-
从零开始 通义千问大模型本地化到阿里云通义千问API调用
从零开始 通义千问大模型本地化到阿里云通义千问API调用
一、通义千问大模型介绍
何为“通义千问”?
“通义千问大模型”是阿里云推出的一个超大规模的语言模型,具有强大的归纳和理解能力,可以处理各种自然语言处理任务,包括但不限于文本分类、文本生成、情感分析等。此模型能够极大地提高了自然语言处理的效率和准确性,给用户提供了一种新的、简便的工具。
通义千问全面开放
2023年9月13号,阿里云宣布通义千问大模型已首批通过备案,并正式向公众开放,个人/企业用户可以通过阿里云调用通义千问API。
通义千问模型细解:https://modelscope.cn/models/qwen/Qwen-7B-Chat/summary
7B试用地址:https://modelscope.cn/studios/qwen/Qwen-7B-Chat-Demo/summary?login=from_csdn通义千问能力


正常对话基本秒级输出,初步达到商业化的标准
用途:- 创作文字,如写故事、写公文、写邮件、写剧本、写诗歌等
- 编写代码
- 提供各类语言的翻译服务,如英语、日语、法语、西班牙语等
- 进行文本润色和文本摘要等工作
- 扮演角色进行对话
- 制作图表
- …
二、本地化部署
通义千问的本地化部署和API还是非常简明的,虽然不是一键,但也差不多了。
1、配置
python >=3.8及以上版本
pytorch 1.12及以上版本,推荐2.0及以上版本
建议使用CUDA 11.4及以上(GPU用户、flash-attention用户等需考虑此选项)pip install modelscope
2、示例代码
from modelscope import AutoModelForCausalLM, AutoTokenizer, snapshot_download from modelscope import GenerationConfig # Note: The default behavior now has injection attack prevention off. model_dir = snapshot_download("qwen/Qwen-7B-Chat", revision = 'v1.1.4') tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True) # use fp16 # model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True, fp16=True).eval() model = AutoModelForCausalLM.from_pretrained(model_dir, device_map="auto", trust_remote_code=True).eval() # Specify hyperparameters for generation model.generation_config = GenerationConfig.from_pretrained(model_dir, trust_remote_code=True) # 可指定不同的生成长度、top_p等相关超参 # 第一轮对话 1st dialogue turn response, history = model.chat(tokenizer, "你好", history=None) print(response) # 你好!很高兴为你提供帮助。 # 第二轮对话 2nd dialogue turn response, history = model.chat(tokenizer, "给我讲一个年轻人奋斗创业最终取得成功的故事。", history=history) print(response)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
3、运行结果
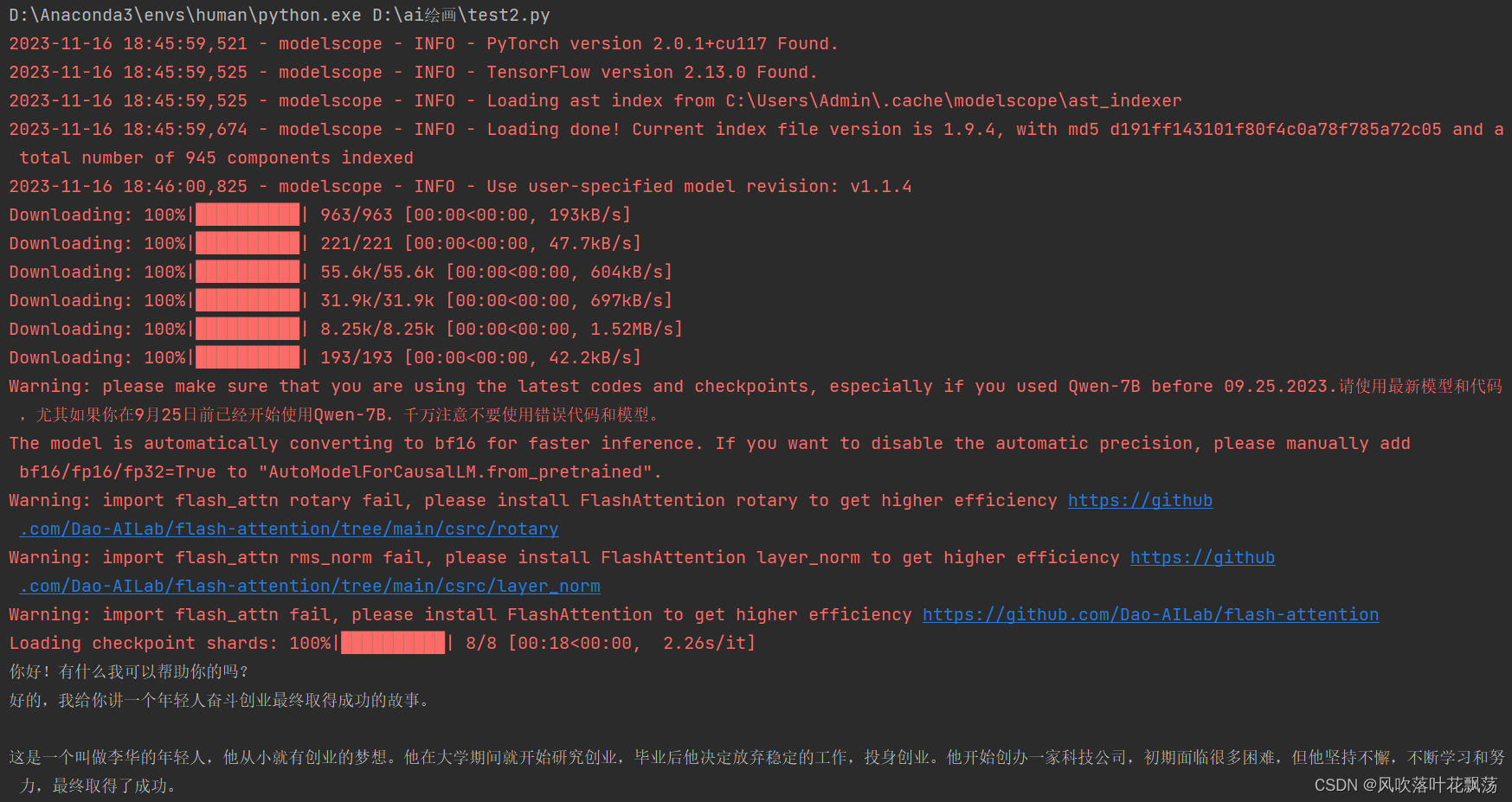
注:第一次运行需要从魔塔社区qwen/Qwen-7B-Chat下载模型,记得关掉翻墙
注:运行后模型会自动安装至:C:\Users\Admin.cache\modelscope\ast_indexer
到这里就本地化部署完了,后续可以使用量化到16f的14B模型,这个各项性能是最好的。有微调需求请参考:https://modelscope.cn/models/qwen/Qwen-7B-Chat/summary三、调用通义千问API
1、快速开始
官方教程:https://help.aliyun.com/zh/dashscope/developer-reference/quick-start?spm=a2c4g.11186623.0.i0
教程主要分三部分:
(1)获得通义千问的API-KEY:开通DashScope并创建API-KEY。
(2)安装DashScope 库:pip install dashscope
(3)python调用通义千问API:# For prerequisites running the following sample, visit https://help.aliyun.com/document_detail/611472.html from http import HTTPStatus import dashscope dashscope.api_key='YourAPIKey' #填入第一步获取的APIKEY def call_with_messages(): messages = [{'role': 'system', 'content': 'You are a helpful assistant.'}, {'role': 'user', 'content': '如何做炒西红柿鸡蛋?'}] response = dashscope.Generation.call( dashscope.Generation.Models.qwen_turbo, messages=messages, result_format='message', # set the result to be "message" format. ) if response.status_code == HTTPStatus.OK: print(response) else: print('Request id: %s, Status code: %s, error code: %s, error message: %s' % ( response.request_id, response.status_code, response.code, response.message )) if __name__ == '__main__': call_with_messages()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
运行结果:

更多请参考 通义千问API详情2、API计量计费
模型服务 计费单元 通义千问 Token 注:
Token是模型用来表示自然语言文本的基本单位,可以直观的理解为“字”或“词”。对于中文文本来说,1个token通常对应一个汉字;对于英文文本来说,1个token通常对应3至4个字母。通义千问模型服务根据模型输入和输出的总token数量进行计量计费,其中多轮对话中的history作为输入也会进行计量计费。每一次模型调用产生的实际token数量可以从
response 中获取。模型名 计费单价 qwen-turbo 0.008元/1,000 tokens qwen-plus 0.02元/1,000 tokens qwen-max 限时免费开放中 
通义千问整体从API价格上说相比OpenAI优势不大、限流上也不占据优势,唯一的好处就是,国内初学者使用的时候方便又快捷
在魔塔社区中也可设置环境变量DASHSCOPE_API_KEY =apikey,不需要再代码中设置,隐藏apikey,让开发者在创空间中也能快捷调用大模型了。这酱紫demo制作空间就广阔了一点点。
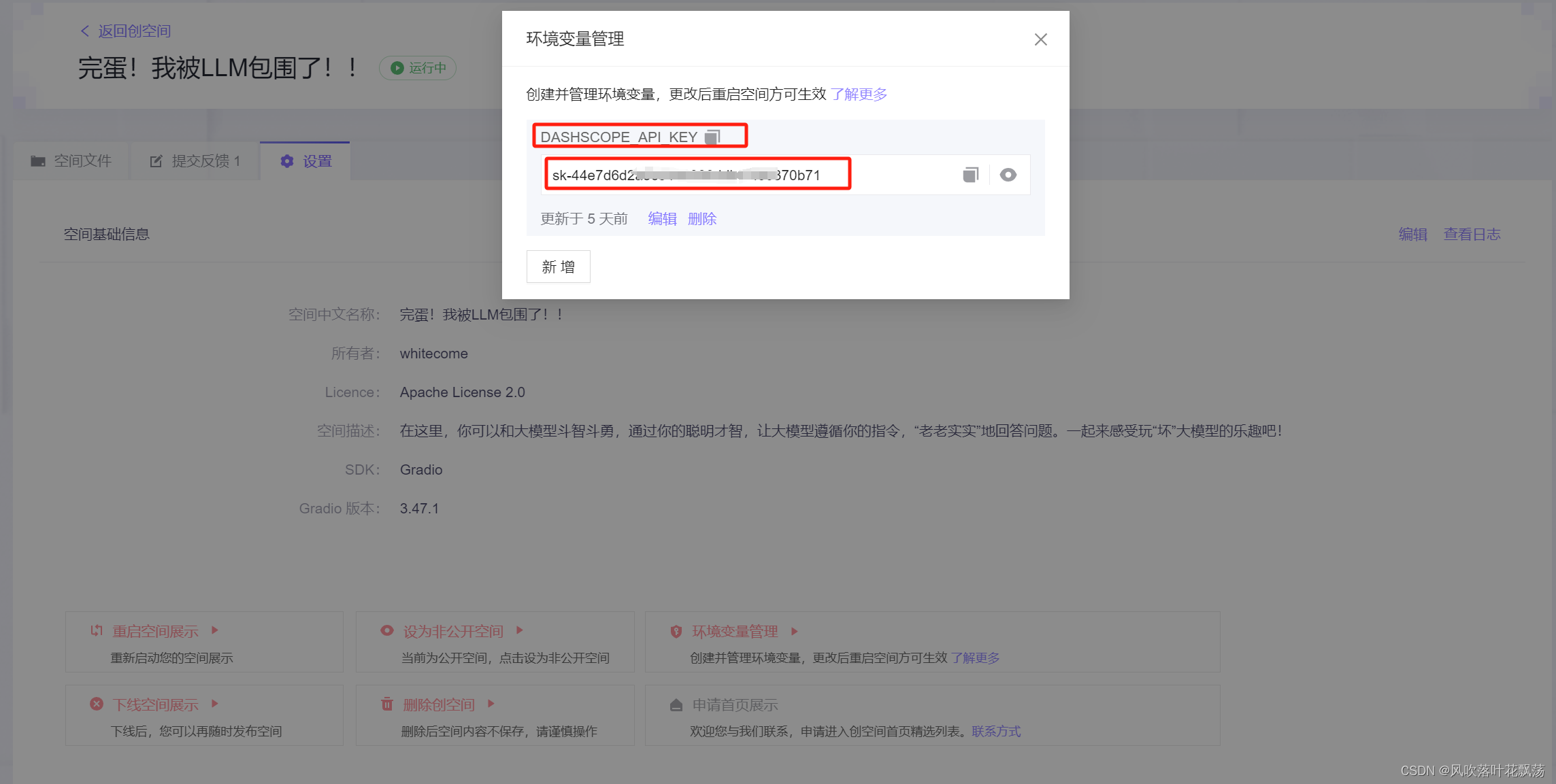
希望国内的硬件能早日起来
-
相关阅读:
NPM- 滚动进度可视化插件
记录react native 环境配置 brew install watchman 警告问题
【prometheus】监控MySQL并实现可视化
OpenFeign自定义异常
Java的stream流进行分页取数据
《Java并发编程之美》学习笔记
用ChatGPT自动生成流程图
【技术】技术研发人员面试IT公司顺利通过的小技巧
es6 Set和Map方法
Leetcode 670. 最大交换
- 原文地址:https://blog.csdn.net/qq_51116518/article/details/134448138
