-
【SOLO】实例分割论文SOLO: Segmenting Objects by Locations详解
🚩🚩实例分割论文专栏快速跳转🚩🚩【实例分割】

目录
✅代码:code
✅论文:paper
🌞🌞1.摘要
我们提出了一种新的、极其简单的实例分割方法。 与许多其他密集预测任务相比,例如语义分割,它的实例个数是任意的,使实例分割变得更具挑战性。 为了预测每个实例的掩码,主流方法要么遵循“检测然后分割”策略(例如,Mask R-CNN),或者首先预测嵌入向量,然后使用聚类技术将像素分组为单独实例。 我们从以下角度看待实例分割的任务通过引入“实例”的概念,提供了一个全新的视角类别,它将类别分配给实例中的每个像素根据实例的位置和大小,从而很好地将实例分割转换为单次分类可解决的问题。 我们展示一个更简单、更灵活的实例分割框架,具有强大的性能,达到与 Mask R-CNN 相当的精度,并且在精度方面优于最近的单次实例分割器。 我们希望这个简单而强大的框架可以作为除了实例分割之外,还能作为许多实例级识别任务的基线。
🌳🌳2.创新点
- 端到端训练,且无需后处理
- 只需要mask的标注信息,无需 bbox 标注信息
- 在 MASKCOCO 上实现了和 Mask R-CNN 基本持平的效果
- SOLO 只需要解决两个像素级的分类问题,类似于语义分割
- SOLO 通过离散量化,将坐标回归转化为分类问题,可以避免启发式的坐标规范化和 log 变换,通常用于像 YOLO 这样的检测器中,适用与实例级目标识别任务。
🌼🌼3.网络结构
🎃🎃3.1背景
作者先卖个关子,说明目前实例分割方法可以分为两类,即自上而下和自下而上。
- 第一种:即“检测然后分段”,首先检测边界框,然后对每个边界框中的实例掩码进行分段。
- 第二种:学习亲和关系,通过推动为每个像素分配一个嵌入向量,来实现远离属于不同实例的像素,并拉进同一实例中的临近像素。 然后需要进行分组后处理来分离实例。
这两种范例都是逐步和间接的,它们要么严重依赖于准确的边界框检测,要么依赖于每像素嵌入学习和分组处理。那么基于以上问题的思考,作者引出自己的解决思路。

首先重新思考一个问题:图像中的对象实例之间的根本区别是什么?
对MSCOCO数据集的验证数据集进行了分析,发现36780个对象中98.3%的实例对象之间的中心点距离都超过了30个像素。而在剩下的1.7%中,40.5%两个实例对象大小比例超过了1.5倍比例。基于此,我们完全可以推论:利用目标的Center locations和目标的Sizes是否就能较好表示不同的实例对象? 这也就是作者提出的实例类别的概念:实例的中心点位置和形状。
下一步就是如何基于实例类别实现实例分割?
实例分割和语义分割在算法处理上最大的不同就是,实例分割需要处理同类别的实例重叠或粘连的问题。那么如果将不同的实例分配到不同的输出channel上,不就可以解决这个问题了吗?本文作者正是这种思路,不过这样也面临两个问题: 一是通道分配顺序的问题,语义分割是根据类别进行通道分配的。而对于实例分割,相同类别的不同实例需要分配到不同通道上,需要解决按照什么样的规则分配。二是尺度问题,不同尺度的物体利用相同大小的输出来预测会导致正负样本不平衡,以及小目标分割边缘不够精细的问题。所以作者利用位置来分配实例应该落入哪一个通道,利用FPN来解决尺度问题。
🎃🎃3.2SOLO网络

SOLO网络的本质就是:将实例分割问题转化为两个问题:类别预测+实例掩膜生成
- 将输入图像分成S × S个小方格
- 每个通道表示对应的Positive的一个格子的分割结果。这里所谓的Positive指的是,只要这个格子在任何一个Groud Truth的中心区域里,就将这个格子认为是Positive的。
- 如果目标的中心落到格子里边,则这个格子要输出实例的语义类别(semantic category)+ 分割实例mask(segmenting instance mask)
- 每个格子的semantic category:输出C维的语义类别概率
- 最后将semantic category和instance mask 一对一关联
这里有一个重要假设:每个格子都只属于一个单独的实例。每个格子仅仅属于(可以分配)一个语义类别。
缺点:不好解决两个物体有重叠的情况或者一个格子里多个实例。
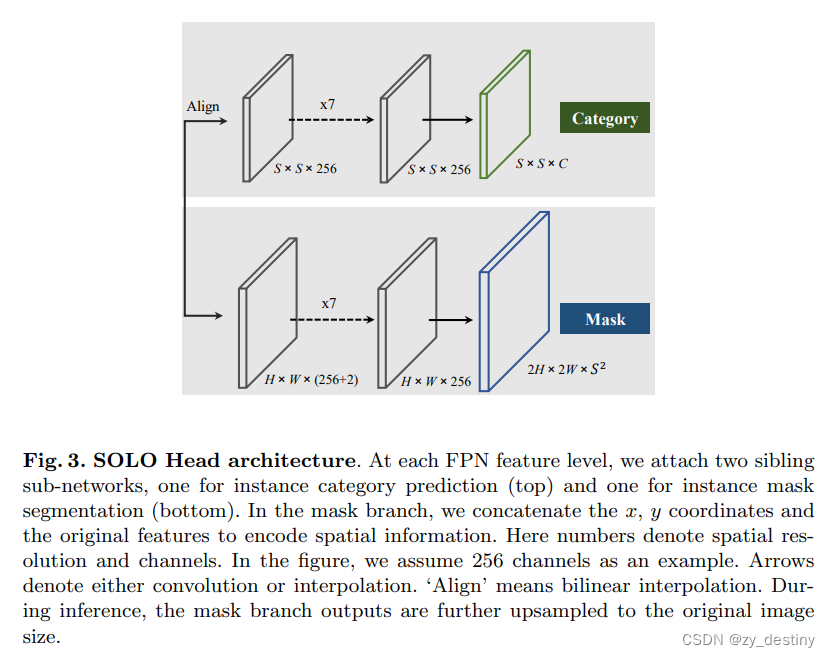
图像经过全卷积网络(FCN)后进入两个分支的预测。一个类别分支,预测每个网格所处的物体类别,每个网格对应一个C维类别向量(C为类别数),总的类别矩阵大小为S x S x C;一个mask分支预测每个网格所属的物体mask,总的mask矩阵大小为H x W x (S x S)。
mask是不关乎类别的,无论是什么物体,只要该物体落入了这个网格,mask 分支都预测它的mask。如图所示:在中间两个长颈鹿存在的网格中,分割的mask是两者都有的。

🎃🎃3.3解耦SOLO
给定一个预定义的网格数,例如 S = 20,我们的 SOLO 头输出S*S = 400 个频道映射。 然而,预测有些冗余,因为在大多数情况下,对象在图像中稀疏地分布。因此采用更高效的SOLO变体,称为解耦 SOLO,如下图所示。

🍁🍁4.结果
🌾🌾4.1精度指标

🌾🌾4.2消融实验
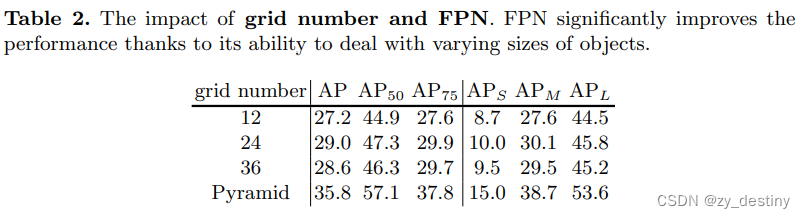
❤️FPN的网格数量影响
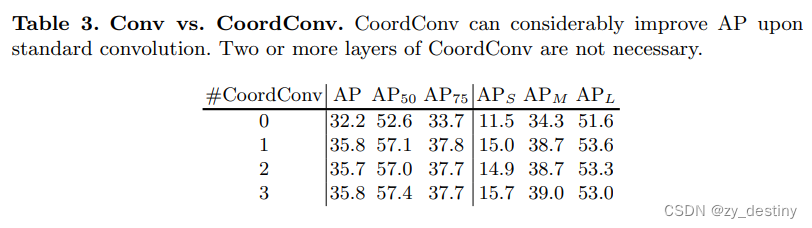
❤️卷积对比
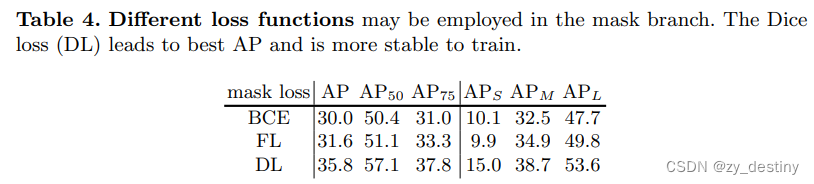
❤️loss函数对比
❤️head深度对比

❤️input-size对比
 ❤️error 分析对比
❤️error 分析对比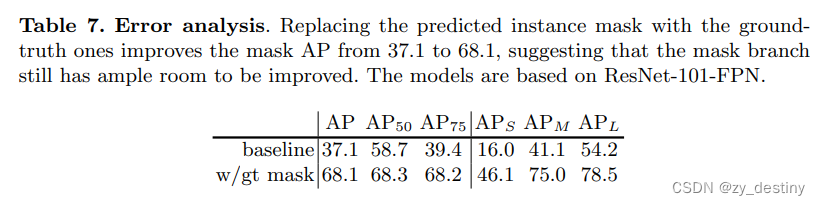
🌾🌾4.3结果

💐💐5.启发
开发了一个端到端的实例分割框架,称为 SOLO。可以以恒定的推理时间将原始输入图像直接映射到所需的实例掩模,从而消除了自下而上方法中的分组后处理或边界框检测和 RoI 操作的需要。鉴于其简单性,灵活性,以及强大的性能,希望SOLO能够服务于其他实例级识别任务的baseline。
整理不易,欢迎一键三连!!!
送你们一条美丽的--分割线--
🌷🌷🍀🍀🌾🌾🍓🍓🍂🍂🙋🙋🐸🐸🙋🙋💖💖🍌🍌🔔🔔🍉🍉🍭🍭🍋🍋🍇🍇🏆🏆📸📸⛵⛵⭐⭐🍎🍎👍👍🌷🌷
-
相关阅读:
小程序容器助力车企抢滩智慧车载新生态
Redis 好友关注-朋友圈
cas:174501-65-6|1-丁基-3-甲基咪唑四氟硼酸盐[C4MIm]BF4离子液体|颜色:Clearyellow-orange
RabbitMQ:发布确认高级
152. 乘积最大子数组
CVE-2022-40684 Fortinet(飞塔)身份验证绕过漏洞
Python排序:冒泡,选择,插入,希尔,归并,快速
黑马笔记---常见数据结构
基于第二代 ChatGLM2-6B P-Tuning v2 微调训练医疗问答任务
脚手架原理之webpack处理html文件和模块打包
- 原文地址:https://blog.csdn.net/qq_38308388/article/details/134434365