-
Flink(七)【输出算子(Sink)】
前言
今天是我写博客的第 200 篇,恍惚间两年过去了,现在已经是大三的学长了。仍然记得两年前第一次写博客的时候,当时学的应该是 Java 语言,菜的一批,写了就删,怕被人看到丢脸。当时就想着自己一年之后,两年之后能学到什么水平,什么是 JDBC、什么是 MVC、SSM,在当时都是特别好奇的东西,不过都在后来的学习中慢慢接触到,并且好多已经烂熟于心了。
那,今天我在畅想一下,一年后的今天,我又学到了什么水平?能否达到三花聚顶、草木山石皆可为码的超凡入圣的境界?拿没拿到心仪的 offer?和那个心动过的女孩相处怎么样了?哈哈哈哈哈
输出算子(Sink)
学完了 Flink 在不同执行环境(本地测试环境和集群环境)下的多种读取(多种数据源)和转换操作(多种转换算子),最后就是输出操作了。

1、连接到外部系统
Flink 1.12 之前,Sink 算子是通过调用 DataStream 的 addSink 方法来实现的:
stream.addSink(new SinkFunction(...));从 Flink 1.12 开始,Flink 重构了 Sink 架构:
stream.sinkTo(...)需要我们自己导入依赖,比如上面的 Kfaka 和 DataGen 我们之前使用的时候都导入过相关依赖,需要知道,有的是只支持source,有的只支持sink,有的全都支持。
- <dependency>
- <groupId>org.apache.flinkgroupId>
- <artifactId>flink-connector-kafkaartifactId>
- <version>${flink.version}version>
- dependency>
- <dependency>
- <groupId>org.apache.flinkgroupId>
- <artifactId>flink-connector-datagenartifactId>
- <version>${flink.version}version>
- dependency>
2、输出到文件
Flink 专门提供了一个流式文件系统的连接器:FileSink,为批处理和流处理提供了一个统一的 Sink,它可以将分区文件写入 Flink支持的文件系统。
它的主要操作是将数据写入桶(buckets),每个桶中的数据都可以分割成一个个大小有限的分区文件,这样一来就实现真正意义上的分布式文件存储。我们可以通过各种配置来控制“分桶”的操作;默认的分桶方式是基于时间的,我们每小时写入一个新的桶。换句话说,每个桶内保存的文件,记录的都是 1 小时的输出数据。
FileSink 支持行编码(Row-encoded)和批量编码(Bulk-encoded,比如 Parquet)格式。这两种不同的方式都有各自的构建器(builder),调用方法也非常简单,可以直接调用 FileSink 的静态方法:- 行编码:FileSink.forRowFormat(basePath,rowEncoder)。
- 批量编码:FileSink.forBulkFormat(basePath,bulkWriterFactory)。
在创建行或批量编码 Sink 时,我们需要传入两个参数,用来指定存储桶的基本路径(basePath)和数据的编码逻辑(rowEncoder 或 bulkWriterFactory)。
- package com.lyh.sink;
- import org.apache.flink.api.common.eventtime.WatermarkStrategy;
- import org.apache.flink.api.common.serialization.SimpleStringEncoder;
- import org.apache.flink.api.common.typeinfo.TypeInformation;
- import org.apache.flink.api.common.typeinfo.Types;
- import org.apache.flink.api.connector.source.util.ratelimit.RateLimiterStrategy;
- import org.apache.flink.configuration.MemorySize;
- import org.apache.flink.connector.datagen.source.DataGeneratorSource;
- import org.apache.flink.connector.datagen.source.GeneratorFunction;
- import org.apache.flink.connector.file.sink.FileSink;
- import org.apache.flink.core.fs.Path;
- import org.apache.flink.streaming.api.CheckpointingMode;
- import org.apache.flink.streaming.api.datastream.DataStreamSource;
- import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
- import org.apache.flink.streaming.api.functions.sink.filesystem.OutputFileConfig;
- import org.apache.flink.streaming.api.functions.sink.filesystem.bucketassigners.DateTimeBucketAssigner;
- import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy;
- import java.time.Duration;
- import java.time.ZoneId;
- /**
- * @author 刘xx
- * @version 1.0
- * @date 2023-11-18 9:51
- */
- public class SinkFile {
- public static void main(String[] args) throws Exception {
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
- env.setParallelism(2);
- // 必须开启 检查点 不然一直都是 .inprogress
- env.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE);
- DataGeneratorSource
dataGeneratorSource = new DataGeneratorSource ( - new GeneratorFunction
- @Override
- public String map(Long value) throws Exception {
- return "Number:"+value;
- }
- },
- Long.MAX_VALUE,
- RateLimiterStrategy.perSecond(10), // 每s 10条
- Types.STRING
- );
- DataStreamSource
dataGen = env.fromSource(dataGeneratorSource, WatermarkStrategy.noWatermarks(), "data-generate"); - // todo 输出到文件系统
- FileSink
fileSink = FileSink. - // 泛型方法 需要和输出结果的泛型保持一致
forRowFormat( - new Path("D:/Desktop"), // 指定输出路径 可以是 hdfs:// 路径
- new SimpleStringEncoder<>("UTF-8")) // 指定编码
- .withOutputFileConfig(OutputFileConfig.builder()
- .withPartPrefix("lyh")
- .withPartSuffix(".log")
- .build())
- // 按照目录分桶 一个小时一个目录(这里的时间格式别改为分钟 会报错: flink Relative path in absolute URI:)
- .withBucketAssigner(new DateTimeBucketAssigner<>("yyyy-MM-dd HH", ZoneId.systemDefault()))
- // 设置文件滚动策略-时间或者大小 10s 或 1KB 或 5min内没有新数据写入 滚动一次
- // 滚动的时候 文件就会更名为我们设定的格式(前缀)不再写入
- .withRollingPolicy(
- DefaultRollingPolicy.builder()
- .withRolloverInterval(Duration.ofSeconds(10L)) // 10s
- .withMaxPartSize(new MemorySize(1024)) // 1KB
- .withInactivityInterval(Duration.ofMinutes(5)) // 5min
- .build()
- )
- .build();
- dataGen.sinkTo(fileSink);
- env.execute();
- }
- }
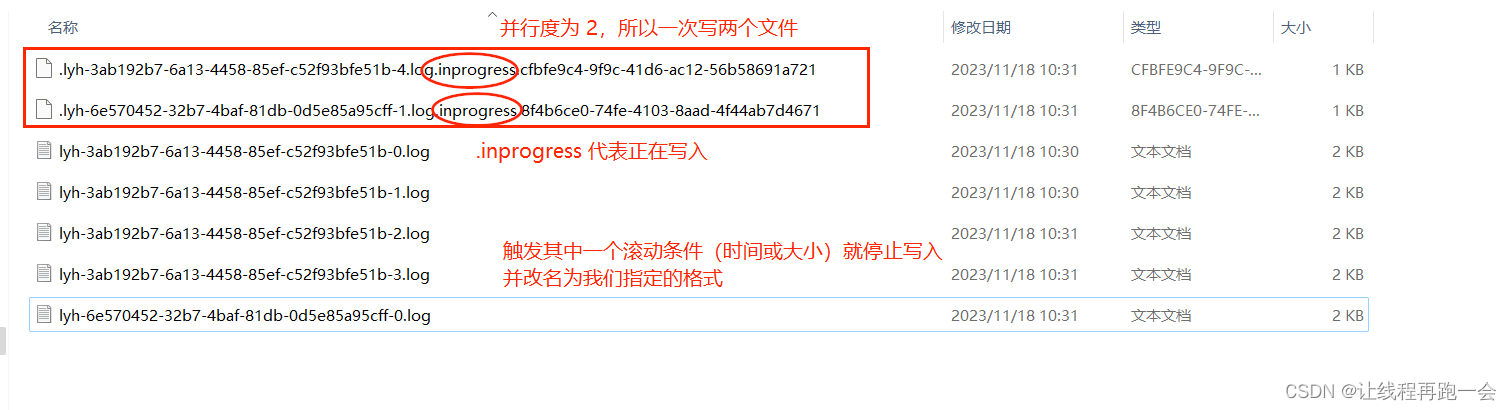
这里我们创建了一个简单的文件 Sink,通过.withRollingPolicy()方法指定了一个“滚动策略”。“滚动”的概念在日志文件的写入中经常遇到:因为文件会有内容持续不断地写入,所以我们应该给一个标准,到什么时候就开启新的文件,将之前的内容归档保存。也就是说,上面的代码设置了在以下 3 种情况下,我们就会滚动分区文件:
⚫ 至少包含 10 秒的数据
⚫ 最近 5 分钟没有收到新的数据
⚫ 文件大小已达到 1 KB通过 withOutputFileConfig()方法指定了输出的文件名前缀和后缀。
需要特别注意的就是一定要开启检查点,否则我们的数据一直都是正在写入的状态(具体原因后面学习到检查点的时候会详细说)。
运行结果:
3、输出到 Kafka
- 需要添加 Kafka 依赖(之前导入过了)
- 启动 Kafka
- 编写示例代码
- package com.lyh.sink;
- import org.apache.flink.api.common.serialization.SimpleStringSchema;
- import org.apache.flink.connector.base.DeliveryGuarantee;
- import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
- import org.apache.flink.connector.kafka.sink.KafkaSink;
- import org.apache.flink.streaming.api.CheckpointingMode;
- import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
- import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
- import org.apache.kafka.clients.producer.ProducerConfig;
- /**
- * @author 刘xx
- * @version 1.0
- * @date 2023-11-18 11:20
- */
- public class SinkKafka {
- public static void main(String[] args) throws Exception {
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
- env.setParallelism(1);
- // 如果是 精准一次 必须开启 checkpoint
- env.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE);
- SingleOutputStreamOperator
sensorDS = env.socketTextStream("localhost", 9999); - KafkaSink
kafkaSink = KafkaSink. builder() - // 指定 kafka 的地址和端口
- .setBootstrapServers("hadoop102:9092,hadoop103:9092,hadoop104:9092")
- // 指定序列化器 我们是发送方 所以我们是生产者
- .setRecordSerializer(
- KafkaRecordSerializationSchema.
builder() - .setTopic("like")
- .setValueSerializationSchema(new SimpleStringSchema())
- .build()
- )
- // 写到 kafka 的一致性级别: 精准一次 / 至少一次
- // 如果是精准一次
- // 1.必须开启检查点 env.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE)
- // 2.必须设置事务的前缀
- // 3.必须设置事务的超时时间: 大于 checkpoint间隔 小于 max 15分钟
- .setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
- .setTransactionalIdPrefix("lyh-")
- .setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG,10*60*1000+"")
- .build();
- sensorDS.sinkTo(kafkaSink);
- env.execute();
- }
- }
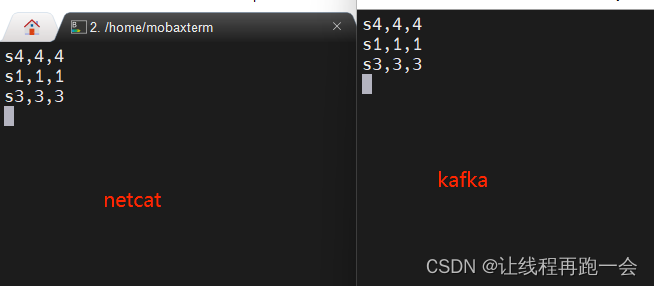
启动 kafka 并开启一个消费者:
kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic like运行结果:

需要特别注意的三点:
如果是精准一次 1.必须开启检查点 env.enableCheckpointing(2000, CheckpointingMode.EXACTLY_ONCE) 2.必须设置事务的前缀 3.必须设置事务的超时时间: 大于 checkpoint间隔 小于 max 15分钟
自定义序列化器
我们上面用的自带的序列化器,但是如果我们有 key 的话,就需要自定义序列化器了,替换上面的代码:
- .setRecordSerializer(
- /**
- * 如果要指定写入 kafka 的key 就需要自定义序列化器
- * 实现一个接口 重写序列化方法
- * 指定key 转为 bytes[]
- * 指定value 转为 bytes[]
- * 返回一个 ProducerRecord(topic名,key,value)对象
- */
- new KafkaRecordSerializationSchema
() { - @Nullable
- @Override
- // ProducerRecord
- public ProducerRecord<byte[], byte[]> serialize(String element, KafkaSinkContext context, Long timestamp) {
- String[] datas = element.split(",");
- byte[] key = datas[0].getBytes(StandardCharsets.UTF_8);
- byte[] value = element.getBytes(StandardCharsets.UTF_8);
- return new ProducerRecord<>("like",key,value);
- }
- }
- )
运行结果:
4、输出到 MySQL
添加依赖(1.17版本的依赖需要指定仓库才能找到,因为阿里云和默认的maven仓库是没有的):
- <dependency>
- <groupId>org.apache.flinkgroupId>
- <artifactId>flink-connector-jdbcartifactId>
- <version>1.17-SNAPSHOTversion>
- dependency>
- <dependency>
- <groupId>mysqlgroupId>
- <artifactId>mysql-connector-javaartifactId>
- <version>8.0.31version>
- dependency>
- ....
- <repositories>
- <repository>
- <id>apache-snapshotsid>
- <name>apache snapshotsname>
- <url>https://repository.apache.org/content/repositories/snapshots/url>
- repository>
- repositories>
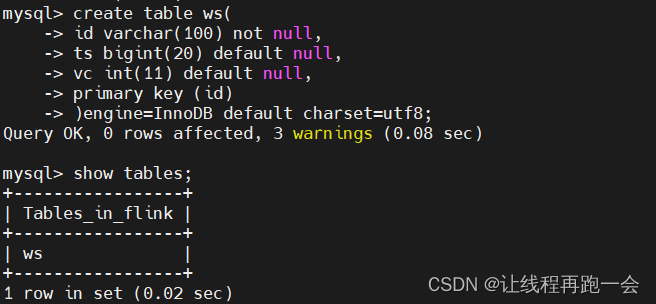
创建表格
编写代码,将输入的数据行分隔为对象参数,每行数据生成一个对象进行处理。
- package com.lyh.sink;
- import com.lyh.bean.WaterSensor;
- import function.WaterSensorFunction;
- import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
- import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
- import org.apache.flink.connector.jdbc.JdbcSink;
- import org.apache.flink.connector.jdbc.JdbcStatementBuilder;
- import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
- import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
- import org.apache.flink.streaming.api.functions.sink.SinkFunction;
- import java.sql.PreparedStatement;
- import java.sql.SQLException;
- /**
- * @author 刘xx
- * @version 1.0
- * @date 2023-11-18 12:32
- */
- public class SinkMySQL {
- public static void main(String[] args) throws Exception {
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
- env.setParallelism(1);
- SingleOutputStreamOperator
sensorDS = env.socketTextStream("localhost", 9999) - .map(new WaterSensorFunction()); //输入进来的数据自动转为 WaterSensor类型
- /**
- * todo 写入 mysql
- * 1.这里需要用旧的sink写法:addSink
- * 2.JDBC的4个参数
- * (1) 执行的sql语句
- * (2) 对占位符进行填充
- * (3) 执行选项 -> 攒批,重试
- * (4) 连接选项 -> driver,username,password,url
- */
- SinkFunction
jdbcSink = JdbcSink.sink("insert into flink.ws values(?,?,?)", - // 指定 sql 中占位符的值
- new JdbcStatementBuilder
() { - @Override
- public void accept(PreparedStatement stmt, WaterSensor sensor) throws SQLException {
- // 占位符从 1 开始
- stmt.setString(1, sensor.getId());
- stmt.setLong(2, sensor.getTs());
- stmt.setInt(3, sensor.getVc());
- }
- }, JdbcExecutionOptions.builder()
- .withMaxRetries(3) //最多重试3次(不包括第一次,共4次)
- .withBatchSize(100) //每收集100条记录进行一次写入
- .withBatchIntervalMs(3000) // 批次3s(即使没有达到100条记录,只要过了3s JDBCSink也会进行记录的写入),这有助于确保数据及时写入,而不是无限期地等待批处理大小达到。
- .build()
- , new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
- .withUrl("jdbc:mysql://localhost:3306/flink?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8")
- .withDriverName("com.mysql.cj.jdbc.Driver")
- .withUsername("root")
- .withPassword("Yan1029.")
- // mysql 默认8小时不使用连接就主动断开连接
- .withConnectionCheckTimeoutSeconds(60) // 重试连接直接的间隔,上面我们设置最多重试3次,每次间隔60s
- .build()
- );
- sensorDS.addSink(jdbcSink);
- env.execute();
- }
- }
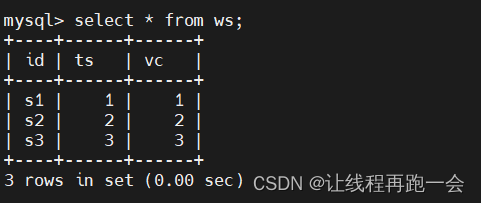
查询结果:
5、自定义 Sink 输出
与 Source 类似,Flink 为我们提供了通用的 SinkFunction 接口和对应的 RichSinkDunction抽象类,只要实现它,通过简单地调用 DataStream 的.addSink()方法就可以自定义写入任何外部存储。
这里我们自定义实现一个向 HBase 中插入数据的 Sink。
注意:这里只是做一个简单的 Demo,下面的代码不难发现,我们只是对 nosq:student 表下的 info:name 进行了两次的覆盖。如果要实现复杂的处理功能,需要对数据类型进行定义,因为 HBase 的数据是按列存储的,所以对于复杂的 Hbase 表,我们难以通过 Java bean 来插入数据。而且,一般经常用的连接器,Flink 大部分已经提供了,开发中我们一般也很少自定义 Sink 输出。
- package com.lyh.sink;
- import com.lyh.utils.HBaseConnection;
- import org.apache.flink.configuration.Configuration;
- import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
- import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
- import org.apache.hadoop.hbase.TableName;
- import org.apache.hadoop.hbase.client.Connection;
- import org.apache.hadoop.hbase.client.Put;
- import org.apache.hadoop.hbase.client.Table;
- import java.nio.charset.StandardCharsets;
- /**
- * @author 刘xx
- * @version 1.0
- * @date 2023-11-18 15:59
- */
- public class SinkCustomHBase {
- public static void main(String[] args) throws Exception {
- StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
- env.setParallelism(1);
- env.fromElements("tom","bob").addSink(new RichSinkFunction
() { - public Connection con;
- @Override
- public void open(Configuration parameters) throws Exception {
- super.open(parameters);
- con = HBaseConnection.getConnection("hadoop102:2181");
- }
- @Override
- public void invoke(String value, Context context) throws Exception {
- super.invoke(value, context);
- Table table = con.getTable(TableName.valueOf("nosql","student"));
- Put put = new Put("1001".getBytes(StandardCharsets.UTF_8));
- put.addColumn("info".getBytes(StandardCharsets.UTF_8)
- ,"name".getBytes(StandardCharsets.UTF_8),
- value.getBytes(StandardCharsets.UTF_8));
- table.put(put);
- table.close();
- }
- @Override
- public void close() throws Exception {
- super.close();
- HBaseConnection.close();
- }
- });
- env.execute();
- }
- }
这里用到一个简单的连接 HBase 的工具类:
- package com.lyh.utils;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.hbase.client.Connection;
- import org.apache.hadoop.hbase.client.ConnectionFactory;
- import java.io.IOException;
- /**
- * @author 刘xx
- * @version 1.0
- * @date 2023-11-18 16:04
- */
- public class HBaseConnection {
- private static Connection connection;
- public static Connection getConnection(String hosts) throws IOException {
- Configuration conf = new Configuration();
- conf.set("hbase.zookeeper.quorum", hosts);
- conf.setInt("hbase.rpc.timeout", 10000); // 设置最大超时 10 s
- connection = ConnectionFactory.createConnection(conf);
- return connection;
- }
- public static void close() throws IOException {
- if (connection!=null)
- connection.close();
- }
- }
-
相关阅读:
chatgpt论文润色 & 降重
Matplotlib数据可视化基础
油溶性CdSeTe/ZnS量子点,发光波长640nm-820nm
【算法竞赛】【模式串匹配算法(KMP)】【附带模板题】
redis漏洞修复:CVE-2022-35977、CVE-2023-22458、CVE-2023-28856
【Silvaco example】GaN diode, Reverse-bias leakage current vs temperature
MySQ 学习笔记
openssl之中文手册
利用各种命令取网卡ip地址
RedisJson发布官方性能报告,性能碾压ES和Mongo
- 原文地址:https://blog.csdn.net/m0_64261982/article/details/134474275
