-
C++入门(2)—函数重载、引用
目录
接上一小节C++入门(1)—命名空间、缺省参数
一、函数重载
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数 或 类型 或 类型顺序)不同,常用来处理实现功能类似数据类型不同的问题。1、参数类型不同
下面代码中有两个add函数,他们的参数类型不同,当我们调用add函数时,add函数会根据传入参数的类型自动判断调用哪个add函数。
- int add(int a, int b)
- {
- cout << a + b << endl;
- return 0;
- }
- double add(double a, double b)
- {
- cout << a + b << endl;
- return 0;
- }
- int main()
- {
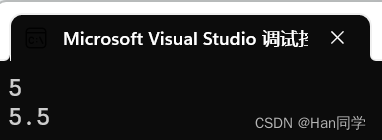
- add(2, 3);
- add(2.2, 3.3);
- return 0;
- }
我们传入整型则调用计算整形的add函数,传入浮点型则调用计算浮点型的add函数。
2、参数个数不同
函数根据参数个数自动匹配。
- void f(int a,int b)
- {
- cout << a+b << endl;
- }
- void f(int a)
- {
- cout << a << endl;
- }
- int main()
- {
- f(6+6);
- f(6);
- return 0;
- }

3、参数顺序不同
函数根据不同类型的顺序自动匹配。
- void f(int a, char b)
- {
- cout << a << b << endl;
- }
- void f(char b, int a)
- {
- cout << b << a <}int main(){f('a', 6);f(6, 'a');return 0;}

注意:函数重载不会变慢,因为匹配对应函数是在编译时完成的。
4、 链接中如何区分函数重载
- int Add(int left, int right)
- {
- cout << "int Add(int left, int right)" << endl;
- return left + right;
- }
- double Add(double left, double right)
- {
- cout << "double Add(double left, double right)" << endl;
- return left + right;
- }
- int main()
- {
- Add(1, 2);
- Add(1.1, 2.2);
- return 0;
- }
在VS调试中转到反汇编,可以看出Add函数都是通过call Add去调用的,那么链接器怎么区分链接哪个呢?
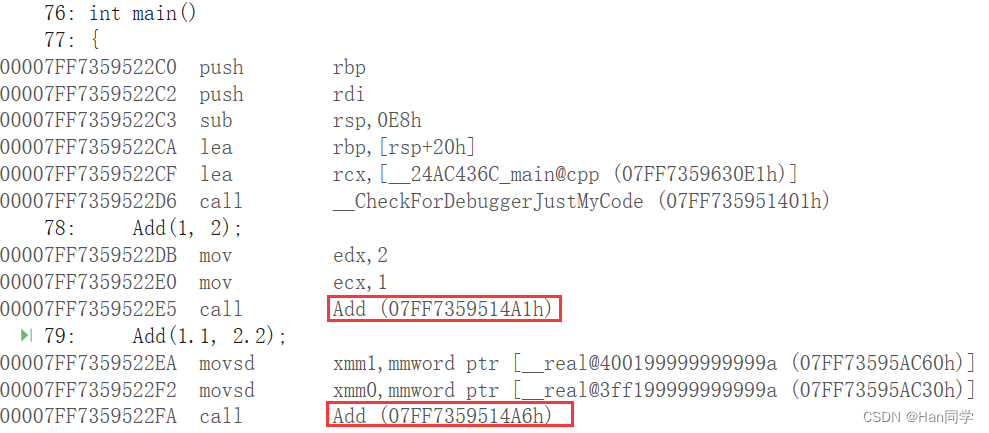
答案:编译器会对函数名进行修饰,不同编译器对函数名的修饰规则不同,由于VS的规则太复杂,我们在linux下g++编译器中查看C++函数的汇编指令。
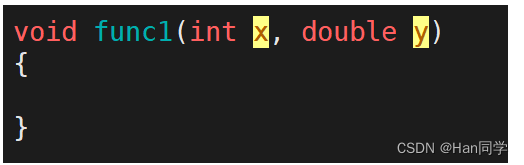 在linux下,采用g++编译完成后,函数名字的修饰发生改变,编译器将函数参数类型信息添加到修改后的名字中,我们也可以发现它的修饰规则为_Z+函数名长度+函数名+参数类型首字母。
在linux下,采用g++编译完成后,函数名字的修饰发生改变,编译器将函数参数类型信息添加到修改后的名字中,我们也可以发现它的修饰规则为_Z+函数名长度+函数名+参数类型首字母。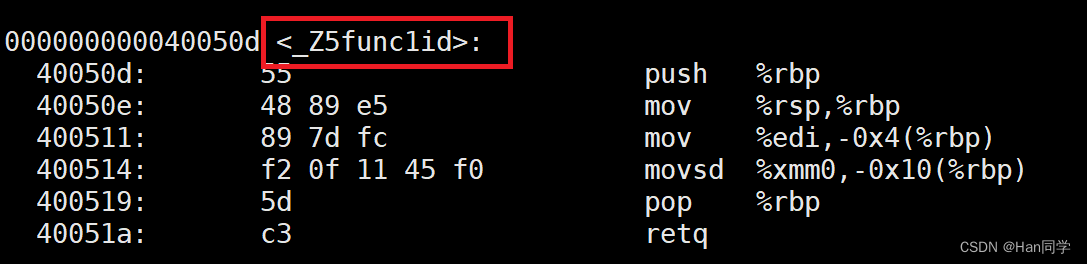
- 通过这里就理解了C语言没办法支持重载,因为同名函数没办法区分。而C++是通过函数修饰规则来区分,只要参数不同,修饰出来的名字就不一样,就支持了重载。
- .如果两个函数函数名和参数是一样的,返回值不同是不构成重载的,因为调用时编译器没办法区分。
二、引用
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。1、规则
类型& 引用变量名(对象名) = 引用实体;
- int main()
- {
- int i = 0;
- int& k = i;//引用
- int j = i;
- cout << &i << endl;
- cout << &k << endl;
- cout << &j << endl;
- return 0;
- }
通过三者的地址可以发现,引用只是变量的别名。

如果我们对引用进行修改呢?
- int main()
- {
- int i = 0;
- int& k = i;//引用
- int j = i;
- k++;
- j++;
- cout << i << " " << k << " " << j << endl;
- return 0;
- }
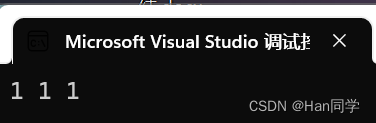
根据输出结果,修改引用的值,对应引用的变量也会被修改。
2、特征
- 引用在定义时必须初始化
int& a; // 该条语句编译时会出错 - 一个变量可以有多个引用
- int& a1 = a;//给a取别名
- int& a2 = a;//给a取别名
- int& a3 = a2;//给a2(a的别名)取别名也是可以的
- 引用一旦引用一个实体,再不能引用其他实体
- int a = 5;
- int b = 10;
- int& ref = a; // 将ref引用绑定到a上
- ref = b; // 此时a的值为10,而不是5,ref仍然绑定到a上
- int& ref2 = b; // 错误:ref已经绑定到a上,不能再绑定到其他实体上
我们来看下面代码:
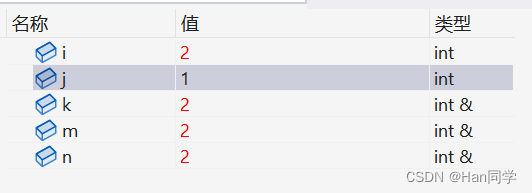
- int main()
- {
- int i = 0;
- int& k = i;//引用
- int j = i;
- k++;
- j++;
- int& m = i;
- int& n = k;
- ++n;
- return 0;
- }
- 定义变量 i 初始化为0,定义 k 为 i 的引用,变量 j 被赋值为 i 的值。
- 分别对 k 和 j 的值自增。
- 定义两个分别对变量 i 和 k 的引用,对n进行自增。
可以看出修改引用的值也就是修改被引用的变量的值。
3、使用场景
做参数
通常在写交换两个变量的函数Swap时,一般会借助指针修改变量的值。
- void Swap(int* i, int* j)
- {
- int tmp = *i;
- *i = *j;
- *j = tmp;
- }
- int main()
- {
- int i = 0, j = 1;
- Swap(&i, &j);
- printf("i=%d,j=%d", i, j);
- return 0;
- }
当我们掌握引用时,就可以借助引用来传参,函数接受两个整型引用变量 x 和 y 作为参数。
- void _Swap(int& x, int& y)
- {
- int tmp = x;
- x = y;
- y = tmp;
- }
- int main()
- {
- int i = 0, j = 1;
- _Swap(i, j);
- printf("i=%d,j=%d\n", i, j);
- return 0;
- }

在之前学习的单链表中,为了修改指向节点结构体的指针中的结构体成员*next,我们需要使用二级指针接收指针的地址,才能修改指针指向的内容。
不过,这次我们学习了引用,使用引用在传参时可以只传参指针,无需地址。
- typedef struct Node
- {
- struct Node* next;
- int val;
- }Node, * PNode;
- void PushBack(Node*& phead, int x)
- {
- Node* newNode = (Node*)malloc(sizeof(Node));
- if (phead == nullptr)
- {
- phead = newNode;
- }
- }
- int main()
- {
- Node* plist = NULL;
- PushBack(plist, 1);
- PushBack(plist, 2);
- PushBack(plist, 3);
- return 0;
- }
我们可以看到,在PushBack函数中,使用了指针和引用结合的方法 ,具体来说,在PushBack函数中,参数phead是一个指向指针的引用,这意味着我们可以通过修改phead来修改函数外部的指针变量plist。
再来看这种传值方式。
- void PushBack(PNode& phead, int x)
这两个函数的参数类型不同,分别是PNode&和Node*&,它们的区别在于传递参数的方式不同。
- void PushBack(PNode& phead, int x)中的PNode&是一个指向指针的引用类型,它表示一个指向Node结构体指针的引用。
- 而void PushBack(Node*& phead, int x)中的Node*&是一个指向指针的指针类型,它表示一个指向Node结构体指针的指针。
做返回值
我们先来看看常规函数返回值赋值的过程。
- int Count()
- {
- int n = 0;
- n++;
- return n;
- }
- int main()
- {
- int ret = Count();
- return 0;
- }
实际上函数返回值 n 的值传给 ret 是借助一个临时变量实现的,临时变量通常由寄存器(一般存4/8字节)充当,如果较大,则在调用函数之前,在main函数的栈帧中提前开一块空间充当临时变量,调用Count函数时,在调用结束销毁之前把返回值拷贝给main函数的临时变量,然后main函数的临时变量再拷贝给ret。
在函数栈帧中过程如下:
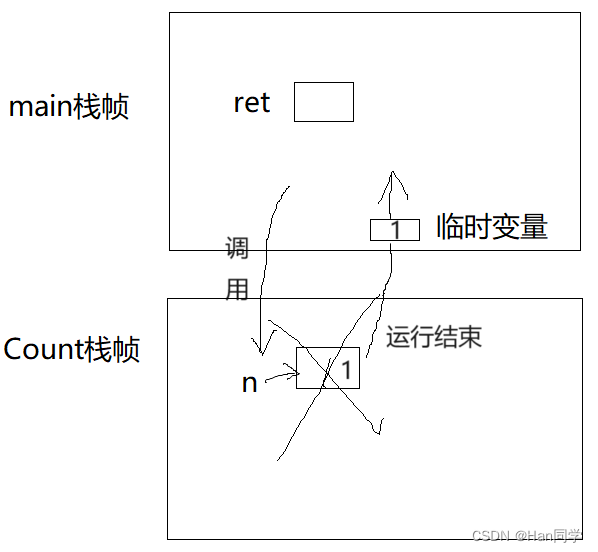
如果n在静态区, 也需要借助临时变量将返回值拷贝给ret。
- int Count()
- {
- static int n = 0;
- n++;
- return n;
- }
- int main()
- {
- int ret = Count();
- return 0;
- }
上述全局变量 n 传值返回的情况所借助的临时变量有些多余,使用传引用返回可以很好解决。
接下来是使用引用作为返回值类型的函数,借助返回值为引用类型产生返回值n的别名,相当于传n的值,减少借助临时变量拷贝的过程,节约时间提高效率。
- int& Count()
- {
- static int n = 0;
- n++;
- return n;
- }
- int main()
- {
- int ret = Count();
- return 0;
- }
只要出了count作用域不影响变量的生命周期,就可以使用传引用返回。
使用引用返回的好处:
- 减少拷贝
- 调用者可以修改返回对象
使用引用返回条件:
- 函数返回时,出了函数作用域,如果返回对象还在(还没还给系统,比如:静态作用域,全局变量,位于上一层栈帧,malloc的等等),则可以使用引用返回,如果已经还给系统,则必须使用传值返回。
下面这段代码使用了引用相关的语法来实现对数组元素的访问和修改,这种方式可以提高程序的效率并使代码更加简洁易读。
- #define N 10
- typedef struct Array
- {
- int a[N];
- int size;
- }AY;
- int& PosAt(AY& ay, int i)
- {
- assert(i < N);
- return ay.a[i];
- }
- int main()
- {
- int ret = Count();
- AY ay;
- for (int i = 0; i < N; ++i)
- PosAt(ay, i) = i*10;
- for (int i = 0; i < N; ++i)
- cout << PosAt(ay, i) << " ";
- cout << endl;
- return 0;
- }
如果使用引用返回,结果是未定义的。
接下来看这段代码:
- int& Add(int a, int b)
- {
- int c = a + b;
- return c;
- }
- int main()
- {
- int& ret = Add(1, 2);
- Add(3, 4);
- cout << "Add(1, 2) is :" << ret << endl;
- cout << "Add(1, 2) is :" << ret << endl;
- return 0;
- }
- 在这段代码中,Add函数返回了一个局部变量c的引用。然而,这是一种未定义行为,因为当函数返回时,局部变量c的生命周期就结束了,它所占用的内存空间可能被其他变量或函数使用,这意味着返回的引用可能指向一个无效的内存地址。
- 在main函数中,我们将Add函数的返回值赋值给了ret变量。这里,ret并不是c的引用的引用,而是一个新的变量,它的值是通过复制Add函数返回的引用得到的。然而,由于Add函数返回的引用可能指向一个无效的内存地址,因此ret的值可能是不确定的。
- 然后,我们再次调用了Add函数,但没有将返回值存储在任何变量中。这次调用可能会改变c所占用的内存空间的值,从而影响ret变量的值。
- 最后,我们使用cout语句输出ret变量的值两次。由于ret的值可能是不确定的,因此这些输出语句可能会产生不可预测的结果。
- 总的来说,这段代码存在问题,因为它返回了一个局部变量的引用,这是一种未定义行为。为了避免这种问题,我们应该避免返回局部变量的引用,或者使用动态分配的内存、静态变量或全局变量来存储返回值。
4、常引用
在引用的过程中:
- 权限可以平移
- 权限可以缩小
- 权限不可以放大
- int Count()
- {
- int n = 0;
- n++;
- return n;
- }
- int main()
- {
- int a = 1;
- int& b = a;
- // 指针和引用,赋值/初始化 权限可以缩小,但是不能放大
- // 权限放大
- /*const int c = 2;
- int& d = c;
- const int* p1 = NULL;
- int* p2 = p1;*/
- // 权限保持
- const int c = 2;
- const int& d = c;
- const int* p1 = NULL;
- const int* p2 = p1;
- // 权限缩小
- int x = 1;
- const int& y = x;
- int* p3 = NULL;
- const int* p4 = p3;
- // 权限可以缩小不能放大只适用于指针和引用
- const int m = 1;
- int n = m;//正确的
- //函数传值返回,借助临时变量传值,临时变量不能修改
- const int& ret = Count();//const保持权限一致
- //类型转换都会产生临时变量
- int i = 10;
- cout << (double)i << endl;//显式类型转换
- double dd = i;//隐式类型转换
- const double& rd = i;
- return 0;
- }
5、传值、传引用效率比较
- #include
- struct A { int a[10000]; };
- void TestFunc1(A a) {}
- void TestFunc2(A& a) {}
- void TestRefAndValue()
- {
- A a;
- // 以值作为函数参数
- size_t begin1 = clock();
- for (size_t i = 0; i < 10000; ++i)
- TestFunc1(a);
- size_t end1 = clock();
- // 以引用作为函数参数
- size_t begin2 = clock();
- for (size_t i = 0; i < 10000; ++i)
- TestFunc2(a);
- size_t end2 = clock();
- // 分别计算两个函数运行结束后的时间
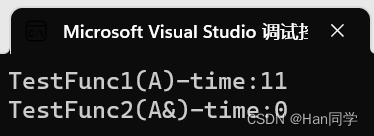
- cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;
- cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;
- }
- int main()
- {
- TestRefAndValue();
- return 0;
- }
传引用的速度小于1毫秒,所以显示消耗时间为0,可以看出传引用的效率非常高。
在C++中,传引用比传值效率高的原因主要有以下几点:
-
避免复制操作:当我们通过值传递参数时,实际上是在内存中创建了一个新的对象,然后将原对象的值复制到新对象中。这个复制操作可能非常消耗资源,特别是当对象很大时。而通过引用传递参数,我们只是传递了对象的地址,没有进行复制操作,因此效率更高。
-
节省内存空间:由于传引用只是传递了对象的地址,而不是复制整个对象,所以它使用的内存空间更少。
-
可以修改原对象:当我们需要在函数中修改原对象时,必须通过引用或指针传递参数。如果通过值传递参数,函数将操作的是原对象的一个副本,原对象不会被修改。
6、引用和指针的区别
-
概念:引用是一个已存在变量的别名,它们共享同一块内存空间。而指针则是一个变量的地址。
-
初始化:引用在定义时必须初始化,且一旦引用了一个实体,就不能再引用其他实体。相反,指针可以在任何时候指向任何同类型实体,初始化不是必须的。
-
NULL值:不存在NULL引用,但可以有NULL指针。
-
sizeof运算符:对引用使用sizeof运算符,结果为引用类型的大小;对指针使用sizeof运算符,结果始终是地址空间所占字节个数(例如,在32位平台下占4个字节)。
-
自增操作:引用自增意味着引用的实体增加1,而指针自增则意味着指针向后偏移一个类型的大小。
-
级别:存在多级指针,但没有多级引用。
-
访问实体方式:访问指针指向的实体需要显式解引用,而访问引用指向的实体时,编译器会自动处理。
-
安全性:相比于指针,引用在使用时相对更安全。
-
在底层实现上,引用实际上是有空间的,因为它是通过指针方式来实现的。但在语法概念上,引用被视为别名,没有独立的空间。
- 相关阅读:
nginx反向代理与负载均衡
Centos安装gitlabce
网络基础入门:数据通信与网络基础
Linux下通过yum安装nginx【详细步骤】
机器学习 vs. 数值天气预报,AI 如何改变现有的天气预报模式
芯科科技与Arduino携手推动Matter普及化
二分搜索篇
nginx反向代理tcp网络访问
2022-11-07 Excel的函数使用
docker 安装(unbuntu安装)
- 原文地址:https://blog.csdn.net/m0_73800602/article/details/134407893
