-
使用tesseract-ocr实现图片中的中英文字符提取
1 tesseract-ocr介绍
OCR(Optical Character Recognition):光学字符识别,是指对图片文件中的文字进行分析识别,获取的过程。
Tesseract:开源的OCR识别引擎,初期Tesseract引擎由HP实验室研发,后来贡献给了开源软件业,后经由Google进行改进,消除bug,优化,重新发布,支持100多种语言。
pytesseract是基于Python的OCR工具, 底层使用的是Google的Tesseract-OCR 引擎,支持识别图片中的文字,支持jpeg, png, gif, bmp, tiff等图片格式。
github地址:https://github.com/tesseract-ocr/tesseract
2 tesseract-ocr安装
2.1 程序安装
Mac和Linux安装方法参考:Introduction | tessdoc
windows系统安装方法详解:
- 下载与安装
window安装程序下载地址:Index of /tesseract,下载完成后,按向导安装
安装时可以选择需要的语言包:
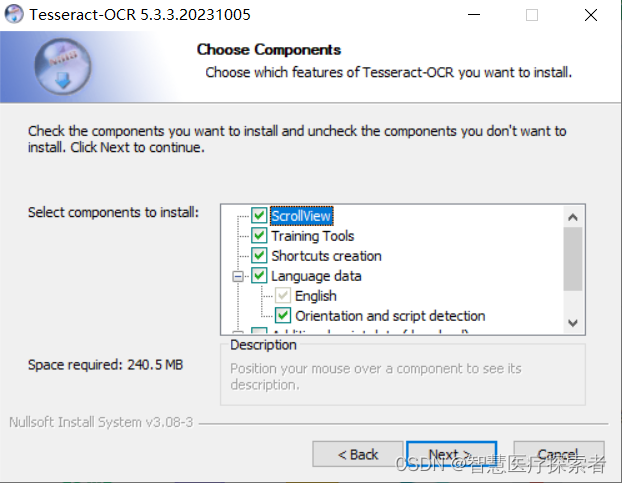
选择安装路径
注意:安装的路径要与python编写的程序放在同一个磁盘目录下。
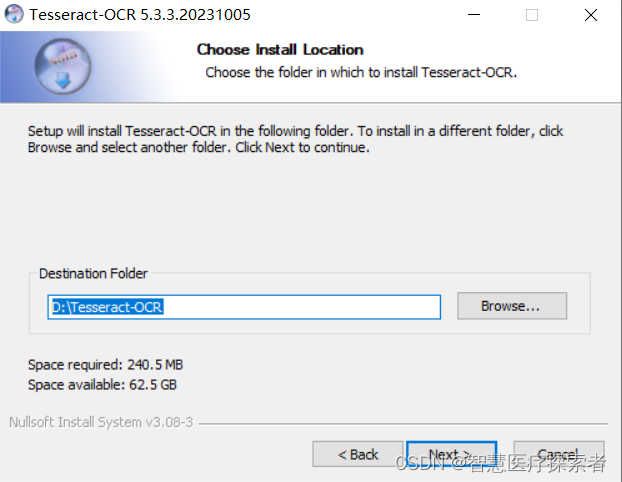
- 设置环境比变量
将tesseract的安装路径添加到PATH环境变量中:

增加名字为TESSDATA_PREFIX的系统变量,变量值设置为tesseract的安装路径

命令行窗口输入:
tesseract,查看是否安装成功。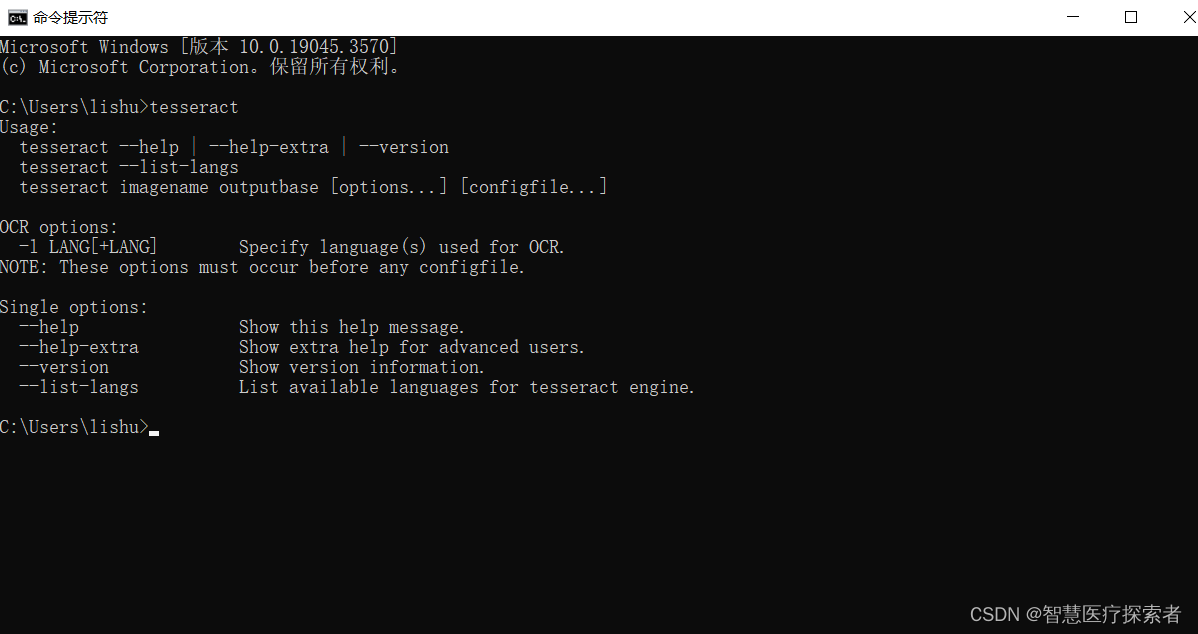
2.2 python工具包安装
- pip install pytesseract
- pip install Pillow
3 使用tesseract-ocr提取中英文字符
3.1 图片英文字符识别

- import pytesseract
- from PIL import Image
- # 列出支持的语言
- print(pytesseract.get_languages(config=''))
- image_path = '../data/ocr_englist.jpg'
- result = pytesseract.image_to_string(Image.open(image_path), lang='eng')
- print(result)
运行结果显示如下:
- ['eng', 'osd']
- Spring will come when spring goes.
3.2 图片中文字符识别
中英文模型:https://github.com/tesseract-ocr/tessdata/blob/main/chi_sim.traineddata
存储到‘D:\Tesseract-OCR\tessdata’目录下。

- import pytesseract
- from PIL import Image
- # 列出支持的语言
- print(pytesseract.get_languages(config=''))
- image_path = '../data/ocr_chinest.jpg'
- result = pytesseract.image_to_string(Image.open(image_path), lang='chi_sim')
- print(result)
运行结果如下:
- ['chi_sim', 'eng', 'osd']
- 短 评 : 中 美 各 自 的 成 功 是 彼 此 的 机 遇
-
相关阅读:
Linux 中如何安全地抹去磁盘数据?
【C++】类和对象(中)(万字详解)
16.在一行中懒加载图片
【一起进大厂】最新Java并发面试题整理
计算机毕业设计之java+javaweb的学生信息管理系统
一篇博客学会系列(1) —— C语言中所有字符串函数以及内存函数的使用和注意事项
Mediasoup在node.js下多线程实现
深入探讨Go中的字典
MSC 307(88) (2010 FTPC Code) Part 5低播焰测试
达摩克利斯之剑:开源软件的合规风险及防控策略
- 原文地址:https://blog.csdn.net/lsb2002/article/details/134429406