-
【视觉SLAM十四讲学习笔记】第二讲——初识SLAM
专栏系列文章如下:
【视觉SLAM十四讲学习笔记】第一讲一个机器人,如果想要探索某一块区域,它至少需要知道两件事:
- 我在什么地方——定位
- 周围环境是什么样——建图
一方面需要明白自身的状态(即位置),另一方面也要了解外在的环境(即地图)。这个时候就需要借助传感器了。
传感器分类
一类传感器是安装于环境中的,例如导轨、二维码标志等等。它们通常能够直接测量到机器人的位置信息,简单有效地解决定位问题。然而,由于它们必须在环境中设置,在一定程度上限制了机器人的使用范围。也就是说,这类传感器约束了外部环境。只有在这些约束满足时,基于它们的定位方案才能工作。虽然这类传感器简单可靠,但它们无法提供一个普遍的,通用的解决方案。
一类传感器是携带于机器人本体上的,比如激光传感器、相机、轮式编码器、惯性测量单元(Inertial Measurement Unit, IMU)等,它们测到的通常都是一些间接的物理量而不是直接的位置数据。例如,轮式编码器会测到轮子转动的角度、IMU测量运动的角速度和加速度,相机和激光则读取外部环境的某种观测数据。我们只能通过一些间接的手段,从这些数据推算自己的位置。明显的好处是,它没有对环境提出任何要求,使得这种定位方案可适用于未知环境。这和SLAM中所强调的不谋而合,因此使用携带式的传感器,比如相机,来完成SLAM是我们重点关心的问题。
按照相机的工作方式,我们把相机分为单目(Monocular)、双目(Stereo) 和 深度相机(RGB-D) 三个大类。直观看来,单目相机只有一个摄像头,双目有两个,而 RGB-D原理较复杂,除了能够采集到彩色图片之外,还能读出每个像素离相机的距离。此外,SLAM 中还有全景相机、Event 相机等。
单目相机
只使用一个摄像头进行SLAM的做法称为单目SLAM(Monocular SLAM)。

作为单目相机的数据,照片本质上是拍摄某个场景(Scene)在相机的成像平面上留下的一个投影。它以二维的形式记录了三维的世界。显然,这个过程丢掉了场景的一个维度,也就是所谓的深度(或距离)。在单目相机中,我们无法通过单个图片来计算场景中物体离我们的距离(远近)。同时由于单目相机只是三维空间的二维投影,所以如果我们想恢复三维结构,必须改变相机的视角。在单目SLAM中也是同样的原理。我们必须移动相机之后,才能估计它的运动(Motion),同时估计场景中物体的结构(Structure),即远近和大小。
那么,怎么估计这些运动和结构呢?一方面,如果相机往右移动,那么图像里的东西就会往左边移动——这就给我们推测运动带来了信息。另一方面,我们还知道近处的物体移动快,远处的物体则运动缓慢,极远处(无穷远处)的物体看上去是不动的。于是,当相机移动时,这些物体在图像上的运动形成了视差。通过视差,我们就能定量地判断哪些物体离得远,哪些物体离的近。
然而,即使我们知道了物体远近,它们仍然只是一个相对的值。如果把相机的运动和场景大小同时放大两倍,单目所看到的像是一样的。同样的,把这个大小乘以任意倍数,我们都将看到一样的景象。这说明了单目SLAM 估计的轨迹和地图,将与真实的轨迹、地图,相差一个因子,也就是所谓的尺度(Scale)。由于单目 SLAM 无法仅凭图像确定这个真实尺度,所以又称为尺度不确定性。
平移之后才能计算深度,以及无法确定真实尺度,这两件事情给单目SLAM 的应用造成了很大的麻烦。后面为了得到这个深度,开始使用双目和深度相机。使用这两种相机的目的是通过某种手段测量物体与相机之间的距离。一旦知道了距离,场景的三维结构就可以通过单个图像恢复,同时消除尺度不确定性。
双目相机

双目相机由两个单目相机组成,两个相机之间的距离(称为基线(Baseline))是已知的。我们通过这个基线来估计每个像素的空间位置。人类可以通过左右眼图像的差异判断物体的远近,在计算机上也是同样的道理。

计算机上的双目相机需要大量的计算才能估计每一个像素点的深度,相比于人类是非常的笨拙。双目相机测量到的深度范围与基线相关。基线距离越大,能够测量到的就越远。双目相机的距离估计是比较左右眼的图像获得的,并不依赖其他传感设备,所以它既可以应用在室内,也可应用于室外。双目或多目相机的缺点是配置与标定较为复杂,其深度量程和精度受双目的基线与分辨率限制,而且视差的计算非常消耗计算资源,需要使用 GPU 和 FPGA 设备加速后,才能实时输出整张图像的距离信息。深度相机

深度相机又称RGB-D相机,可以通过红外结构光或 Time-of-Flight(ToF)原理,像激光传感器那样,通过主动向物体发射光并接收返回的光,测出物体离相机的距离。 不像双目那样通过软件计算来解决,而是通过物理的测量手段,可节省大量的计算量。不过,现在多数 RGB-D 相机还存在测量范围窄、噪声大、视野小、易受日光干扰、无法测量透射材质等诸多问题,在SLAM方面,主要用于室内。综上,视觉SLAM的目标是通过一系列连续变化的图像,进行定位和地图构建。
经典视觉SLAM框架
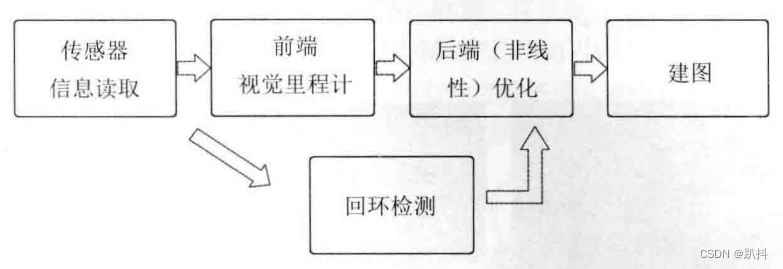
整个视觉SLAM流程包括以下步骤:- 传感器信息读取。在视觉 SLAM 中主要为相机图像信息的读取和预处理。如果在机器人中,还可能有测速码盘、惯性传感器等信息的读取和同步。
- 前端视觉里程计(Visual Odometry, VO)。视觉里程计的任务是估算相邻图像间相机的运动,以及局部地图的样子。VO 又称为前端(Front End)。
- 后端(非线性)优化(Optimization)。后端接受不同时刻视觉里程计测量的相机位姿,以及回环检测的信息,对它们进行优化,得到全局一致的轨迹和地图。由于接在VO之后, 又称为后端(Back End)。
- 回环检测(Loop Closure Detection)。回环检测判断机器人是否到达过先前的位置。如果检测到回环,它会把信息提供给后端进行处理。
- 建图(Mapping)。它根据估计的轨迹,建立于任务要求对应的地图。
视觉里程计
视觉里程计关心相邻图像之间的相机运动,最简单的情况是两张图像之间的运动关系。图像在计算机里只是一个数值矩阵。这个矩阵里表达着什么东西,计算机毫无概念(这也正是现在机器学习要解决的问题)。而在视觉 SLAM 中,我们只能看到一个个像素,知道它们是某些空间点在相机的成像平面上投影的结果。所以,为了定量地估计相机运动,必须在了解相机与空间点的几何关系。
而视觉里程计能够通过相邻帧之间的图像估计相机运动,并恢复场景的空间结构。它和实际的里程计一样,只计算相邻时刻的运动,而和过去的信息没有关联。现在假定我们已经有了一个视觉里程计,估计了两张图像间的相机运动。那么一方面,只需要把相邻时刻的运动串起来,就构成了机器人的运动轨迹,从而解决了定位问题。另一方面,我们根据每个时刻的相机位置,计算出各像素对应的空间点的位置,就得到了地图。但是这并没有解决SLAM的问题。
仅通过视觉里程计来估计轨迹,将不可避免地出现累计漂移(Accumulating Drift)。这是由于视觉里程计在最简单的情况下只估计两个图像间的运动造成的。每次估计都有一定的误差,而由于里程计的工作方式,先前时刻的误差将会传递到下一时刻,经过一段时间的累计,估计的轨迹就不再准确。

这就是所谓的漂移(Drift)。为了解决漂移问题,我们需要后端优化和回环检测。回环检测负责把“机器人回到原始位置”这件事检测出来,而后端优化则根据该信息,校正整个轨迹的形状。
后端优化
后端优化主要指处理SLAM过程中的噪声问题。即如何从这些带有噪声的数据中估计整个系统的状态(既包括机器人自身的轨迹,也包含地图),以及这个状态估计的不确定性有多大——这称为最大后验概率估计。
在SLAM框架中,前端给后端提供待优化的数据,以及这些数据的初始值。而后端负责整体的优化过程,它往往面对的只有数据,不必关心这些数据到底来自什么传感器。在视觉 SLAM 中,前端和计算机视觉研究领域更为相关,比如图像的特征提取与匹配等,后端则主要是滤波与非线性优化算法。
SLAM 问题的本质:对运动主体自身和周围环境空间不确定性的估计。为了解决SLAM,我们需要状态估计理论,把定位和建图的不确定性表达出来,然后采用滤波器或非线性优化,去估计状态的均值和不确定性(方差)。
回环检测
回环检测又称闭环检测(Loop Closure Detection),主要解决位置估计随时间漂移的问题。假设实际情况下,机器人经过一段时间运动后回到了原点,但是由于漂移,它的位置估计值却没有回到原点。如果有某种手段,让机器人知道回到了原点这件事,或者把原点识别出来,我们再把位置估计值拉过去,就可以消除漂移了。这就是所谓的回环检测。
为了实现回环检测,我们需要让机器人具有识别到过的场景的能力。同时我们更希望机器人能使用携带的传感器——也就是图像本身来完成这一任务。例如通过判断图像间的相似性来完成回环检测。如果回环检测成功,则可以显著地减小累计误差。所以,视觉回环检测实质上是一种计算图像数据相似性的算法。
在检测到回环之后,我们会把“A 与 B 是同一个点”这样的信息告诉后端优化算法。然后,后端根据这些新的信息,把轨迹和地图调整到符合回环检测结果的样子。这样,如果我们有充分而且正确的回环检测,就可以消除累积误差,得到全局一致的轨迹和地图。
建图
指构建地图的过程。地图是对环境的描述,但这个描述并不是固定的,需要视SLAM的应用而定。

对于地图,我们有太多的想法和需求。因此。相比于前面提到的视觉里程计、后端优化和回环检测,建图并没有一个固定的形式和算法。大体上讲,可以分为度量地图和拓补地图两种。度量地图(Metric Map)
度量地图强调精确地表示地图中物体的位置关系,通常我们用稀疏(Sparse)与稠密(Dense)对它们进行分类。
稀疏地图进行了一定程度的抽象,并不需要表达所有的物体。例如,我们选择一部分具有代表意义的东西,称之为路标(Landmark),那么一张稀疏地图就是由路标组成的地图,而不是路标的部分就可以忽略掉。
稠密地图着重于建模所有看到的东西。对于定位来说,稀疏路标地图就足够了。而用于导航时,我们往往需要稠密的地图。稠密地图通常按照某种分辨率,由许多个小块组成。二维度量地图是许多个小格子(Grid),三维则是许多小方块(Voxel)。一般地,一个小块含有占据、空闲、未知三种状态,以表达该格内是否有物体。当我们查询某个空间位置时,地图能够给出该位置是否可以通过的信息。这样的地图可以用于各种导航算法。
但是一方面,这种地图需要存储每一个格点的状态,耗费大量的存储空间,而且多数情况下地图的许多细节部分是无用的。另一方面,大规模度量地图有时会出现一致性问题。很小的一点转向误差,可能会导致两间屋子的墙出现重叠,使地图失效。
拓扑地图(Topological Map)
相比于度量地图的精确性,拓扑地图则更强调地图元素之间的关系。拓扑地图是一个图(Graph),由节点和边组成,只考虑节点间的连通性,例如只关注 A,B 点是连通的,而不考虑如何从A点到达B点的过程。它放松了地图对精确位置的需要,去掉地图的细节,是一种更为紧凑的表达方式。
但是拓扑地图不擅长表达具有复杂结构的地图。如何对地图进行分割形成结点与边,又如何使用拓扑地图进行导航与路径规划,仍是有待研究的问题。
SLAM的数学描述
现在假设有个机器人正携带某种传感器在未知环境里运动。由于相机通常是在某些时刻采集数据的,所以我们也只关心这些时刻的位置和地图。这就把一段连续时间的运动变成了离散时刻t=1,…,K当中发生的事情,用x表示位置,于是各时刻的位置就记为x1,…,xK,它们构成了机器人运动的轨迹。地图方面,假设地图是由许多个路标组成的,而每个时刻,传感器会测量到一部分路标点,得到它们的观测数据。设路标点一共有N个,用y1,…,yN来表示。
在如上设定中,机器人携带着传感器在环境中运动这件事,由如下两件事情描述:
-
什么是运动?要考察从k−1时刻到k时刻,机器人的位置x是如何变化的。
通常,机器人会携带一个测量自身运动的传感器,比如说码盘或惯性传感器。这个传感器可以测量有关运动的读数,但不一定直接是位置之差,还可能是加速度、角速度等信息。无论是什么传感器,我们都能使用一个通用的、抽象的数学模型:
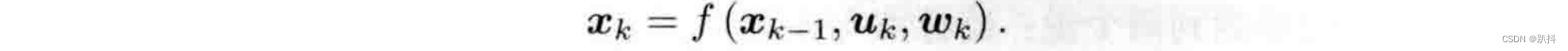 这里uk是运动传感器的输入,wk 为该过程中加入的噪声。这称为运动方程。噪声的存在使得这个模型变成了随机模型,每次运动过程中的噪声是随机的。如果不理会这个噪声,只根据指令来确定位置,可能与实际位置差的很多。
这里uk是运动传感器的输入,wk 为该过程中加入的噪声。这称为运动方程。噪声的存在使得这个模型变成了随机模型,每次运动过程中的噪声是随机的。如果不理会这个噪声,只根据指令来确定位置,可能与实际位置差的很多。 -
什么是观测?假设机器人在k时刻,于xk处探测到了某一个路标yj,要考虑这件事情是如何用数学语言来描述的。
与运动方程相对应,观测方程描述的是:当机器人在xk位置上看到某个路标点yj时,产生了一个观测数据z(k,j):
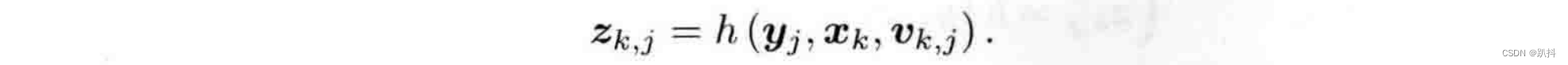
v(k,j)是这次观测里的噪声。
根据机器人的真实运动和传感器的种类,存在着若干种参数化方式(Parameterization)。
假设机器人在平面中运动,那么,它的位姿(位置和姿态)由两个位置和一个转角来描述,x1, x2 是两个轴上的位置而 θ 为转角,即
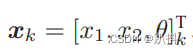
输入的指令是两个时间间隔位置和转角的变化量:
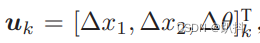
于是,此时运动方程可以化为:
并不是所有的输入指令都是位移和角度的变化量,比如“油门”或者 “控制杆”的输入就是速度或加速度量,存在着其他形式更加复杂的运动方程,我们需要进行动力学分析。
关于观测方程,以机器人携带着一个二维激光传感器为例。我们知道激光传感器观测一个2D路标点时,能够测到两个量:路标点与机器人本体之间的距离 r 和夹角 ϕ。
记路标点为
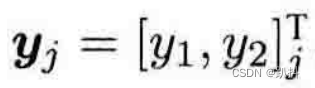
位姿为
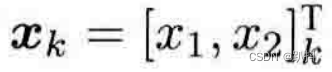
观测数据为
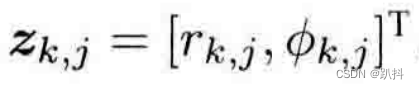
那么观测方程就写为:

其实就是一个勾股定理的事情。考虑视觉 SLAM 时,传感器是相机,那么观测方程就是“对路标点拍摄后,得到了图像中的像素”的过程。 针对不同的传感器,这两个方程有不同的参数化形式。取成通用的抽象形式,SLAM过程可总结为两个基本方程:
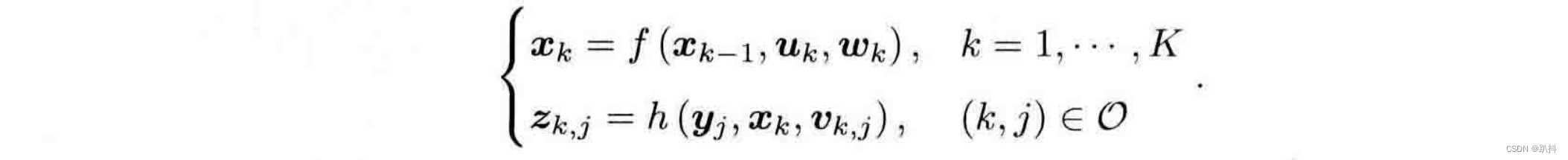
这两个方程描述了最基本的SLAM问题:当知道运动测量的读数u,以及传感器的读数z 时,如何求解定位问题(估计x)和建图问题(估计y)?这时,我们把 SLAM 问题建模成了一个状态估计问题:如何通过带有噪声的测量数据,估计内部的、隐藏着的状态变量?状态估计问题的求解,与两个方程的具体形式,以及噪声服从哪种分布有关。
我们按照运动和观测方程是否为线性,噪声是否服从高斯分布进行分类,分为线性/非线性和高斯/非高斯系统。其中线性高斯系统(Linear Gaussian, LG 系统)是最简单的,它的无偏的最优估计可以由卡尔曼滤波器(Kalman Filter, KF)给出。而在复杂的非线性非高斯系统 (Non-Linear Non-Gaussian,NLNG 系统)中,我们会使用以扩展卡尔曼滤波器(Extended Kalman Filter, EKF)和非线性优化两大类方法去求解它。
直至21世纪早期,以 EKF 为主的滤波器方法占据了 SLAM 中的主导地位。我们会在在工作点处把系统线性化,并以预测——更新两大步骤进行求解。最早的实时视觉SLAM系统即是基于EKF开发的。随后,为了克服 EKF 的缺点(例如线性化误差和噪声高斯分布假设),人们开始使用粒子滤波器(Particle Filter)等其他滤波器,乃至使用非线性优化的方法。时至今日,主流视觉 SLAM 使用以图优化(Graph Optimization)为代表的优化技术进行状态估计。我们认为优化技术已经明显优于滤波器技术,只要计算资源允许,我们通常都偏向于使用优化方法。
机器人更多时候是一个三维空间里的机器人。三维空间的运动由3个轴构成,所以机器人的运动要由3个轴上的平移,以及绕着3个轴的旋转来描述,这一共有6个自由度。在视觉SLAM 中,对6自由度的位姿如何表达,优化,需要三维空间刚体运动以及李群李代数的知识。观测方程如何参数化,即空间中的路标点是如何投影到一张照片上的,这需要解释相机的成像模型。最后,怎么求解上述方程?这需要非线性优化的知识。
-
相关阅读:
【无标题】
Mysql的四个隔离级别是如何实现的 (简要)
Vue 路由跳转设置不刷新
【JDBC笔记】获取数据库连接
web网页设计期末课程大作业:漫画网站设计——我的英雄(5页)学生个人单页面网页作业 学生网页设计成品 静态HTML网页单页制作
金融业务-房产业务
labuladong刷题——第一章(2) 反转单链表 (递归)
win10 pytorch安装说明
LSKA(大可分离核注意力):重新思考CNN大核注意力设计
基于Python+Pygame实现一个俄罗斯方块小游戏【完整代码】
- 原文地址:https://blog.csdn.net/PuddleRubbish/article/details/134342080