-
生成对抗网络Generative Adversarial Network,GAN
Basic Idea of GAN
- Generation(生成器)
Generation是一个neural network,它的输入是一个vector,它的输出是一个更高维的vector,以图片生成为例,输出就是一张图片,其中每个维度的值代表生成图片的某种特征。
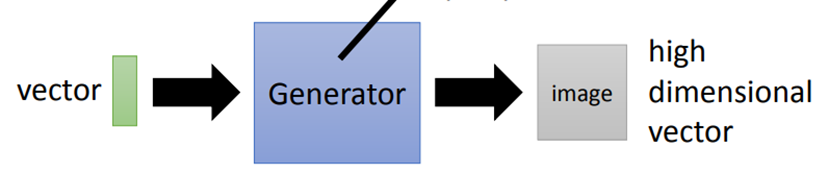

- Discriminator(判别器)
Discriminator也是一个neural network,它的输入是一张图片,输出是一个scalar,scalar的数值越大说明这张图片越像真实的图片。

- Generation和Discriminator两者的关系
举了鸟和蝴蝶例子说明Generation和Discriminator之间的关系是相互对抗,相互提高。然后提出两个问题:
- Generator为什么不自己学,还需要Discriminator来指导。
- Discriminator为什么不自己直接做。
Algorithm(算法说明)
首先要随机初始化generator 、discriminator的参数;
然后在每一个training iteration要做两件事:
(1)固定generator的参数,然后只训练discriminator。
将generator生成的图片与从database sample出来的图片放入discriminator中训练,如果是generator生成的图片就给低分,从database sample出来的图片就给高分。

(2)固定discriminator的参数,然后只训练generator。
把generator生成的图片当做discriminator的输入,训练目标是让输出越大越好。
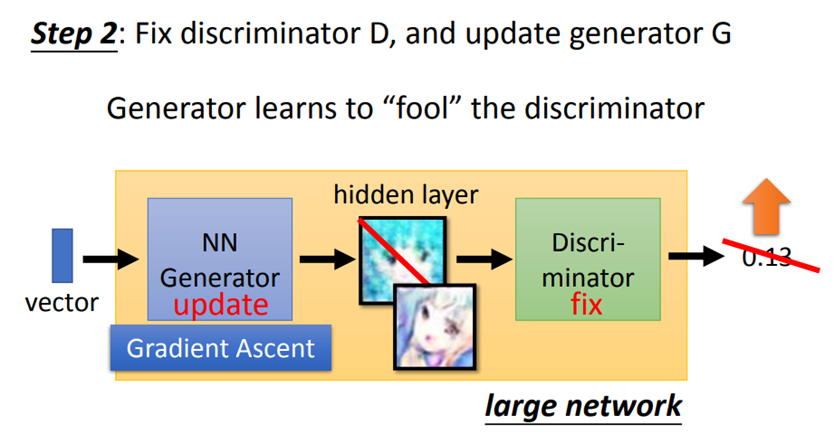
具体算法如下:
训练D(固定G):
- 首先从database中抽取m个样本。
- 从一个分布中抽取m个vector z。
- 将z输入generator,生成m张图片x 。
- 计算损失,最大化损失。
训练G(固定D):
- 随机产生m个噪声,通过generator得到图片G(z);
- 然后经过discriminator得到D(G(z)),更改G中的参数,使得它的得分越高越好。

GAN as structured learning
结构化学习的输入和输出多种多样,可以是序列(sequence)到序列,序列到矩阵(matrix),矩阵到图(graph),图到树(tree)等。例如,机器翻译、语音识别、聊天机器人、文本转图像等。GAN也是结构化学习的一种。
- Structured Learning面临的挑战
- One-shot/Zero-shot Learning:比如在分类任务中,有些类别没有数据或者有很少的数据。
- 机器需要创造新的东西。如果把每个可能的输出都视为一个“class”,由于输出空间很大,大多数“class”都没有训练数据,也,这就导致了机器必须在testing时创造新的东西。
- 机器需要有规划的概念,要有大局观。因为输出组件具有依赖性,所以应全局考虑它们。
- Structured Learning Approach
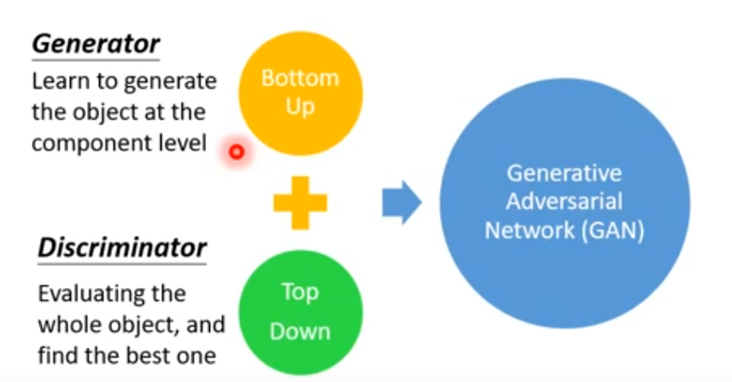
传统的structured learning主要有两种做法:Bottom up 和 Top down。
Bottom up:机器逐个产生object的component。
Top down:从整体来评价产生的component的好坏。
Generator可以视为是一个Bottom Up的方法,discriminator可以视为是一个Top Down的方法,把这两个方法结合起来就是GAN。
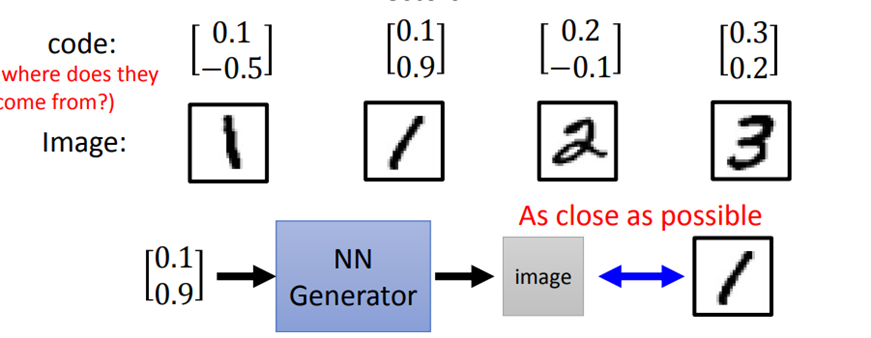
Can Generator learn by itself
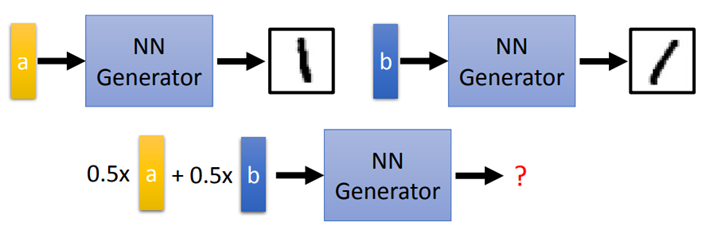
可以用监督学习的方法来对generator进行训练,但是还会存在一个问题:表示图片的code从哪里来。如果随机产生,训练起来可能非常困难。因为如果两种图片很像,它们输入vector差异很大的话,就很难去训练。
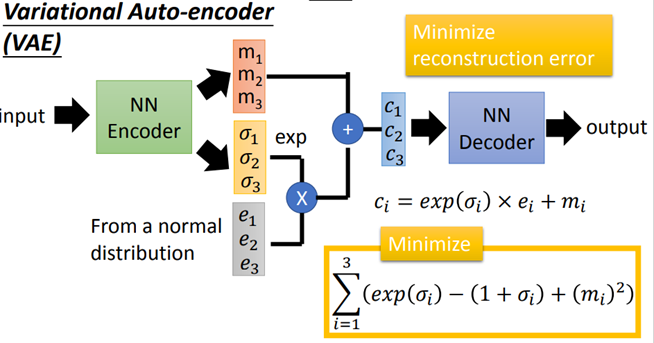
可以通过训练一个encoder,得到相应的code。但是存在的问题就是:Vector a 输出结果是向左的1,vector b 输出结果是向右的1。若把a、b平均作为输入,则输出不一定是数字,可以使用VAE来解决这个问题。
VAE不仅产生一个code还会产生每一个维度的方差;然后将方差和正态分布中抽取的噪声进行相乘,之后加上code上去,就相当于加上noise的code。
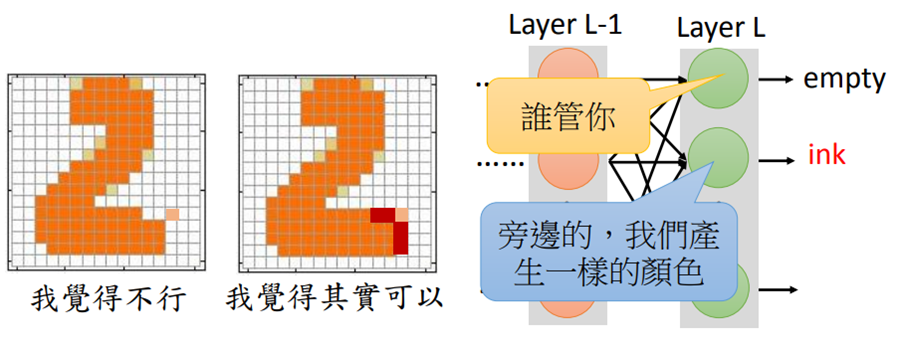
在生成图片时,不是单纯的让生成结果与真实结果越接近越好,还要保证整幅图片符合现实规律。

假设Layer L-1的值是给定的,则Layer L每一个dimension的输出都是独立的,无法相互影响。因此只有在L后面在加几个隐藏层,才可以调整第L层的神经元输出。也就是说,VAE要想获得GAN的效果,它的网络要比GAN要深才行。
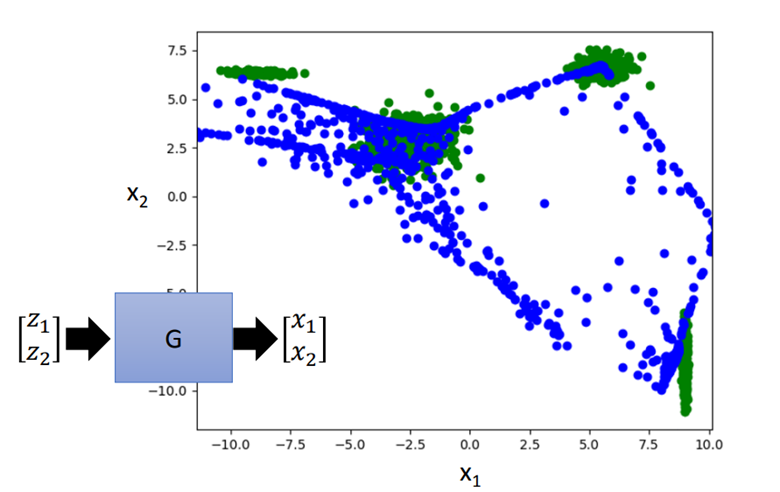
下图中绿色是目标,蓝色是VAE学习的结果。VAE在做一些离散的目标效果不好。
Can Discriminator generate
Discriminator就是给定一个输入,输出一个分数。对discriminator来说,要考虑component和component之间的联系就比较容易。比如有一个滤波器,它会去检索有没有独立的像素点,有的话就是低分。
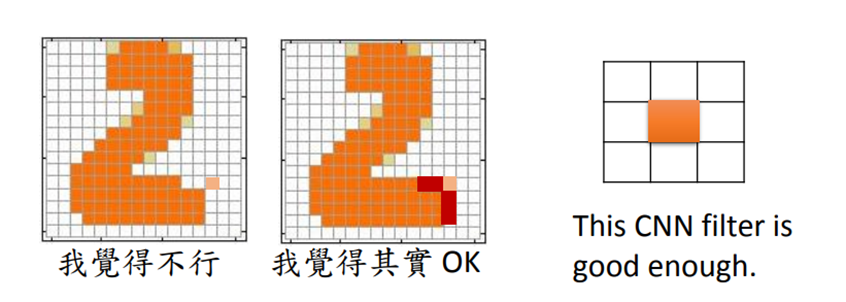
假如有一个discriminator,它能够鉴别图片的好坏,就可以用这个discriminator去生成图片。穷举所有的输入x,比较discriminator给出的分数,找到分数最高的就是discriminator的生成结果。
- 训练discriminator
- 首先给定一些正样本,随机产生一些负样本。
- 在每一个iteration里面,训练出discriminator能够鉴别正负样本。
- 然后用训练出来的discriminator生成图片当做负样本。
- 开始迭代。

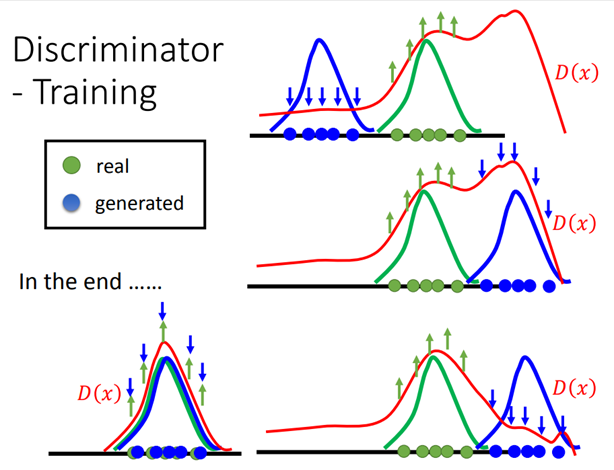
从可视化和概率的角度来看一下整个过程。蓝色的是discriminator生成图片的分布,绿色的是真实图片分布。训练discriminator给绿色的高分,蓝色的低分。然后寻找discriminator除了真实图片之外,得分最大高的地方把它变成负样反复迭代,最终正样本和负样本就会重合在一起。
- Generator v.s. Discriminator
generator:很容易生成图片,但是它不考虑component之间的联系。只学到了目标的表象,没有学到精神。
Discriminator:能够考虑大局,但是很难生成图片。
- Generator + Discriminator
Generator就是取代了这个argmax的过程。GAN的优点如下:
从discriminator来看,利用generator去生成样本,去求解argmax问题,更加有效。
从generator来看,虽然在生成图片过程中的像素之间依然没有联系,但是它的图片好坏是由有大局观的discriminator来判断的。从而能够学到有大局观的generator。
-
相关阅读:
IO流【】【】【】
深信服C++ 三面(技术面、30min、offer)
【Linux开发】Linux中uboot的常用命令及环境变量大全
如何在GitHub正确提PR(Pull Requests),给喜欢的开源项目贡献代码
【Python 自动化办公】docx module 的坑
vtk 动画入门 1 代码
【AHK】 MacOS复制粘贴习惯/MacOS转win键位使用习惯修改建议
恶意攻击和可解释性
“益路同行”栏目专访第12期——泰格智能AI英语·李勤骞老师
基于Java的设计模式-观察者模式
- 原文地址:https://blog.csdn.net/qq_51426525/article/details/134455284