-
Python字符编码
一.引入
1.字符编码知识储备:
三大核心硬件:所有软件都是运行硬件之上的,与运行软件相关的三大核心硬件为cpu、内存、硬盘,我们需要明确三点
#1、软件运行前,软件的代码及其相关数据都是存放于硬盘中的
#2、任何软件的启动都是将数据从硬盘中读入内存,然后cpu从内存中取出指令并执行
#3、软件运行过程中产生的数据最先都是存放于内存中的,若想永久保存软件产生的数据, 则需要将数据由内存写入硬盘
2.文本编辑器读取文件内容的流程:
阶段一:启动一个文件编辑器(文本编辑器如pycharm,word,nodepad++等)
阶段二:文件编辑器会将文件内容从硬盘读取到内存中
阶段三:文本编辑器会将内存里的内容显示到屏幕上
二.介绍
1.字符编码的前提:
-
它只跟字符类型和文本类型相关,跟视频文件、音频文件、图片文件等无关
-
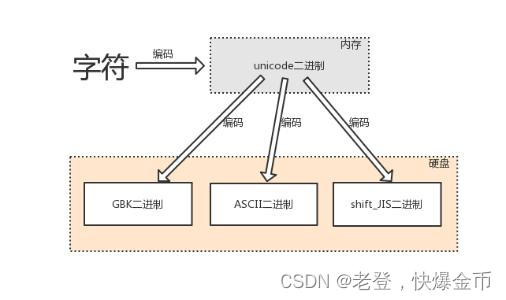
计算机内部只能够认识二进制01,计算机之所以能够认识各种各样的字符,那是因为计算机的内部维护着一张字符编码表
2.什么是字符编码表:
字符编码表就是一些字符和数字之间的对应关系,二进制数即由0和1组成的数字,例如010010101010。计算机是基于电工作的,电的特性即高低电平,人类从逻辑层面将高电平对应为数字1,低电平对应为数字0,这直接决定了计算机可以识别的是由0和1组成的数字
三.字符编码的发展史:
1.一家独大:
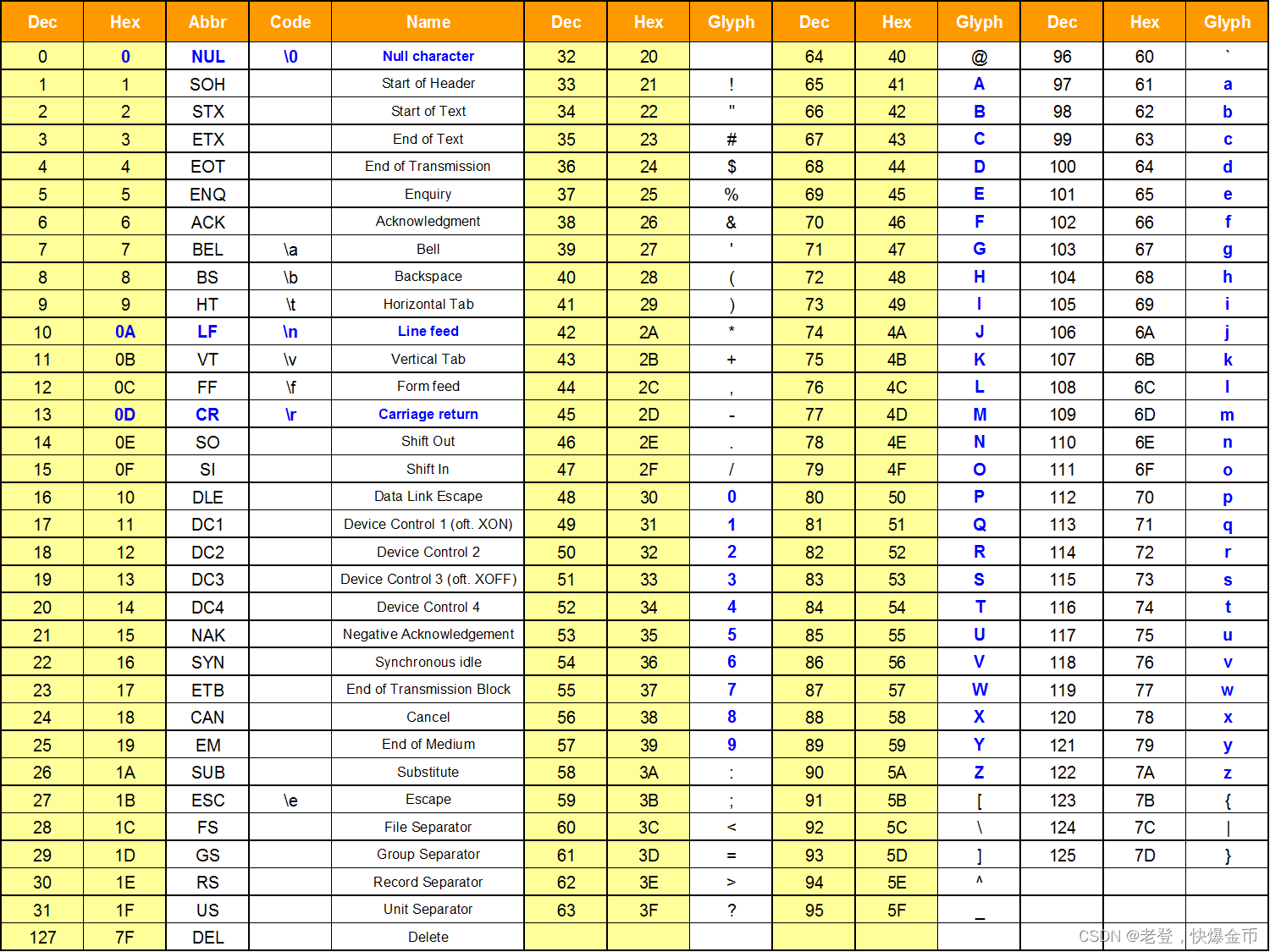
由于计算机是漂亮国搞出来的,于是他们研究出了ASCII码表用来对应英文与数字之间的关系
ASCII码表统一使用的是一个字节保存一个字符(1个字节是8位),8位二进制能够表示256个字符
2.群雄割据
中国为了使用计算机于是研究出了GBK码表,GBK码表内部记录了英文、中文和数字之间的关系
不光中国,其他的国家也都研究出了各自国家的字符编码表
但是,有这么多字符编码表不同国家的人为了识别不同国家的语言要使用不同的字符编码表,这样实在太麻烦了,于是出现了万国码
3.天下统一
为了全世界都能够使用统一的计算机识别全世界的语言,把字符编码表统一了,这就是unicode(万国码)
万国码统一使用的是两个字节来保存字符,但是英文由原本的1个字节保存1个字符变成了2个字节保存1个字符,这样大大浪费了空间
为了节省空间,内存里使用的万国码到硬盘里的utf-8字符
utf-8就是现在大家统一使用的一种编码:
-
统一使用1个字节保存1个英文字符
-
统一使用3个字节保存中文字符
三.字符编码实战
1.如何解决乱码问题:
写文件时用的什么编码那么打开的时候就用什么编码
2.Python解释器版本不同,代码的编码问题:
Python2中使用的不是utf-8,而是ASCII
3.如何编码和解码
编码:把人类能够读懂的字符转化为计算机能够识别的数字(二进制)
解码:把计算机能够读懂的数字转化为人类能够读懂的字符

- # 编码
- res = '俺是凯文'
- print(res.encode('utf-8')) # b'\xe4\xbf\xba\xe6\x98\xaf\xe5\x87\xaf\xe6\x96\x87' bytes
- # 解码
- res1 = res.encode('utf-8')
- print(res1.decode('utf-8')) # 俺是凯文
tip:如果不知道对方用什么编码器写的,那么可以试试 utf-8 或者 GBK
-
-
相关阅读:
C#里实现简单的异步TCP服务器
贪心算法(四) | 加油站、单调递增的数字、监控二叉树 | leecode刷题笔记
YOLOV8模型改进-添加CBAM注意力机制
一文详解TCP三次握手四次挥手
在Windows上使用.NET部署到Docker 《让孩子们走出大坑》
常见排序算法
5个 GIS空间分析 空间查询与量算 的重要知识点
源代码开发企业要如何进行代码加密,自主知识产权维护刻不容缓
ProcessEngineEndpoint
【从零带你玩转Linux】Linux环境搭建
- 原文地址:https://blog.csdn.net/qq_65852978/article/details/132623577