-
【Linux】gcc/g++ && gdb 使用
目录

gcc 和 g++ 可以编译 c语言和c++语言,但是呢 g++ 编译 c语言时也是调用 gcc 的,所以一般编译 c语言时使用 gcc ,编译 c++ 时使用 g++;
1,背景知识
1,预处理(进行宏替换)
2,编译(生成汇编)
3,汇编(生成机器可识别代码)
4,连接(生成可执行文件或库文件)
2,gcc 如何完成
格式 gcc [选项] 要编译的文件 [选项] [目标文件]
1,预处理(进行宏替换)
预处理功能主要包括宏定义,文件包含,条件编译,去注释等。
预处理指令是以#号开头的代码行。
实例: gcc –E hello.c –o hello.i
选项“-E”,该选项的作用是让 gcc 在预处理结束后停止编译过程。
选项“-o”是指目标文件,“.i”文件为已经过预处理的C原始程序。


如果我们在 hello.c 里面写一点代码:

然后在把之前的 hello.i 删掉,重新编译一下:


之后就是很长的一段编译代码;
2,编译(生成汇编)
在这个阶段中,gcc 首先要检查代码的规范性、是否有语法错误等,以确定代码的实际要做的工作,在检查无误后,gcc 把代码翻译成汇编语言。
用户可以使用“-S”选项来进行查看,该选项只进行编译而不进行汇编,生成汇编代码。
实例: gcc –S hello.i –o hello.s


3,汇编(生成机器可识别代码)
汇编阶段是把编译阶段生成的“.s”文件转成目标文件
读者在此可使用选项“-c”就可看到汇编代码已转化为“.o”的二进制目标代码了
实例: gcc –c hello.s –o hello.o


里面全是二进制代码;
4,连接(生成可执行文件或库文件)
在成功编译之后,就进入了链接阶段。
实例: gcc hello.o –o hello
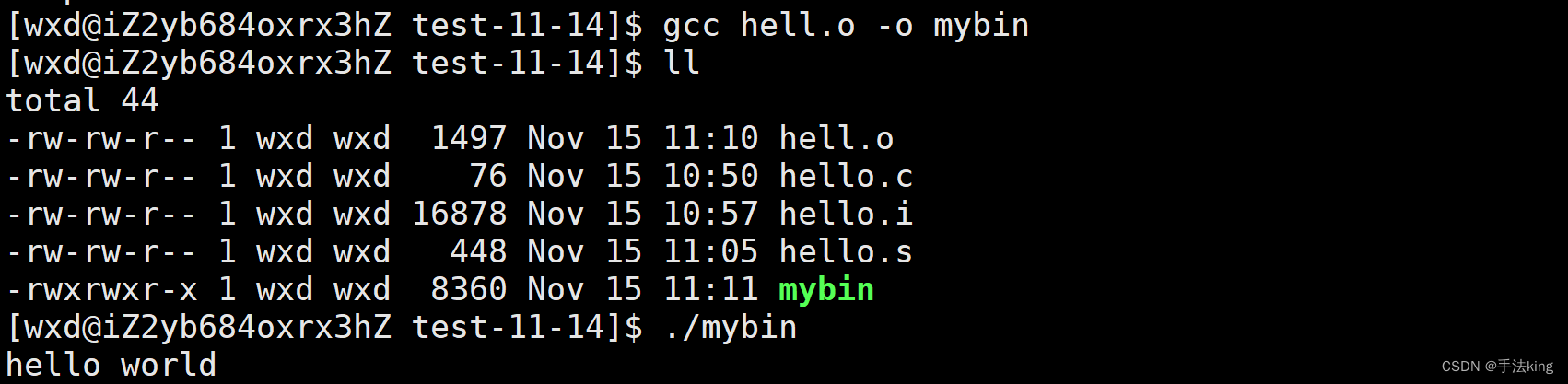
像这样4个过程结束,一个可执行程序就形成了;
5,函数库
我们的C程序中,并没有定义“printf”的函数实现,且在预编译中包含的“stdio.h”中也只有该函数的声明,而没有定义函数的实现,那么是在哪里实“printf”函数的呢?
最后的答案是:系统把这些函数实现都被做到名为 libc.so.6 的库文件中去了,在没有特别指定时,gcc 会到系统默认的搜索路径“/usr/lib”下进行查找,也就是链接到 libc.so.6 库函数中去,这样就能实现函 数“printf”了,而这也就是链接的作用
7,静态库和动态库
静态库是指编译链接时,把库文件的代码全部加入到可执行文件中,因此生成的文件比较大,但在运行时也就不再需要库文件了。其后缀名一般为“.a”
就不再需要库文件了。其后缀名一般为“.a” 动态库与之相反,在编译链接时并没有把库文件的代码加入到可执行文件中,而是在程序执行时由运行时 链接文件加载库,这样可以节省系统的开销。动态库一般后缀名为“.so”,如前面所述的 libc.so.6 就是动态 库。gcc 在编译时默认使用动态库。完成了链接之后,gcc 就可以生成可执行文件,如下所示。 gcc hello.o –o hello
gcc默认生成的二进制程序,是动态链接的,这点可以通过 file 命令验证。

形成静态可执行文件时末尾要加上 static ,看,两个文件的大小是不一样的,静态文件的大小比动态文件大的多;
8,gcc 选项
-E 只激活预处理,这个不生成文件,你需要把它重定向到一个输出文件里面
-S 编译到汇编语言不进行汇编和链接
-c 编译到目标代码
-o 文件输出到文件
-static 此选项对生成的文件采用静态链接
-g 生成调试信息。GNU 调试器可利用该信息。
-shared 此选项将尽量使用动态库,所以生成文件比较小,但是需要系统由动态库.
-O0
-O1
-O3 编译器的优化选项的4个级别,-O0表示没有优化,-O1为缺省值,-O3优化级别最高
-w 不生成任何警告信息。
Wall 生成所有警告信息。
9,gcc 选项记忆
编译选项的话就看我们键盘的左上角 eso ,然后对应的就是 iso ,最后形成可执行文件呢就不需要这种选项了;
3,Linux调试器-gdb使用
1,背景
程序的发布方式有两种,debug 模式和 release 模式
Linux gcc/g++ 出来的二进制程序,默认是 release 模式
要使用gdb调试,必须在源代码生成二进制程序的时候, 加上 -g 选项
2,命令选项
gdb binFile 退出: ctrl + d 或 quit 调试命令:
list/l 行号: 显示binFile源代码,接着上次的位置往下列,每次列10行。
list/l 函数名: 列出某个函数的源代码。
r或run: 运行程序。
break(b) 行号: 在某一行设置断点
n 或 next: 单条执行。
s或step: 进入函数调用
break 函数名: 在某个函数开头设置断点
info break(b) : 看断点信息。
finish: 执行到当前函数返回,然后挺下来等待命令
print(p): 打印表达式的值,通过表达式可以修改变量的值或者调用函数
set var: 修改变量的值
continue(或c): 从当前位置开始连续而非单步执行程序
delete breakpoints: 删除所有断点
delete breakpoints n: 删除序号为n的断点
disable breakpoints: 禁用断点
enable breakpoints: 启用断点
display 变量名: 跟踪查看一个变量,每次停下来都显示它的值
undisplay: 取消对先前设置的那些变量的跟踪
until X行号: 跳至X行
breaktrace(或bt): 查看各级函数调用及参数
info(i) locals: 查看当前栈帧局部变量的值
quit: 退出gdb
3,list/l 行号
显示binFile源代码,接着上次的位置往下列,每次列10行。




直接 l 加 行号即可;
4,list/l 函数名
列出某个函数的源代码。
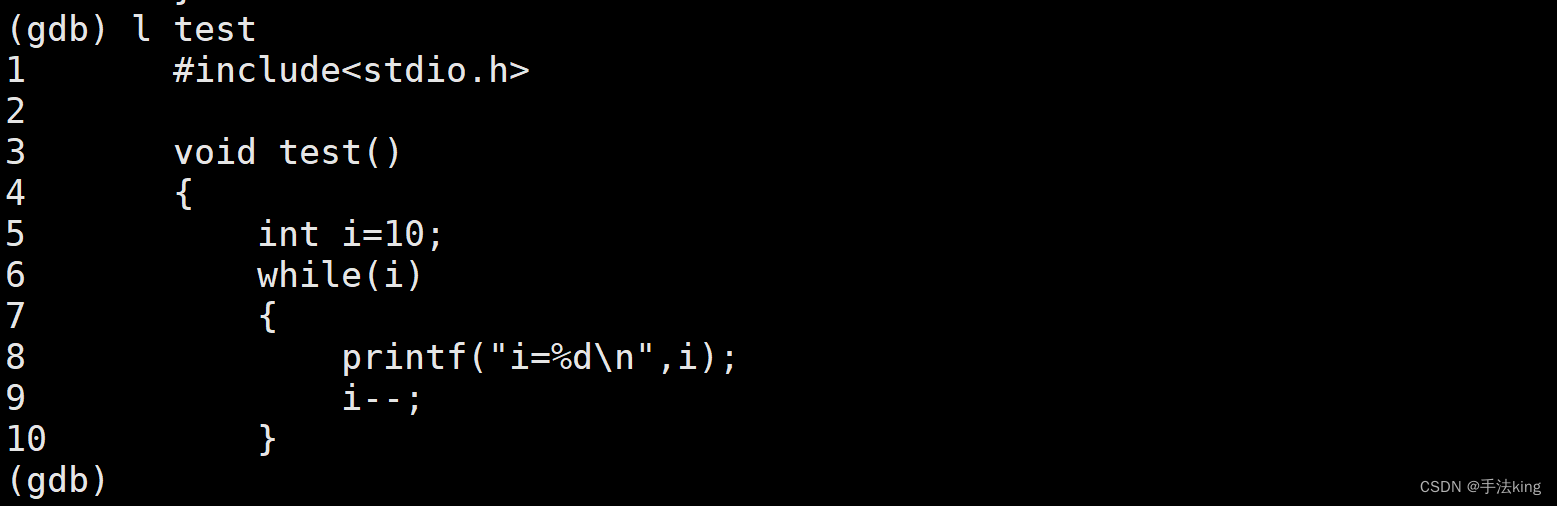
直接 l 加上 函数名即可;
5,r或run
运行程序。
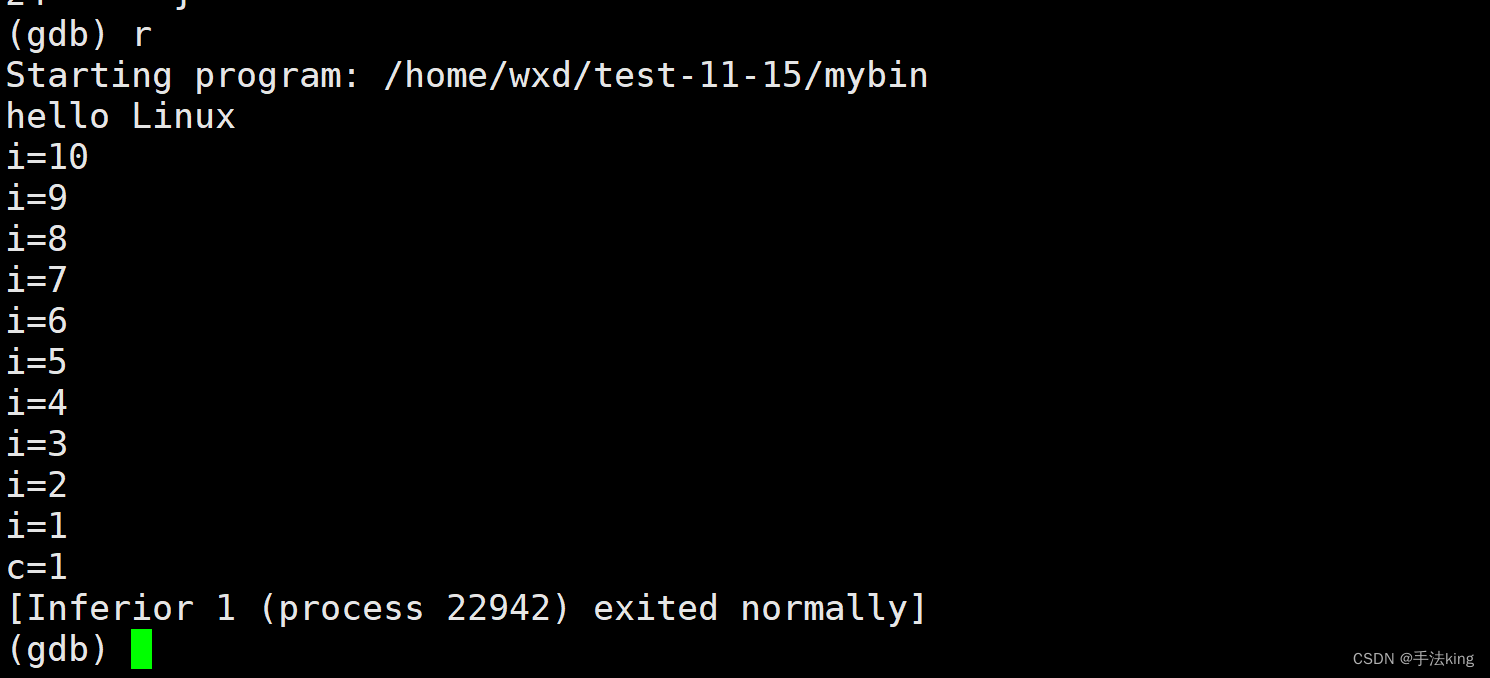
直接就是运行结果界面;
6,break(b) 行号
在某一行设置断点

在设置断点出运行停止;
7,n 或 next
单条执行,相当于 vs 中的 f10 逐过程,不会进入函数;

8,s或step
进入函数调用,相当于 vs 编译器里的 f11 逐语句,会进入函数;

直接会进入函数;
9,break 函数名
在某个函数开头设置断点,运行时直接进入函数

10,info break(b)
看断点信息。

最右边的是代码行号,最左边的是断点编号;
11,finish
执行到当前函数返回,然后挺下来等待命令

直接执行完此函数,最后还有返回值;
12,print(p)
打印表达式的值,通过表达式可以修改变量的值或者调用函数

可以打印变量的值,以及对他们进行修改;
13,set var
修改变量的值

修改变量的值
14,continue(或c)
一般和断点配合,运行两个断点之间的代码,以此来寻找错误

我们先设置断点;

每一次 c 都会进入下一个断点区域并且将其运行,寻找错误;
15,delete
删除所有断点

直接删除所有断点;
16,delete n
删除序号为n的断点

d 断点 ,删除断点;
17,disable 断点序号
禁用断点

End 下面的 y 代表 yes ,n 代表 no ,为 n 的就是被禁掉了;
18,enable 断点序号
启用断点
直接重新启动断点;
19,display 变量名
跟踪查看一个变量,每次停下来都显示它的值

就是运行每一个步骤都会显示变量的值;
20,undisplay 跟踪变量的序号
取消对先前设置的那些变量的跟踪

那个 6 就是跟踪变量的序号,取消变量要对应的是序号不是变量名;
21,until X行号
跳至X行

跳转行位置,当然啦,前提还是建立在运行的程序上;
22,breaktrace(或bt)
查看各级函数调用及参数

可以看到当前代码的所处函数的信息;
上面就是 main函数里面调用了 test 函数;
23,info(i) locals
查看当前栈帧局部变量的值

24,quit (q)
退出gdb
最后一个啦,单击一个 q ,退出 gdb;
25,理解 gdb
和windows IDE对应例子,也就是跟 vs 编译器对齐即可;

-
相关阅读:
Rancher(V2.6.3)安装K8s教程
Java通过反射模拟冰蝎免杀功能
Mybatis(1)—— 快速入门使用持久层框架Mybatis
了解 Xcode 工作区、项目、方案和目标如何协同工作
如何在 Keras 中开发具有注意力的编码器-解码器模型
各种业务场景调用API代理的API接口教程
【Java-----IO流(三)之缓冲流详解】
在ESG领域,区块链究竟怎么用?
el-form添加自定义校验规则校验el-input只能输入数字
NLP领域可以投稿的期刊或会议(不断更新中……)
- 原文地址:https://blog.csdn.net/m0_71676870/article/details/134408707