的头文件展开实际上就是将头文件的内容拷贝至源文件中,预处理后得到的文件仍是C语言
1.2.2 编译 gcc -S
在这一过程,会对与处理过后的文件进行语法分析和词义分析,如果没有错误,就会生成以一个由汇编代码所写的文件
对应的gcc命令为:
gcc -S -o file.s file-
-S:即为编译的gcc选项。表示编译完后就停止 -
编译生成的文件的后缀名一般为
.s
演示:

1.2.3 汇编 gcc -c
在这一过程中,会将汇编代码转换为二进制代码,形成一个二进制文件
对应的gcc命令为:
gcc -c -o file.o file-c:即为汇编的gcc选项。表示汇编完后就停止- 汇编生成的二进制文件我们称其为目标文件
.obj,文件后缀可以为.o
演示:

1.2.4 链接 gcc
会对目标文件进行动静态库链接,形成最终的可执行程序
.exe对应的gcc命令为:
gcc -o newName filename- 可以看到,用这条命令就可以直接生成一个可执行程序
演示:

以前写代码时大家可能会有一个疑惑:我明明没有声明和定义
printf()、scanf()等库函数,为什么我可以正常使用呢?而之所以我们可以使用这些库函数,正是因为编译器有链接这一过程,这一过程将目标文件和库文件进行链接,从而让我们可以使用库中声明和定义好的函数
我们可以用命令:
ldd file,查看一个文件依赖的库文件函数库分为动态库和静态库两种:
动态库:
- 动态库不包含在可执行程序中,而是在程序运行时由操作系统或者程序自行加载
- 多个程序可以共享一个动态库,因此如果采用动态链接可以**减少程序所占用的
- 使用动态链接的程序对库的依赖性较强,因此一旦库丢失,会使依赖这个库的程序都无法运行
- gcc/g++编译默认进行的是动态链接

静态库:
一般来说,需要自己对C语言和C++的静态库进行安装,执行下面两个命令即可:
sudo yum install -y glibc -staticsudo yum install -y libstdc++ -static- 静态库是指编译链接时,把库文件的代码全部加入到可执行文件中的库
- 静态库包含在可执行程序中,因此使用静态链接的程序对库的依赖性较弱,同类型平台都可以使用
- 由于可执行程序包含了库文件的拷贝,因此使用静态链接的程序会占用较多的资源空间(内存、磁盘)
- 如果要使gcc/g++进行静态链接,就要加入
-static选项

2. 调试器——gdb
安装命令:
sudo yum install -y gdb为了能够更好的理解,我们先来谈谈程序发布的两个版本——
debug版本和release版本2.1 debug版本和release版本

首先我们要清楚:
- Linux上的gcc和g++编译出来的可执行程序默认都是
release版本的 release版本是不支持调试的,只有在debug版本下才能调试
为了在Linux上能够生成
debug版本的可执行程序,我们需要在编译时加上选项-ggcc -o newFile file -g下面,我们再来谈谈为什么一个程序要有
debug和release两个版:- 在程序的开发阶段,程序难免会出现各种问题,而为了能够方便程序员对这些错误进行排查,就必须要支持调试这一功能,因此程序员开发中的程序一般都是debug版本,里面包含了各种调试信息,方便进行错误排查
- 当程序员认为开发中的程序已经基本完成,就会将其交给测试组的人员进行测试。而这个程序最终肯定是要交给大众去使用的,使用这个程序的普通人显然不需要
debug版本的调试信息,他们只需要更小的体积和更快的下载速度,因此这就要求程序需要一个**release发行版本,这个版本就是给测试组的人员进行测试和给用户进行使用的版本**
2.2 gdb常用功能及其选项

进入调试模式的命令为:
gdb filefile必须是一个debug版本的可执行程序
2.2.1 查看代码
命令:
l n- 查看第n行附近的10行代码
- 按
Enter可以继续查看
2.2.2 开始/退出调试
命令:
r:如果没有打断点,那么会正常运行代码;否则会运行到第一个断点处quit:推出调试
2.2.3 断点设置
添加断点:
b n:在第n行添加断点b 函数名:在指定函数的入口处添加断点b file:n:在指定文件的第n行添加断点。注意:这个file不是可执行程序,而是被编译的.c/.cpp文件
查看断点:
info b例如:

- 第一列的数字
Num表示断点的编号 - 第四列的字符
Enb表示断点的使能状态,y表示该断点处于开启状态,可被使用;n表示处于关闭状态,不可被使用
删除断点:
d n:表示删除**编号为n**的断点。- 特别注意,删除断点是按编号删除,而不是按行号
使能断点:
disable n:关闭编号为n的断点enbale n:开启编号为n的断点
2.2.4 逐语句/逐过程
逐语句:
-
在C语言/C++中,被一个分号
;分割的语句都被称为一条语句。逐语句调试就是一个个分号地,不做任何跳过的调试。 -
因此逐语句调试可以进入函数体内调试。
命令:
s逐过程:
- 一个函数成为一个过程
- 因此逐过程调试不能进入函数体内进行调试
命令:
n2.2.5 断点跳跃
如果打了多个断点,那我们可以通过命令直接运行到下一个断点处:
c2.2.6 查看变量
p name:查看指定变量的内容如果想要使变量一直显示,可以用命令:
display name例如:

- 变量前的数字即为该变量的编号
如果想删除常显示的变量,可以使用命令:
undisplay n:即删除编号为n的变量常显示2.2.7 查看函数调用堆栈
命令:
bt3. 自动划构建工具——makekfile&&make

Makefile和
make是与Linux系统中软件编译和构建相关的工具。它们通常用于自动化构建过程,确保在源代码发生变化时只重新编译必要的部分,从而提高开发效率。3.1 makefile
- 也可以写为
Makefile makefile是一个文本文件- makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行更复杂
的功能操作
我们来通过一个具体的例子来学习一个
makefile文件要包括哪些内容: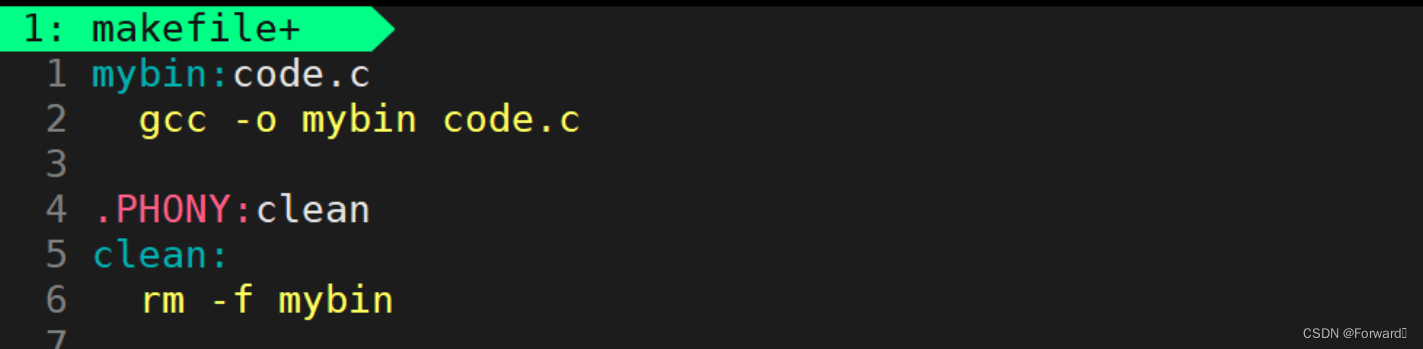
mybin:code.c- 这叫一组依赖关系。
mybin目标文件,code.c为依赖文件列表。 - 表示
mybin这个目标文件依赖于code.c这个文件列表而构建
gcc -o mybin code.c- 注意:前面必须有
Tab缩进,这是语法要求 - 这一行叫做依赖方法。
- 表示目标文件是通过gcc编译来完成对
code.c这一依赖文件列表的依赖的
.PHONY:clean- 将
clean设置成一个伪目标 - 伪目标在任何时候都会执行,不会受时间戳限制
clean:clean也是一个目标文件,但是没有对应的依赖文件列标- 其被修饰为了一个伪目标,表示一个命令操作——清除
rm -f mybin- 这就是
clean的依赖方法,即clean对应的操作
makefile文件的其他写法:
-
在一组依赖关系和依赖方法中,目标文件可以被
$@替换,依赖关系列表可以被$^替换,例如:
-
makefile文件也允许我们定义变量和选项,例如:

3.2 make
make是一个命令
3.2.1 工作原理
如果我们只输入一个
make命令:-
会找到
makefile中的第一个目标文件,然后根据依赖文件列表和依赖方法构建出目标文件 -
如果依赖文件列表有文件不存在,那么会继续向下找这个不存在文件的依赖关系和依赖方法,知道构建出这个文件
-
如果最终这个文件不能被构建,那么此次
make命令就会报错 -
例如:

make后面也可以跟一个目标文件来执行指定的操作。例如:
make clean特别注意:
如果一个目标文件没有被
.PYTHON修饰为伪目标,那么它的make构建就会收到时间戳的影响-
即,如果该文件的
修改时间没有改变,那么就不会进行make构建 -
例如,重复构建目标文件
mybin,会报错:
而提到修改时间,我们就有必要了解一个文件的
acm时间3.2.2 文件的acm时间
我们可以用命令查看一个文件的
acm时间:stat filename
Access:访问时间。即最后一次读写文件的时间Modify:修改时间。即最后一次修改文件内容的时间。这个时间就是影响make构建的时间Change:改变时间。文件 = 内容 + 属性,即最后一次改变文件内容或属性的时间。
我们也可以用命令来刷新一个文件的acm时间:
touch filename
本章完。
下一章,我们将进入Linux系统编程部分,各位如果感兴趣不妨点个关注。

- gcc:
-
相关阅读:
简洁版用户登录系统
R语言使用table1包绘制(生成)三线表、使用双变量分列构建三线表、双变量分列三线表、自定义调换双变量的顺序从不同角度分析查看
国产软件迅速崛起,这应该是最适合国内程序员的API管理神器!
windows 启用对TLS1.2和1.3的支持,并禁用对TLS1.0的支持
【AI绘图】咒术师的评级指南
JS事件循环详解
FFmpeg开发笔记(二十二)FFmpeg中SAR与DAR的显示宽高比
大学英语四级考试核心高频词汇突破
x86处理器指令
解码字母到整数映射(Java算法每日一题)
- 原文地址:https://blog.csdn.net/l315225/article/details/134497999