-
【强化学习】Offline RL
离线强化学习(Offline RL)
参考资料:RLChina2021 强化学习前沿(一) 北京大学卢宗青 【RLChina 2021】第9课 强化学习前沿(一) 卢宗青_哔哩哔哩_bilibili
RLChina 2021 强化学习暑期课 http://rlchina.org/topic/9
分类
Off-policy RL algorithms
- 例如:Q-learning,DDPG,SAC,etc
- 目标是最大化当前状态下所采取动作所能获得的最大价值
On-policy RL algorithms
- 例如:REINFORCE,A3C,PPO,etc
- 使用策略收集到的经验来进行更新
Offline/batch RL
- 只从数据中去学习策略,不和环境进行交互
-
<
s
,
a
,
r
,
s
′
>
{
定义

s ∼ d π β ( s ) a ∼ π β ( a ∣ s ) s ′ ∼ P ( s ′ ∣ s , a ) r ← r ( s , a ) s \sim d^{\pi_\beta}(s) \quad a \sim \pi_\beta(a \mid s) \quad s^{\prime} \sim P\left(s^{\prime} \mid s, a\right) \quad r \leftarrow r(s, a) s∼dπβ(s)a∼πβ(a∣s)s′∼P(s′∣s,a)r←r(s,a)
优化目标是:
max π ∑ t = 0 ∞ E s t ∼ d π ( s ) , a t ∼ π ( a ∣ s ) [ γ t r ( s t , a t ) ] \max _\pi \sum_{t=0}^{\infty} \mathbb{E}_{s_t \sim d^\pi(s), a_t \sim \pi(a \mid s)}\left[\gamma^t r\left(s_t, a_t\right)\right] πmaxt=0∑∞Est∼dπ(s),at∼π(a∣s)[γtr(st,at)]
之所以提出offline RL是因为我们可以获得很多别的策略与环境交互所产生的数据,CV和NLP都可以基于大数据学到很好的模型,那么强化学习是否也可以?那么这是否可以用off-policy的方法来解?
以下的数据是使用SAC在一个expert dataset(在数据集上学得很好的策略所产生的transition)得出的。

结果发现存在如下几个问题:
- Q值被很大地高估了
- 随着数据量增加模型表现并没有提升,这并不是过拟合
- Q函数可能会随着训练轮数增多而发散了。
训练过程中的TD Error如下所示,训练的是Q函数:
E s , a , r , s ′ ∼ D [ ( Q ( s , a ) − ( r + max a ′ Q ( s ′ , a ′ ) ) ) 2 ] \mathbb{E}_{s, a, r, s^{\prime} \sim \mathcal{D}}\left[\left(Q(s, a)-\left(r+\max _{a^{\prime}} Q\left(s^{\prime}, a^{\prime}\right)\right)\right)^2\right] Es,a,r,s′∼D[(Q(s,a)−(r+a′maxQ(s′,a′)))2]

Q学习可能会选择一些不可见的动作,这些动作在训练过程中还没有被训练过,可能是随机初始化而产生的一个随机结果,从而就会导致Q值被高估的问题。
因此Double DQN被提出来解决Q值被高估的问题。在online的模式中,探索机制会起到错误校准的作用。
但是在offline的模式中,是不能进行探索的。
总的来说,是因为行为策略(采集数据的策略)和学习策略之间存在着差异。
Q ( s , a ) ← r + γ max a ′ Q ( s ′ , a ′ ) Q ( s , a ) ← r + γ E a ′ ∼ π ( a ∣ s ) Q ( s ′ , a ′ ) ≠ π β ( a ∣ s ) Q(s,a)←r+γmaxa′Q(s′,a′)Q(s,a)←r+γEa′∼π(a∣s)Q(s′,a′) \quad \neq \pi_\beta(a \mid s) Q(s,a)←r+γa′maxQ(s′,a′)Q(s,a)←r+γEa′∼π(a∣s)Q(s′,a′)=πβ(a∣s)E s , a ∼ d π ( s , a ) [ ( Q ( s , a ) − B Q ˉ ( s , a ) ) 2 ] = π β ( a ∣ s ) \mathbb{E}_{s, a \sim d^\pi(s, a)}\left[(Q(s, a)-\mathscr{B} \bar{Q}(s, a))^2\right]=\pi_\beta(a \mid s) Es,a∼dπ(s,a)[(Q(s,a)−BQˉ(s,a))2]=πβ(a∣s)
解决方案
policy constraint
π θ : = arg max θ E s ∼ D , a ∼ π θ ( a ∣ s ) [ Q ( s , a ) ] s.t. D ( π θ ( a ∣ s ) , π β ( a ∣ s ) ) ≤ ϵ \pi_\theta:=\arg \max _\theta \mathbb{E}_{s \sim \mathcal{D}, a \sim \pi_\theta(a \mid s)}[Q(s, a)] \quad \text { s.t. } \quad D\left(\pi_\theta(a \mid s), \pi_\beta(a \mid s)\right) \leq \epsilon πθ:=argθmaxEs∼D,a∼πθ(a∣s)[Q(s,a)] s.t. D(πθ(a∣s),πβ(a∣s))≤ϵ
将要学习的策略和行为策略之间的divergence控制在一定的范围内。

限制策略的一些方法
Distribution matching
K L ( π θ ( a ∣ s ) ∥ π β ( a ∣ s ) ) \mathrm{KL}\left(\pi_\theta(a \mid s) \| \pi_\beta(a \mid s)\right) KL(πθ(a∣s)∥πβ(a∣s))
Support matching
M M D ( π θ ( a ∣ s ) ∥ π β ( a ∣ s ) ) \mathrm{MMD}\left(\pi_\theta(a \mid s) \| \pi_\beta(a \mid s)\right) MMD(πθ(a∣s)∥πβ(a∣s))
State marginal constraints
Implicit/closed form distribution constraints
不同策略限制方法的比较
max π ∑ t = 0 ∞ E s i ∼ d π ( s ) , a i ∼ π ( a ∣ s ) [ γ t r ( s t , a t ) ] − α D ( π ( a ∣ s ) , π β ( a ∣ s ) ) \max _\pi \sum_{t=0}^{\infty} \mathbb{E}_{s_i \sim d^\pi(s), a_i \sim \pi(a \mid s)}\left[\gamma^t r\left(s_t, a_t\right)\right]-\alpha D\left(\pi(a \mid s), \pi_\beta(a \mid s)\right) πmaxt=0∑∞Esi∼dπ(s),ai∼π(a∣s)[γtr(st,at)]−αD(π(a∣s),πβ(a∣s))
上面公式的D函数会让算法选择不同的行为
这个限制不能太严格,因为这样学出来的策略就和行为策略是一样的,但同时这个策略要能规避一些差的actions。

distribution matching是根据分布的density来形成策略。
support matching是根据行为策略的subset来形成一个新的策略。
策略限制方法的不足
-
需要某种评估方法来评估行为策略
- 如果行为策略被错误评估,策略限制方法会不成功。
-
通常比较保守
- 学到的策略会和行为策略非常相似
策略限制是通过避免在分布以外的行为,从而间接地解决了高估Q的问题
但是,在某些情况下,并不是所有的在分布以外的行为都是不好的,它们只在价值被高估的时候是不好的。
Conservative Method
Conservative model-based offline RL

对于绿色区域内的data,使用学到的reward function
对于绿色以外的区域,reward function会有个penalty,公式如下:
r ~ ( s , a ) = r ( s , a ) − λ u ( s , a ) \tilde{r}(s, a)=r(s, a)-\lambda u(s, a) r~(s,a)=r(s,a)−λu(s,a)
u表示uncertainty,从而鼓励模型尽量学习绿色区域以内数据。
如何获取uncertainty?

在一系列动态模型的不一致度 MOReL Planning
dis ( s , a ) = max i , j ∥ f ϕ i ( s , a ) − f ϕ j ( s , a ) ∥ 2 r ~ ( s , a ) = − R max if dis ( s , a ) > threshold \operatorname{dis}(s, a)=\max _{i, j}\left\|f_{\phi_i}(s, a)-f_{\phi_j}(s, a)\right\|_2 \quad \tilde{r}(s, a)=-R_{\max } \quad \text { if } \operatorname{dis}(s, a)>\text { threshold } dis(s,a)=i,jmax fϕi(s,a)−fϕj(s,a) 2r~(s,a)=−Rmax if dis(s,a)> threshold
计算一系列动态模型的协方差矩阵 MOPO MBPO
p i ( s ′ ∣ s , a ) = N ( μ i ( s , a ) , Σ i ( s , a ) ) u ( s , a ) = max j ∥ Σ j ( s , a ) ∥ F p_i\left(s^{\prime} \mid s, a\right)=\mathcal{N}\left(\mu_i(s, a), \Sigma_i(s, a)\right) \quad u(s, a)=\max _j\left\|\Sigma_j(s, a)\right\|_F pi(s′∣s,a)=N(μi(s,a),Σi(s,a))u(s,a)=jmax∥Σj(s,a)∥F

Conservative Q Learning

增大在dataset里的(s,a)的Q值,减小不在dataset里的(s,a)的Q值。

Conservative Offline Model-Based Policy Optimization

Uncertainty-based offline RL methods

Random Ensemble Mixture

Uncertainty weighted actor-critic

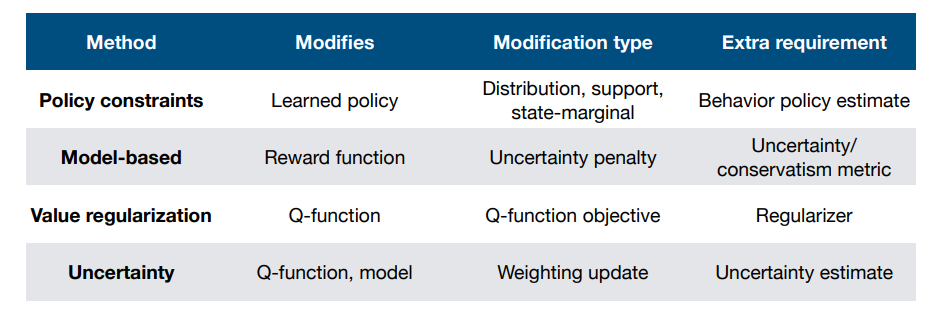
Offline RL方法总结
Policy constraint
- 行为策略需要被建模
- 倾向于变得更保守
Model-based offline RL
- 当数据集是高度收敛的时候效果很好
Value-regularized offline RL
- 倾向于不那么保守
Uncertainty-based offline RL
- 对于无模型和基于模型的方法都很有效
Benchmark

-
相关阅读:
Spring Security 自定义拦截器Filter实现登录认证
单机K8s加入节点组成集群
CleanMyMac X4中文版Macbook必备Mac应用清理工具
Qt | 拖放、拖动的使用、将文件拖入使用示例
如何提升和扩展 PostgreSQL — 从共享缓冲区到内存数据网格
springboo集成activiti5.22在线设计器
iceoryx(冰羚)-Architecture
如何分析一篇论文或者是期刊?
基于opencv的缺陷检测
Verilog零基础入门(边看边练与测试仿真)-时序逻辑-笔记(4-6讲)
- 原文地址:https://blog.csdn.net/Henry_Zhao10/article/details/132996476