-
栈与队列:设计循环队列
目录

题目🔥:
- 设计你的循环队列实现。 循环队列是一种线性数据结构,其操作表现基于 FIFO(先进先出)原则并且队尾被连接在队首之后以形成一个循环。它也被称为“环形缓冲器”。
- 循环队列的一个好处是我们可以利用这个队列之前用过的空间。在一个普通队列里,一旦一个队列满了,我们就不能插入下一个元素,即使在队列前面仍有空间。但是使用循环队列,我们能使用这些空间去存储新的值。
你的实现应该支持如下操作:
MyCircularQueue(k): 构造器,设置队列长度为 k 。Front: 从队首获取元素。如果队列为空,返回 -1 。Rear: 获取队尾元素。如果队列为空,返回 -1 。enQueue(value): 向循环队列插入一个元素。如果成功插入则返回真。deQueue(): 从循环队列中删除一个元素。如果成功删除则返回真。isEmpty(): 检查循环队列是否为空。isFull(): 检查循环队列是否已满。
数据模型:
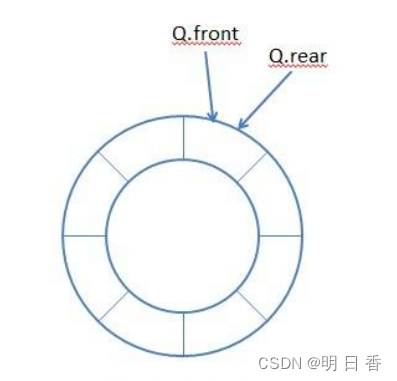
题目内容:

本题大意:
给予队列固定的长度值,当队列的长度等于固定的长度值后,任何的插入都无效,且队列进行出队后,并不会进行空间的释放(如果以链表形式创造),而出队后空下的空间会进行重复利用,以此达成循环要求。
思路分析:
对于本题的队列,我们有两种创建方式,第一种是数组为底层进行创建,第二种是以链表的形式进行创建。
如果是链表的形式,我们可以采取单链表或则双向链表,因为链表循环的独特优越性,我们会在插入删除创建的问题上方便很多,但是当我们在获取队尾元素的时候,就会十分的复杂,因为需要遍历。
而如果选择数组为底层进行创建,那么重点就是循环的体现和队列的空满表现。⭐
而对于本题,采取数组的方法较好一些。
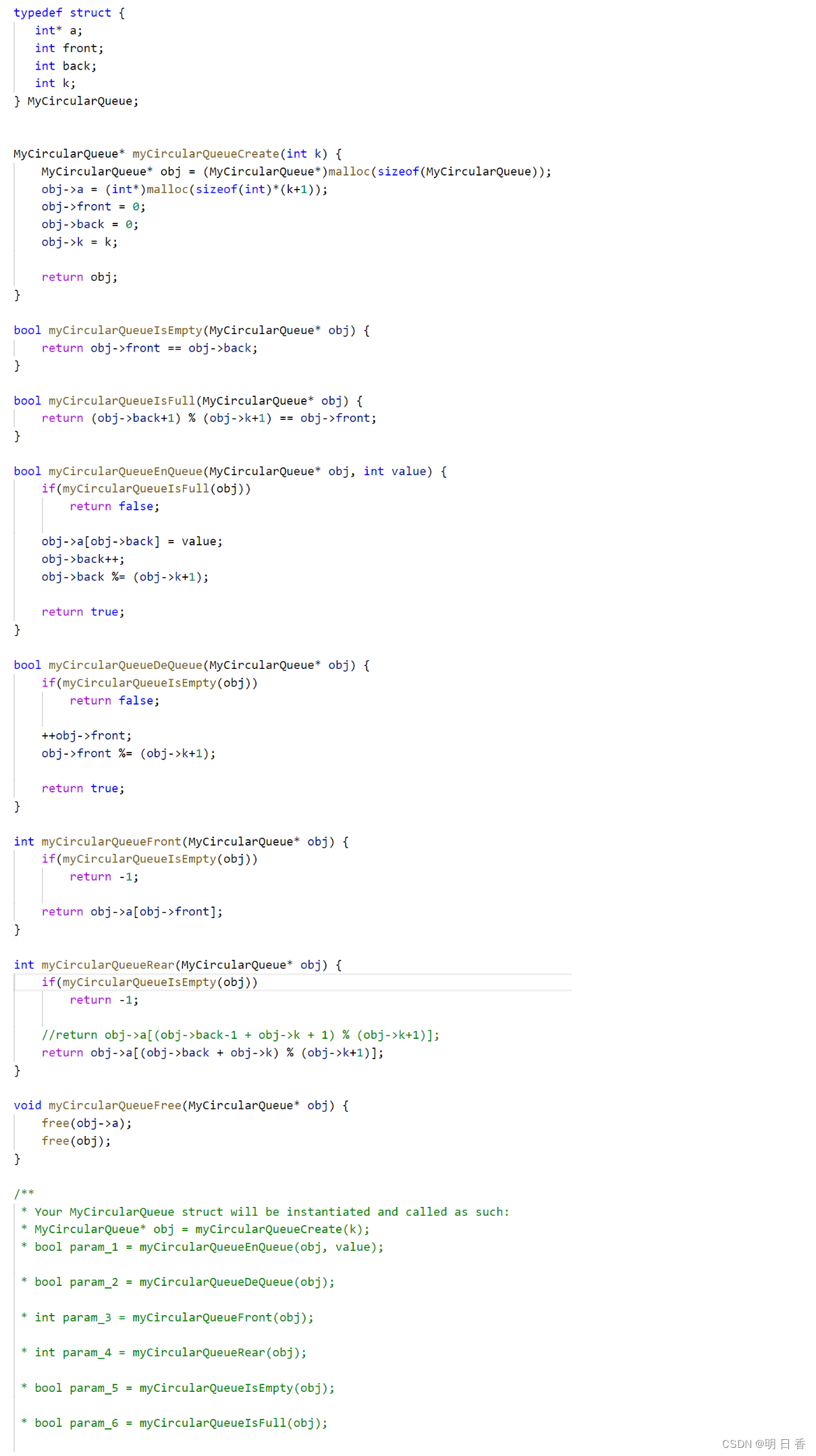
代码分析:
一、定义队列

- 因为,我们采取数组的方法解决问题,所以构建一个数组类型的结构体,也就是顺序表。
- 同时因为是队列,我们需要队头、队尾、又因为因为选择数组,所以设计一个数组的空间指针,因为由限定长度,所以设计一个长度限定K。
二、初始化、判断队列的空和满⭐
初始化:

关于队列的初始化,需要考虑一些问题:
- 队头和队尾指针,究竟代表的意思?
- 如何判断队列的空和满?
第一个问题:
- 因为本队列的底层是数组,所以back和 front 本质上是表示数组的下标,那么当我们进行初始化时,下标改如何定义?
- 如果定义front ==0 back ==0 那么当我们入队时,back 是否改前进?这个问题和之前栈的栈顶和栈底关系一样 栈和队列:栈-CSDN博客
- 所以,如果我们的初始化 back == 0那么back 表达的就是 队尾的后面一个位置的下标。
第二个问题:
- 队列的空和满其实分为两种状态,如果是没有进入循环的状态下,当front == back ==0时,可以表示队列是空的,即便back的意思是 队尾的后一个位置下标
- 但是当进入循环后,back == front == 0 后,其实可以表达队伍已经满了。
- 所以,对这种问题,我们可以采取两种方法,第一种是设置一个长度,当长度==0时表示空队列,当长度不等于空时则是满队列(仅限于在空满函数中进行)
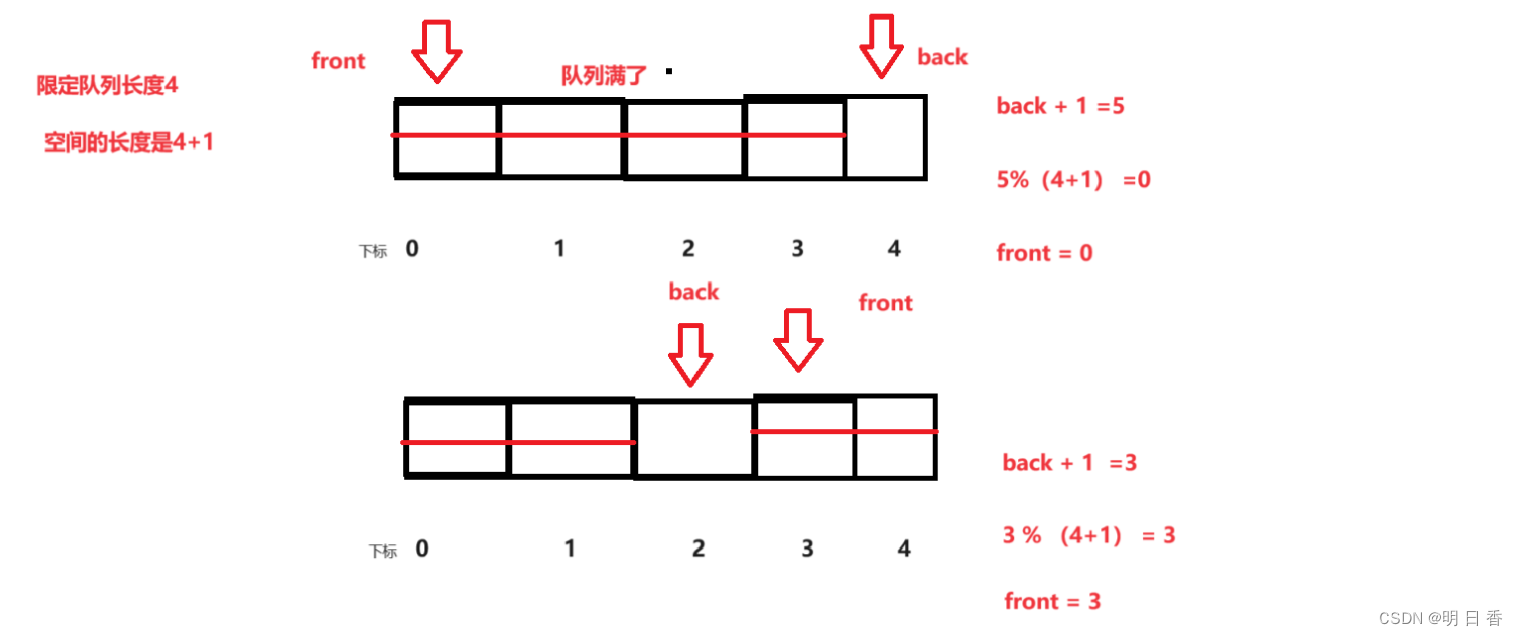
- 但是这种方法并不方便,于是我们设置了另一个方法,那就我们在初始化的时候可以多开一个位置
- 也就说如果题目要求我们的开辟能够存储四个元素的队列是,我们开辟五个空间,且多出的这个空间是可以进行存储数据的,那么我们的判断条件发生了改变。
空满的判断:
obj->front == obj->back;- 如果队列是空,那么back == front 是恒成立的,在开辟了一个空间后,队列满了之后,队头指针的队尾指针二者始终差距一步,这是因为多开辟了空间之后,空间的长度始终大于队列的长度,以及队尾指针back 指向的是队尾后面一个位置
(obj->back+1) % (obj->k+1) == obj->front;
- 如何判断是否是满?这里分了两种情况,第一种没有进入循环,也就说队头位置没有变化,队尾指针指向了最后一个下标位置,在这种情况下,队列满了。
- 第二种,在多次的插入和删除后,back指针在front指针前面一个位置,在这种情况下满了。
- 而这两种情况下,都有一个共同点!长度!
- 无论是进入循环前还是进入循环后,back指针所处在的位置(队尾后一个位置,数组是从0开始的)和空间的长度 进行 % 得出的结果如果和front 指针指向的位置一样,那么队列就满了!
- 主要是利用了 % 操作符的特点, 一个数 a % 比它大的数 b = 这个数本身 a
三、入队和出队🎇
入队:
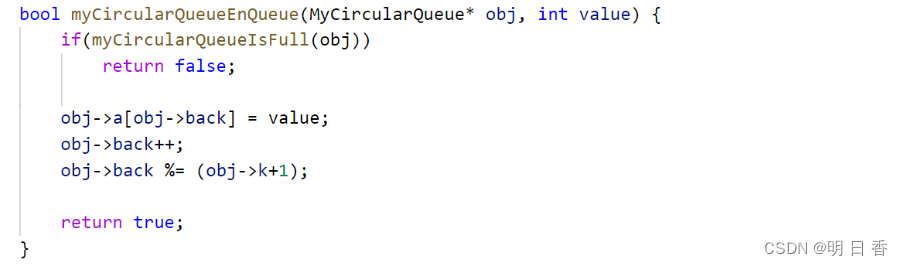
因为,back是指向队尾后一个位置,所以直接使用即可
但是因为题目要求插入成功为真,所以我们要进行判断,是不是队列满了于是我们就可以调用之前的判断是否满了的函数,且又因为会出现下图情况:
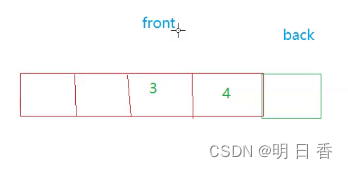
所以还需要对back的指向进行调整。
出队:

删除其实只需要移动队头指针就行了,当然需要由元素存在,所以还得判断是否是空的!
同时也需要注意循环的问题:
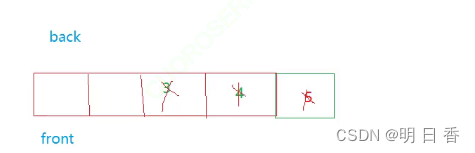
总结:
- 其实插入和删除面对循环的调整都是利用了 % 和循环的特点,++都会时front 和back 变大,而进入循环后,% 空间的大小 后得到的数字就相当于进入了循环后所处在的位置。
- 而如果++后front 和back 的数字都比空间大小 小,那么 % 后得到的数字还是他们本身,也就表示没有进入循环
四、获取队头元素和获取队尾元素
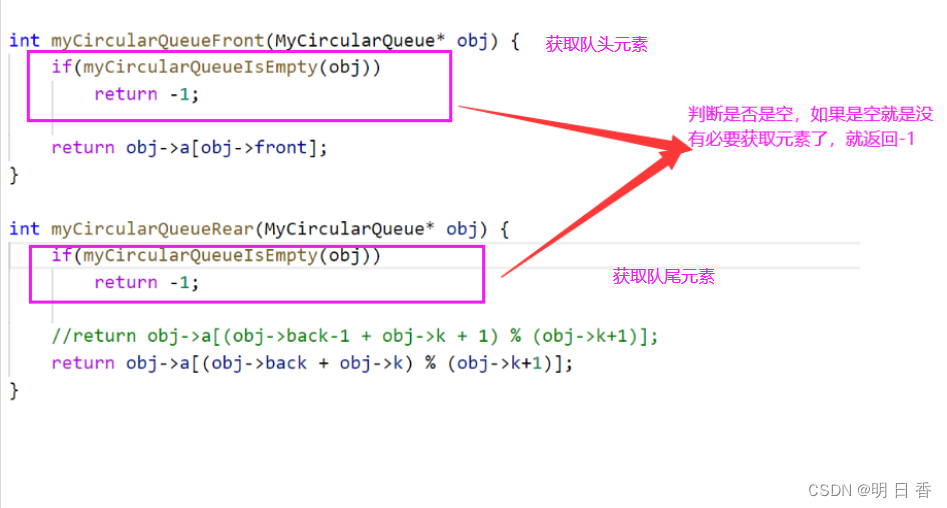
- 队头直接获取即可,因为队头不论如何移动都只是获取队头指针指向的元素
- 而获取队尾,则是要获取队尾指针指向的下标-1后的元素,所以关于队尾指针会有一些改动
关于队尾:

在正常情况下获取队尾是这样的
但是不正常情况,也就说循环后,back指针指向的是数组的0下标位置,当这个back-1后就是越界了而且这时候的队尾元素其实就是队列数组下标为k的元素

所以,这里再次利用了 % 的特点:一个数 a % 比它大的数 b = 这个数本身 a
- 所以如果我们进入了循环后或则进入循环前,这个back指针指向的下标是比空间长度小的,所以加上空间长度在%长度空间长度,得出的数字还是这个数
- 而如果back指向的是0,而再进来了-1后,再加上空间长度,%之后得出的就是数组的最后位置的数字最后位置的下标

五、销毁队列

完整代码:

-
相关阅读:
儿童口腔卫生:建立健康微笑的基石
Django 报错context must be a dict rather than Context.
会计学试题以及答案
[附源码]java毕业设计流浪动物救助系统
美国开源数据库ScyllaDB完成4300万美元融资
order by注入与limit注入
漫谈Python魔术方法,见过的没见过的都在这里了
Redis脑裂现象
Billie Eilish的XR音乐会和三星Galaxy发布会现场竟都是他们制作
Cplex求解教程(基于OPL语言,可作为大规模运算输入参考)
- 原文地址:https://blog.csdn.net/2301_76445610/article/details/134492874