-
【C语言】深入理解数据表示与存储
计算机内存是存储数据的重要组成部分。了解数据在内存中的存储方式对于理解计算机的工作原理和进行优化至关重要。本文将介绍数据在内存中的存储方式,并通过一个程序来说明:int main() { unsigned short i = 65535; int j = -2147483648; int k = 65536; char c1 = '\n', c2 = 'x'; float x = 100.25671; double y = 567.89; char* str = "01as计算机\n01as\\"; printf("%u\n", j); printf("%f\n", x); printf("%lf\n", y); printf("%s\n", str); printf("%d\n", i * i); return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
1.分析上述源程序中的变量在机器内是如何表示的
1.1.并给出变量在内存中的存储情况(变量占多少个字节,每个字节的地址和存放的数据是多少)
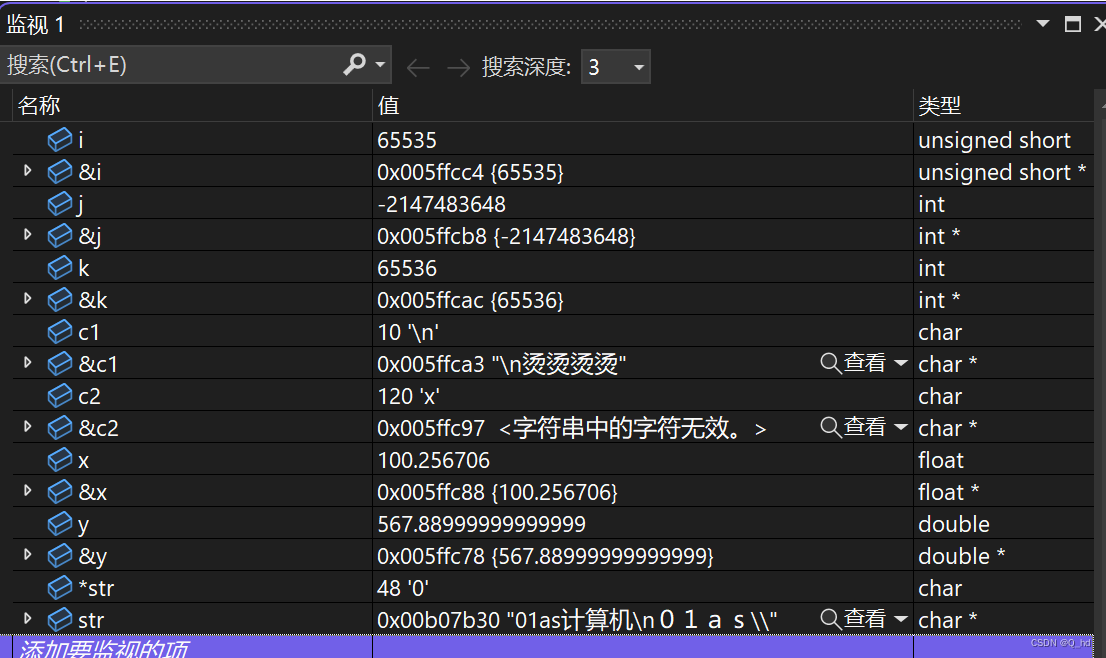
unsigned short i = 65535;- 1
int j = -2147483648;- 1

int k = 65536;- 1

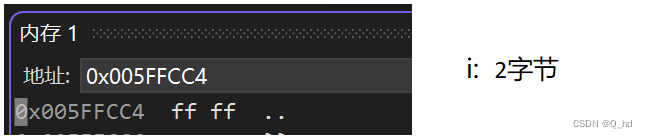
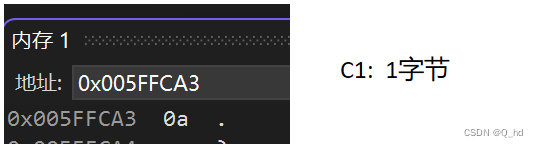
char c1 = '\n', c2 = 'x';- 1
float x = 100.25671;- 1

double y = 567.89;- 1

char* str = "01as计算机\n01as\\";- 1

1.2.说明其存放顺序(大端、小端次序?)
我们可以看到
j在内存中的存储:int j = -2147483648;- 1
在补码表示法中
-2147483648的二进制表示为:
1000 0000 0000 0000 0000 0000 0000 0000
在32位系统中,int类型通常占用4个字节,因此在内存中以小端模式存储时,-2147483648会以00 00 00 80的形式存储。低位字节存储在低地址,高位字节存储在高地址,所以我的机器是小端模式。1.3.对齐方式(是否采用边界对齐,如何对齐)
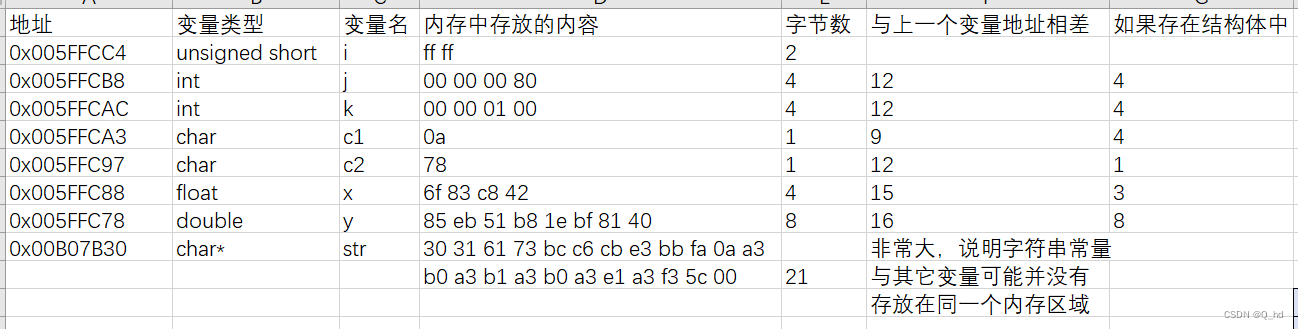
unsigned short i: 占用2个字节,存储方式为小端序,即低地址存放低位,高地址存放高位,无需对齐。int j: 占用4个字节,以补码形式存储,最小值-2147483648以补码形式存储为0x80000000,采用边界对齐。int k: 占用4个字节,以原码形式存储,存储值为65536,采用边界对齐。char c1, c2: 每个char类型变量占用1个字节,以ASCII码形式存储,采用边界对齐。float x: 占用4个字节,采用IEEE 754标准存储,采用边界对齐。double y: 占用8个字节,采用IEEE 754标准存储,采用边界对齐。char *str: 存储字符串常量的地址,根据机器字长确定占用字节数,采用边界对齐。- 注意:具体的边界对齐数取决于编译器和目标平台的规定。
如果将变量存放在结构体中:
struct S { unsigned short i; int j; int k; char c1; char c2; float x; double y; char* str; };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
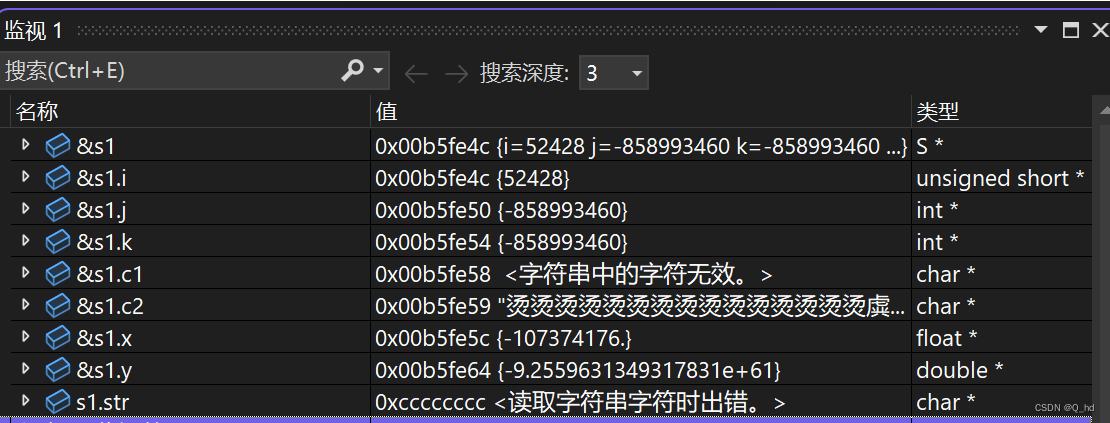
在这里插入代码片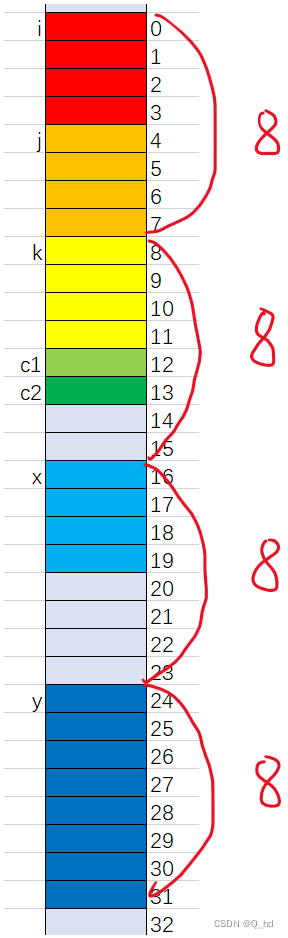
- 由地址分布可以看出:vs默认对齐数是8字节
显式对齐指令:某些编译器提供了特定的指令或编译选项,允许开发人员显式地指定结构体的对齐方式。例如,#pragma pack(n)可以设置结构体对齐数为 n 字节。
2. 分析程序的执行结果,给出其结果及说明。
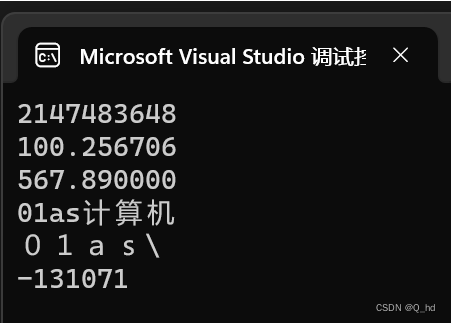
printf("%u\n", j); printf("%f\n", x); printf("%lf\n", y); printf("%s\n", str); printf("%d\n", i * i);- 1
- 2
- 3
- 4
- 5
-
printf("%u\n", j);
在C语言中,使用%u格式化符号输出一个有符号整数时,会将其作为无符号整数进行解释。由于-2147483648的二进制补码表示是10000000 00000000 00000000 00000000,这个二进制数被当做无符号整数解释时,对应的无符号整数值就是2147483648。因此,使用%u格式化符号输出-2147483648时会打印出2147483648。 -
printf("%f\n", x);
在一个32位小端机器上,float类型通常采用IEEE 754标准来表示。根据IEEE 754标准,float类型使用32位(4字节)来存储,其中包括1位符号位,8位指数位和23位尾数位。
对于浮点数100.25671,它首先会被转换成二进制表示。由于浮点数的精度有限,100.25671经过转换后可能会变成一个无限小数的近似值。这个近似值会以二进制形式存储在内存中。
当使用printf函数以%f格式打印这个浮点数时,该函数会根据IEEE 754标准将存储的二进制值解释为一个浮点数,并输出对应的十进制表示。由于二进制到十进制的转换是一个近似过程,因此输出的结果可能是一个近似值,例如100.256706,而不是精确的100.25671。 -
printf("%lf\n", y);
当你使用%lf打印一个double类型的变量时,C语言会按照双精度浮点数的格式进行输出。在双精度浮点数中,通常会有小数部分,并且会以固定的格式打印出小数点后的数字。
因此,当你使用%lf格式化符号打印double类型变量567.89时,输出为567.890000是正常的行为。这是因为printf函数默认会打印出小数点后6位的数字,即使它们是0。如果你希望打印更少的小数位数,可以使用%.nf来指定打印小数点后n位数字,其中n为你希望打印的小数位数。 -
printf("%s\n", str);
用%s打印字符串时\n表示换行,\\输出\ -
printf("%d\n", i * i);
变量i被定义为无符号短整型(unsigned short),并赋值为65535。然后使用%d格式化字符串来打印i与自身的乘积。
在一个 32 位小端机器上,短整型通常会被编码为 16 位。因此,unsigned short 变量可以表示从 0 到 65535 的无符号整数。当 i 被赋值为 65535 时,它达到了最大可能的值。
在 C 语言中,表达式i * i的类型会根据操作数的类型来确定。在这种情况下,i被隐式地转换为整型进行计算,结果也为整型。因此,i * i的结果将会是一个整型数。
当使用%d格式化字符串打印一个整型数时,printf函数会按照有符号整型进行解释。因此,如果结果超出了有符号整型数的表示范围,就会导致溢出。
在 32 位小端机器上,有符号整型通常会使用补码来表示。补码的表示范围为-2,147,483,648到2,147,483,647。因此,如果一个计算结果超出了这个范围,就会导致溢出,并且结果会被截断为补码表示范围内的值。
因此,当i的值为65535时,计算i * i的结果为4294836225,这个值超出了有符号整型的表示范围。因此,在使用%d格式化字符串打印这个值时,会产生一个溢出的结果-131071。
要修复这个问题,你可以将i和i * i的类型都声明为无符号的,以便保证计算结果不会溢出。例如:
unsigned short i = 65535; printf("%u\n", (unsigned int)i * i);- 1
- 2
在这个修正后的代码中,我将
i和i * i都声明为无符号类型,并使用%u格式化字符串来打印无符号整型数。3.你的机器字长多少位?编写程序说明int类型的位数、最小值和最大值各是多少?
#include#include int main() { printf("机器字长:%d位\n", sizeof(void*) * 8); printf("int类型的最小值:%d\n", INT_MIN); printf("int类型的最大值:%d\n", INT_MAX); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

4.编写程序分析说明,-1用int类型和unsigned int类型表示的结果分别是多少?
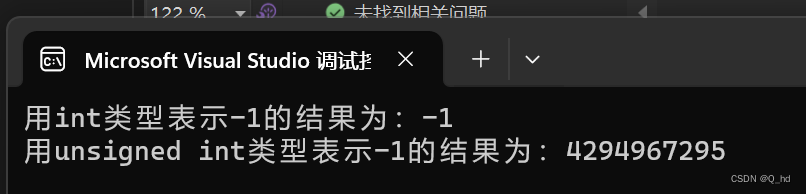
#includeint main() { int signedInt = -1; unsigned int unsignedInt = -1; printf("用int类型表示-1的结果为:%d\n", signedInt); printf("用unsigned int类型表示-1的结果为:%u\n", unsignedInt); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
当使用32位的二进制表示时,
-1在unsigned int类型中的表示为全部位均为1。下面是对-1的二进制表示的解释:-1的二进制表示(32位):11111111111111111111111111111111- 1
这里的每一位都是
1,因为在无符号整数中,所有的位都用于表示数值。在32位的二进制表示中,每个位置上的数字可以是0或1,因此-1被表示为全部位均为1的数值。
相比之下,在有符号的int类型中,二进制表示采用补码形式。-1的补码表示是通过将1的二进制表示取反再加1来得到的。在32位的二进制表示中,-1的补码表示如下:-1的补码表示(32位):11111111111111111111111111111111- 1
无论是在有符号的
int类型还是无符号的unsigned int类型中,-1的二进制表示都是全部位均为1。然而,它们的解释和含义不同,这取决于所使用的数据类型。 -
相关阅读:
数论——组合数学入门
三、Nginx核心配置文件
智能指针的理解
Android中的常用布局
初识node.js与内置模块
10.19QT作业
控制游戏人物移动的细节到底有多少?
使用 🧨 Diffusers 实现 ControlNet 高速推理
Autocad绘制的基于工控机的电加热炉的强电电路图
JSON端口操作实例
- 原文地址:https://blog.csdn.net/Colorful___/article/details/134456752
