-
Transformers实战——Trainer和文本分类
文本分类
1.导入相关包
from transformers import AutoTokenizer, AutoModelForSequenceClassification- 1
2.加载数据
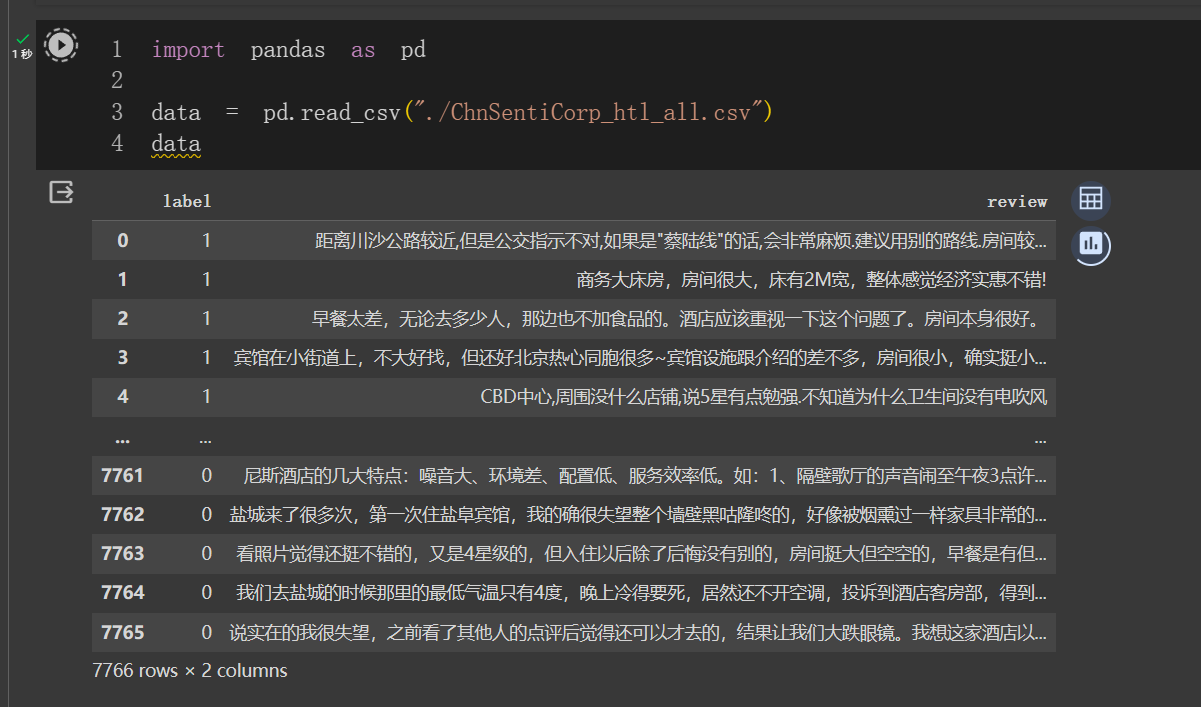
import pandas as pd data = pd.read_csv("./ChnSentiCorp_htl_all.csv") data- 1
- 2
- 3
- 4
- 删除空数据
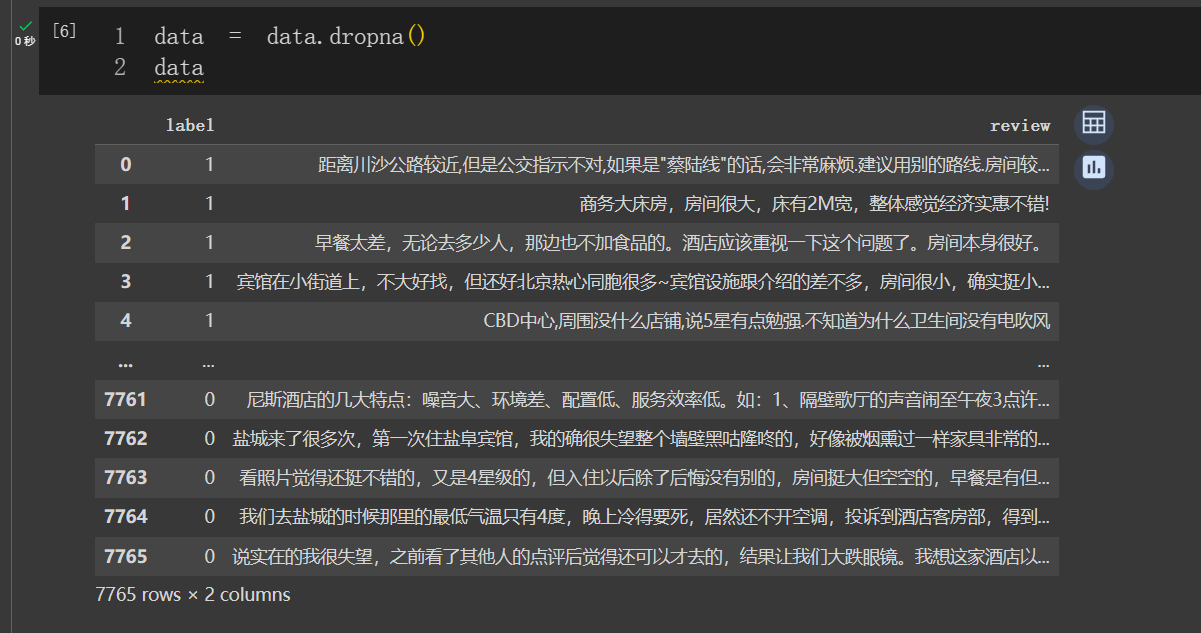
data = data.dropna() data- 1
- 2
3.创建 Dataset
from torch.utils.data import Dataset class MyDataset(Dataset): def __init__(self) -> None: super().__init__() self.data = pd.read_csv("./ChnSentiCorp_htl_all.csv") self.data = self.data.dropna() def __getitem__(self, index): return self.data.iloc[index]["review"], self.data.iloc[index]["label"] def __len__(self): return len(self.data)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
dataset = MyDataset() for i in range(5): print(dataset[i]) ''' ('距离川沙公路较近,但是公交指示不对,如果是"蔡陆线"的话,会非常麻烦.建议用别的路线.房间较为简单.', 1) ('商务大床房,房间很大,床有2M宽,整体感觉经济实惠不错!', 1) ('早餐太差,无论去多少人,那边也不加食品的。酒店应该重视一下这个问题了。房间本身很好。', 1) ('宾馆在小街道上,不大好找,但还好北京热心同胞很多~宾馆设施跟介绍的差不多,房间很小,确实挺小,但加上低价位因素,还是无超所值的;环境不错,就在小胡同内,安静整洁,暖气好足-_-||。。。呵还有一大优势就是从宾馆出发,步行不到十分钟就可以到梅兰芳故居等等,京味小胡同,北海距离好近呢。总之,不错。推荐给节约消费的自助游朋友~比较划算,附近特色小吃很多~', 1) ('CBD中心,周围没什么店铺,说5星有点勉强.不知道为什么卫生间没有电吹风', 1) '''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
4.划分数据集
from torch.utils.data import random_split trainset, validset = random_split(dataset, lengths=[0.9, 0.1]) len(trainset), len(validset) # (6989, 776)- 1
- 2
- 3
- 4
- 5
- 6
for i in range(10): print(trainset[i]) ''' ('房间还可以,设施简单,不像是四星标准。早餐还算丰富,不过要早去。前台接待、结算速度和态度还不错。后院停车场很有特点,一晚上有两台车被划伤,真恐怖,最关键的是保安及小头目还不想认帐,气愤啊', 0) ('我本来一直很喜欢的,可是这次有几个问题想说说:一是酒店门口的服务生太冷漠,形同虚设,我到酒店那天早上下雨,东西很多,打车去的时候他们居然站在那里一动不动,连伸手拉一下车门都没有。如果想要小费我想你做了别人肯定会给你。建议改进,至少可以帮客人拿一下东西吧。二是酒店前台通知不及时,我那天入住的时候说是住两晚上,可是前台服务员只要我压了500元的押金,后来没有通知我,第二天我回酒店就发现门打不开了,打电话问了才告诉我说是押金不够,显然服务一点都不人性化,希望能改进。另外,酒店的行李寄存服务很好,环境也很好,总的来说都很理想,就是希望能改进上面两个问题,做的更好,那样客人会更加喜欢你们宾馆。期待你们的改进和回复。宾馆反馈2008年6月17日:尊敬的携程会员:感谢您们对我们宾馆一直的关注和支持!针对您所反映的问题,我们管理层非常的重视。立即由相关部门结合实际展开调查和核实,同时借鉴您的合理化建议并采取一些有效的整改。从而对您的善意的提醒再次表示感谢!同时也十分感谢携程网提供了这样一个好的平台,希望诸位会员空闲之时多多给我们宾馆提出建议和评价。我们将以真诚的服务态度欢迎诸位的光临!', 1) ('服务有出错,让人大跌眼镜的那种,房卡会被搞错!', 0) ('地理位置是公认的不错,但是缺点也不少,主要是电梯慢,走廊狭窄,房间设施有些陈旧了,临时住一晚可以,时间长了不建议入住。', 0) ('在厦门岛内实地考察了很多家4星级标准酒店,认为这是性价比比较好的一家,位置还好,虽然设置不太新,但和其他几家挂牌4星且价格很贵的酒店相比也差不多。', 1) ('酒店幻境很好超安静适合休息附近的公园景色舒适惬意晚餐不错不过方便没有商店比较困难', 1) ('去的之前只打了一个晚上的酒店,后来由于种种原因就决定再住一晚。随之在携程上找了米兰,到了酒店之后,感觉很温馨。装修也很人性化,房间虽小,但格调很喜欢,唯一的不好就是太靠马路,晚上有点吵。但离西湖很近,我们是走过去的,因为是闹市所以不觉得远。总之很喜欢,下次还会来住的……', 1) ('环境吵,服务不好,入房时还给错房卡,进房时吓一跳,有人住,赶紧下楼问柜台说给错了。进房间烟位非常浓,说要来做无菸处理,来了竟然说无菸处理就是将菸灰缸拿掉就好,烟味几天就会散掉,真是气死了,跟他理论后他才说要拿清净剂来喷,喷了后烟味还是很重,实在不能接受。前面在修马路路上泥巴很多。早餐是送到房里,不好吃。服务态度不怎样。房里的洗衣机不见了,怎洗衣服呢。', 0) ('酒店的服务员服务很规范,早餐品种丰富。紧挨路边,周边环境有点吵,很早就有大卡车鸣笛。可能是住得太高的缘故(住顶楼6楼),晚上洗澡洗到一半没有热水了,过了约1分钟才慢慢来水.这在冬天是较难忍受的.', 1) ('太美了,但房间一般,携程房价好象有点贵,晚上没事做', 1) '''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
5.创建 Dataloader
import torch tokenizer = AutoTokenizer.from_pretrained("hfl/rbt3") def collate_func(batch): texts, labels = [], [] for item in batch: texts.append(item[0]) labels.append(item[1]) inputs = tokenizer(texts, max_length=128, padding="max_length", truncation=True, return_tensors="pt") inputs["labels"] = torch.tensor(labels) return inputs- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
from torch.utils.data import DataLoader trainloader = DataLoader(trainset, batch_size=32, shuffle=True, collate_fn=collate_func) validloader = DataLoader(validset, batch_size=64, shuffle=False, collate_fn=collate_func)- 1
- 2
- 3
- 4
next(enumerate(validloader))[1] ''' {'input_ids': tensor([[ 101, 4510, 3461, ..., 0, 0, 0], [ 101, 122, 119, ..., 117, 2769, 102], [ 101, 1762, 6821, ..., 1377, 809, 102], ..., [ 101, 6858, 6814, ..., 0, 0, 0], [ 101, 3315, 809, ..., 1384, 8024, 102], [ 101, 712, 6206, ..., 0, 0, 0]]), 'token_type_ids': tensor([[0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], ..., [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, ..., 0, 0, 0], [1, 1, 1, ..., 1, 1, 1], [1, 1, 1, ..., 1, 1, 1], ..., [1, 1, 1, ..., 0, 0, 0], [1, 1, 1, ..., 1, 1, 1], [1, 1, 1, ..., 0, 0, 0]]), 'labels': tensor([0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 0, 1])} ''' # 或者 next(iter(validloader)) ''' {'input_ids': tensor([[ 101, 4510, 3461, ..., 0, 0, 0], [ 101, 122, 119, ..., 117, 2769, 102], [ 101, 1762, 6821, ..., 1377, 809, 102], ..., [ 101, 6858, 6814, ..., 0, 0, 0], [ 101, 3315, 809, ..., 1384, 8024, 102], [ 101, 712, 6206, ..., 0, 0, 0]]), 'token_type_ids': tensor([[0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], ..., [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, ..., 0, 0, 0], [1, 1, 1, ..., 1, 1, 1], [1, 1, 1, ..., 1, 1, 1], ..., [1, 1, 1, ..., 0, 0, 0], [1, 1, 1, ..., 1, 1, 1], [1, 1, 1, ..., 0, 0, 0]]), 'labels': tensor([0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 1, 1, 0, 1])} '''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
6.创建模型及优化器
from torch.optim import Adam model = AutoModelForSequenceClassification.from_pretrained("hfl/rbt3") if torch.cuda.is_available(): model = model.cuda() optimizer = Adam(model.parameters(), lr=2e-5)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
7.训练与验证
def evaluate(): model.eval() acc_num = 0 with torch.inference_mode(): for batch in validloader: if torch.cuda.is_available(): batch = {k: v.cuda() for k, v in batch.items()} output = model(**batch) pred = torch.argmax(output.logits, dim=-1) acc_num += (pred.long() == batch["labels"].long()).float().sum() return acc_num / len(validset) def train(epoch=3, log_step=100): global_step = 0 for ep in range(epoch): model.train() for batch in trainloader: if torch.cuda.is_available(): batch = {k: v.cuda() for k, v in batch.items()} optimizer.zero_grad() output = model(**batch) output.loss.backward() optimizer.step() if global_step % log_step == 0: print(f"ep: {ep}, global_step: {global_step}, loss: {output.loss.item()}") global_step += 1 acc = evaluate() print(f"ep: {ep}, acc: {acc}")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
8.模型训练
train()- 1
9.模型预测
sen = "我觉得这家酒店不错,饭很好吃!" id2_label = {0: "差评!", 1: "好评!"} model.eval() with torch.inference_mode(): inputs = tokenizer(sen, return_tensors="pt") inputs = {k: v.cuda() for k, v in inputs.items()} logits = model(**inputs).logits pred = torch.argmax(logits, dim=-1) print(f"输入:{sen}\n模型预测结果:{id2_label.get(pred.item())}") ''' 输入:我觉得这家酒店不错,饭很好吃! 模型预测结果:好评! '''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
from transformers import pipeline model.config.id2label = id2_label pipe = pipeline("text-classification", model=model, tokenizer=tokenizer, device=0)- 1
- 2
- 3
- 4
pipe(sen) ''' [{'label': '好评!', 'score': 0.9974019527435303}] '''- 1
- 2
- 3
- 4
Trainer+文本分类
1.导入相关包
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments from datasets import load_dataset- 1
- 2
2.加载数据集
dataset = load_dataset("csv", data_files="./ChnSentiCorp_htl_all.csv", split="train") dataset = dataset.filter(lambda x: x["review"] is not None) # 过滤空数据 dataset ''' Dataset({ features: ['label', 'review'], num_rows: 7765 }) '''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3.划分数据集
datasets = dataset.train_test_split(test_size=0.1) datasets ''' DatasetDict({ train: Dataset({ features: ['label', 'review'], num_rows: 6988 }) test: Dataset({ features: ['label', 'review'], num_rows: 777 }) }) '''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
4.数据集预处理
import torch tokenizer = AutoTokenizer.from_pretrained("hfl/rbt3") def process_function(examples): tokenized_examples = tokenizer(examples["review"], max_length=128, truncation=True) tokenized_examples["labels"] = examples["label"] # 加入labels字段,模型自动算loss return tokenized_examples tokenized_datasets = datasets.map(process_function, batched=True, remove_columns=datasets["train"].column_names) # 删除不需要的列 tokenized_datasets ''' DatasetDict({ train: Dataset({ features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'], num_rows: 6988 }) test: Dataset({ features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'], num_rows: 777 }) }) '''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
5.创建模型
model = AutoModelForSequenceClassification.from_pretrained("hfl/rbt3")- 1
model.config ''' BertConfig { "_name_or_path": "hfl/rbt3", "architectures": [ "BertForMaskedLM" ], "attention_probs_dropout_prob": 0.1, "classifier_dropout": null, "directionality": "bidi", "hidden_act": "gelu", "hidden_dropout_prob": 0.1, "hidden_size": 768, "initializer_range": 0.02, "intermediate_size": 3072, "layer_norm_eps": 1e-12, "max_position_embeddings": 512, "model_type": "bert", "num_attention_heads": 12, "num_hidden_layers": 3, "output_past": true, "pad_token_id": 0, "pooler_fc_size": 768, "pooler_num_attention_heads": 12, "pooler_num_fc_layers": 3, "pooler_size_per_head": 128, "pooler_type": "first_token_transform", "position_embedding_type": "absolute", "transformers_version": "4.35.2", "type_vocab_size": 2, "use_cache": true, "vocab_size": 21128 } '''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
6.创建评估函数
import evaluate acc_metric = evaluate.load("accuracy") f1_metirc = evaluate.load("f1")- 1
- 2
- 3
- 4
def eval_metric(eval_predict): predictions, labels = eval_predict predictions = predictions.argmax(axis=-1) acc = acc_metric.compute(predictions=predictions, references=labels) f1 = f1_metirc.compute(predictions=predictions, references=labels) acc.update(f1) return acc- 1
- 2
- 3
- 4
- 5
- 6
- 7
7.创建 TrainingArguments
huggingface transformers使用指南之二——方便的trainer
详解Hugging Face Transformers的TrainingArguments_若石之上的博客-CSDN博客
LLM大模型之Trainer以及训练参数train_args = TrainingArguments(output_dir="./checkpoints", # 输出文件夹 per_device_train_batch_size=64, # 训练时的batch_size per_device_eval_batch_size=128, # 验证时的batch_size logging_steps=10, # log 打印的频率 evaluation_strategy="epoch", # 评估策略 save_strategy="epoch", # 保存策略,需要与评估策略保持一致 save_total_limit=3, # 最大保存数 learning_rate=2e-5, # 学习率 weight_decay=0.01, # weight_decay metric_for_best_model="f1", # 设定评估指标 load_best_model_at_end=True) # 训练完成后加载最优模型 # 如果使用evaluation_strategy="steps", # 则需要指定eval_steps参数,否则eval_steps=logging_steps train_args ''' TrainingArguments( _n_gpu=0, adafactor=False, adam_beta1=0.9, adam_beta2=0.999, adam_epsilon=1e-08, auto_find_batch_size=False, bf16=False, bf16_full_eval=False, data_seed=None, dataloader_drop_last=False, dataloader_num_workers=0, dataloader_pin_memory=True, ddp_backend=None, ddp_broadcast_buffers=None, ddp_bucket_cap_mb=None, ddp_find_unused_parameters=None, ddp_timeout=1800, debug=[], deepspeed=None, disable_tqdm=False, dispatch_batches=None, do_eval=True, do_predict=False, do_train=False, eval_accumulation_steps=None, eval_delay=0, eval_steps=None, evaluation_strategy=epoch, fp16=False, fp16_backend=auto, fp16_full_eval=False, fp16_opt_level=O1, fsdp=[], fsdp_config={'min_num_params': 0, 'xla': False, 'xla_fsdp_grad_ckpt': False}, fsdp_min_num_params=0, fsdp_transformer_layer_cls_to_wrap=None, full_determinism=False, gradient_accumulation_steps=1, gradient_checkpointing=False, gradient_checkpointing_kwargs=None, greater_is_better=True, group_by_length=False, half_precision_backend=auto, hub_always_push=False, hub_model_id=None, hub_private_repo=False, hub_strategy=every_save, hub_token=, ignore_data_skip=False, include_inputs_for_metrics=False, include_tokens_per_second=False, jit_mode_eval=False, label_names=None, label_smoothing_factor=0.0, learning_rate=2e-05, length_column_name=length, load_best_model_at_end=True, local_rank=0, log_level=passive, log_level_replica=warning, log_on_each_node=True, logging_dir=./checkpoints/runs/Nov16_05-36-15_da517cd92bfa, logging_first_step=False, logging_nan_inf_filter=True, logging_steps=10, logging_strategy=steps, lr_scheduler_type=linear, max_grad_norm=1.0, max_steps=-1, metric_for_best_model=f1, mp_parameters=, neftune_noise_alpha=None, no_cuda=False, num_train_epochs=3.0, optim=adamw_torch, optim_args=None, output_dir=./checkpoints, overwrite_output_dir=False, past_index=-1, per_device_eval_batch_size=128, per_device_train_batch_size=64, prediction_loss_only=False, push_to_hub=False, push_to_hub_model_id=None, push_to_hub_organization=None, push_to_hub_token= , ray_scope=last, remove_unused_columns=True, report_to=['tensorboard'], resume_from_checkpoint=None, run_name=./checkpoints, save_on_each_node=False, save_safetensors=True, save_steps=500, save_strategy=epoch, save_total_limit=3, seed=42, skip_memory_metrics=True, split_batches=False, tf32=None, torch_compile=False, torch_compile_backend=None, torch_compile_mode=None, torchdynamo=None, tpu_metrics_debug=False, tpu_num_cores=None, use_cpu=False, use_ipex=False, use_legacy_prediction_loop=False, use_mps_device=False, warmup_ratio=0.0, warmup_steps=0, weight_decay=0.01, ) ''' - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
8.创建 Trainer
- 如果只有训练集还想实现在训练的时候评估训练集的效果,则只需要将
eval_dataset=tokenized_datasets["train"]即可
from transformers import DataCollatorWithPadding trainer = Trainer(model=model, args=train_args, train_dataset=tokenized_datasets["train"], eval_dataset=tokenized_datasets["test"], data_collator=DataCollatorWithPadding(tokenizer=tokenizer), compute_metrics=eval_metric)- 1
- 2
- 3
- 4
- 5
- 6
- 7
9.模型训练
trainer.train()- 1
10.模型评估
trainer.evaluate() # 默认使用trainer中指定的eval_dataset # 也可以更换其他数据集 trainer.evaluate(tokenized_datasets["test"])- 1
- 2
- 3
- 4
11.模型预测
trainer.predict(tokenized_datasets["test"])- 1
sen = "我觉得这家酒店不错,饭很好吃!" id2_label = {0: "差评!", 1: "好评!"} model.eval() with torch.inference_mode(): inputs = tokenizer(sen, return_tensors="pt") inputs = {k: v.cuda() for k, v in inputs.items()} logits = model(**inputs).logits pred = torch.argmax(logits, dim=-1) print(f"输入:{sen}\n模型预测结果:{id2_label.get(pred.item())}")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
# 如果模型是基于GPU训练的,那么推理时要指定device from transformers import pipeline model.config.id2label = id2_label pipe = pipeline("text-classification", model=model, tokenizer=tokenizer, device=0)- 1
- 2
- 3
- 4
- 5
pipe(sen) ''' '''- 1
- 2
- 3
- 4
- 批量预测
- 加参数batch_size
- pipeline里面会自动将一个batch要拼成一样的长度
pipeline(model="openai/whisper-large-v2",device=0,batch_size=2)- 1
-
相关阅读:
计算机毕业设计django基于python教学互动系统(源码+系统+mysql数据库+Lw文档)
(六)Vue之MVVC
事件绑定方式总结
Lambda初次使用很慢?从JIT到类加载再到实现原理
测试人生 | 双非学历,从外包到某大厂只用了1年时间,在2线城市年薪近30万,我柠檬了......
leetcode-hot100-矩阵
Go 之为什么 rune 是 int32 的别名而不是 uint32 的别名
cpp编写的tcpserver,python编写的tcpclient,使用自定义的通讯协议
PingCAP Clinic 诊断服务简介
ios小程序蓝牙发送信息失败,报10004
- 原文地址:https://blog.csdn.net/qq_49821869/article/details/134443336
