-
数据结构与算法【递归】Java实现
递归
递归是一种解决计算问题的方法,其中解决方案取决于同一类问题的更小子集。
特点:
- 自己调用自己,如果说每个函数对应着一种解决方案,自己调用自己意味着解决方案是一样的(有规律的)
- 每次调用,函数处理的数据会较上次缩减(子集),而且最后会缩减至无需继续递归
- 内层函数调用(子集处理)完成,外层函数才能算调用完成
递归二分查找
具体实现代码如下
- public int f(int[] a, int target, int i, int j) {
- if (i > j) {
- return -1;
- }
- int m = (i + j) >>> 1;
- if (target < a[m]) {
- return f(a, target, i, m - 1);
- } else if (a[m] < target) {
- return f(a, target, m + 1, j);
- } else {
- return m;
- }
- }
递归冒牌排序
未排区域为[0,j],已排区域为[j,数组长度-1]
具体实现代码如下
- public void bubbleSort(int[] a, int j) {
- if (j==0){
- return;
- }
- int temp;
- for (int i = 1; i < j; i++) {
- if (a[i-1] > a[i]) {
- temp = a[i-1];
- a[i-1] = a[i];
- a[i] = temp;
- }
- }
- bubbleSort(a,j-1);
- }
但是这种实现方式存在一定的效率问题。比如说需要排序的数组为[1,2,3,4,5,7,6]。那么经过排序之后,应该为[1,2,3,4,5,6,7]。只需要将6,7交换就好。存在大量无用循环,因此我们可以对冒泡排序进行改进。使用变量x默认为0的位置,并接收上一次交换的下标值。当一次递归x仍然为0,则说明已经没有需要排序的元素了,因此可以直接结束递归。具体实现代码如下
- public static void bubbleSort2(int[] a, int j) {
- if (j == 0) {
- return;
- }
- int temp;
- int x = 0;
- for (int i = 1; i < j; i++) {
- if (a[i - 1] > a[i]) {
- temp = a[i - 1];
- a[i - 1] = a[i];
- a[i] = temp;
- x = i;
- }
- }
- bubbleSort2(a, x);
- }
递归实现插入排序
未排区域为[low,数组长度-1],已排区域为[0,low]
具体实现代码为
- public static void insertSort(int[] a, int low) {
- //结束递归条件
- if (low == a.length) {
- return;
- }
- int i = low - 1;
- int temp = a[low];
- //结束排序条件,当i=-1与找到第一个小于temp元素时
- while (i >= 0 && a[i] > temp) {
- a[i + 1] = a[i];
- i--;
- }
- a[i + 1] = temp;
- insertSort(a, low + 1);
- }
多路递归
上面的递归实现有一个特点就是每个递归函数只包含一个自身的调用,这称之为单路递归。如果每个递归函数例包含多个自身调用,称之为多路递归。
多路递归的经典案例:斐波那契数列
递推关系如下:
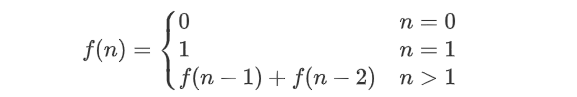
简单实现
- public static int f(int n) {
- if (n == 0) {
- return 0;
- }
- if (n == 1) {
- return 1;
- }
- return f(n - 1) + f(n - 2);
- }
斐波那契数列的变种问题
兔子问题
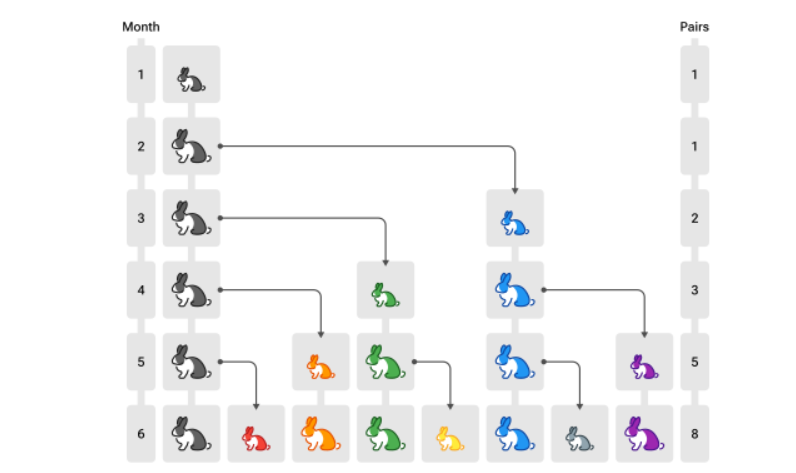
- 第一个月,有一对未成熟的兔子(黑色,注意图中个头较小)
- 第二个月,它们成熟
- 第三个月,它们能产下一对新的小兔子(蓝色)
- 所有兔子遵循相同规律,求第n个月的兔子数
解决思路:设第 n 个月兔子数为 f(n)
- f(n) = 上个月兔子数 + 新生的小兔子数
- 而【新生的小兔子数】实际就是【上个月成熟的兔子数】
- 因为需要一个月兔子就成熟,所以【上个月成熟的兔子数】也就是【上上个月的兔子数】
- 上个月兔子数,即 f(n-1)
- 上上个月的兔子数,即 f(n-2)
简单实现
- public static int rabbit(int n){
- if (n==1){
- return 1;
- }
- if (n==2){
- return 1;
- }
- return rabbit(n-1)+rabbit(n-2);
- }
青蛙爬楼梯
- 楼梯有 n 阶
- 青蛙要爬到楼顶,可以一次跳一阶,也可以一次跳两阶
- 只能向上跳,问有多少种跳法
解决思路:因为最后一跳只能为1或是2,那么当从第三个台阶开始时,跳法等于一个台阶的跳法加两个台阶的跳法之和
斐波那契数列的优化
在之前的实现代码中,它的运算流程如下

可以看到,存在许多重复运算。因此我们可以对其进行记忆化(做缓存)
- public static int cache(int n) {
- int[] cache = new int[n + 1];
- Arrays.fill(cache, -1);
- cache[0] = 0;
- cache[1] = 1;
- return f1(cache, n);
- }
- public static int f1(int[] cache, int n) {
- if (cache[n] != -1) {
- return cache[n];
- }
- int x = f1(cache, n - 1);
- int y = f1(cache, n - 2);
- cache[n] = x + y;
- return cache[n];
- }
这种实现方式采用了以空间换取时间。
爆栈问题
每次调用方法时,JVM会给该方法分配一个内存空间,当递归次数过多时内存也会占用过多,当内存分配完毕,还要接着递归时,就会抛出StackOverflowError异常
尾调用
如果函数的最后一步是调用一个函数,那么称为尾调用,例如
- function a() {
- return b()
- }
下面代码不能叫做尾调用
- function a() {
- const c = b()
- return c
- }
- 因为最后一步并非调用函数
- function a() {
- return b() + 1
- }
- 最后一步执行的是加法
一些语言的编译器能够对尾调用做优化,例如
- function a() {
- // 做前面的事
- return b()
- }
- function b() {
- // 做前面的事
- return c()
- }
- function c() {
- return 1000
- }
没优化之前的伪码
- function a() {
- return function b() {
- return function c() {
- return 1000
- }
- }
- }
优化后伪码如下
- a()
- b()
- c()
相当于平级调用,而不是嵌套调用。之所以可以这样优化,是因为a的函数返回结果就是b的返回结果,那么a的内存可以直接释放。b的返回结果是c的返回结果,那么也可以直接释放b所占用的内存。
但是Java并不支持这种尾调用优化。因此需要避免递归次数过多导致的爆栈问题。
-
相关阅读:
CYarp:力压frp的C#高性能http内网反代中间件
【SpringBoot实战系列】阿里云OSS接入上传图片实战
轻松合并视频,一键为视频添加封面,打造个性化批量剪辑!
Spring AOP全面详解(超级详细)
[基础服务] 常用邮箱服务地址
(60)MIPI D-PHY介绍(二十)
十大排序算法Java实现及时间复杂度
2311rust,到35版本更新
Docker停电事件未解之谜
开放内容处理框架(OCPF),轻松玩转各类数据处理
- 原文地址:https://blog.csdn.net/zmbwcx/article/details/134407510
