-
深度学习100例-卷积神经网络(CNN)实现mnist手写数字识别 | 第1天
前期工作
1. 设置GPU(如果使用的是CPU可以忽略这步)
我的环境:
- 语言环境:Python3.6.5
- 编译器:jupyter notebook
- 深度学习环境:TensorFlow2.4.1
import tensorflow as tf gpus = tf.config.list_physical_devices("GPU") if gpus: gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPU tf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用 tf.config.set_visible_devices([gpu0],"GPU")- 1
- 2
- 3
- 4
- 5
- 6
- 7
2. 导入数据
import tensorflow as tf from tensorflow.keras import datasets, layers, models import matplotlib.pyplot as plt (train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()- 1
- 2
- 3
- 4
- 5
3.归一化
# 将像素的值标准化至0到1的区间内。 train_images, test_images = train_images / 255.0, test_images / 255.0 train_images.shape,test_images.shape,train_labels.shape,test_labels.shape- 1
- 2
- 3
- 4
4.可视化
plt.figure(figsize=(20,10)) for i in range(20): plt.subplot(5,10,i+1) plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(train_images[i], cmap=plt.cm.binary) plt.xlabel(train_labels[i]) plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

5.调整图片格式
#调整数据到我们需要的格式 train_images = train_images.reshape((60000, 28, 28, 1)) test_images = test_images.reshape((10000, 28, 28, 1)) # train_images, test_images = train_images / 255.0, test_images / 255.0 train_images.shape,test_images.shape,train_labels.shape,test_labels.shape- 1
- 2
- 3
- 4
- 5
- 6
- 7
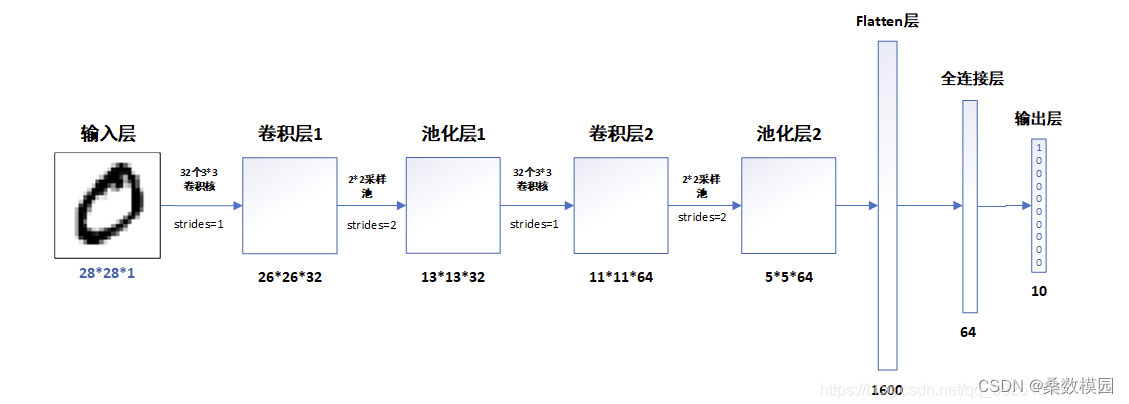
二、构建CNN网络模型
model = models.Sequential([ layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)), layers.MaxPooling2D((2, 2)), layers.Conv2D(64, (3, 3), activation='relu'), layers.MaxPooling2D((2, 2)), layers.Flatten(), layers.Dense(64, activation='relu'), layers.Dense(10) ]) model.summary()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 26, 26, 32) 320 max_pooling2d (MaxPooling2D (None, 13, 13, 32) 0 ) conv2d_1 (Conv2D) (None, 11, 11, 64) 18496 max_pooling2d_1 (MaxPooling (None, 5, 5, 64) 0 2D) flatten (Flatten) (None, 1600) 0 dense (Dense) (None, 64) 102464 dense_1 (Dense) (None, 10) 650 ================================================================= Total params: 121,930 Trainable params: 121,930 Non-trainable params: 0 _________________________________________________________________- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
三、编译模型
model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy'])- 1
- 2
- 3
四、训练模型
history = model.fit(train_images, train_labels, epochs=10, validation_data=(test_images, test_labels))- 1
- 2
Epoch 1/10 1875/1875 [==============================] - 15s 8ms/step - loss: 0.1429 - accuracy: 0.9562 - val_loss: 0.0550 - val_accuracy: 0.9803 Epoch 2/10 1875/1875 [==============================] - 14s 7ms/step - loss: 0.0460 - accuracy: 0.9856 - val_loss: 0.0352 - val_accuracy: 0.9883 Epoch 3/10 1875/1875 [==============================] - 13s 7ms/step - loss: 0.0312 - accuracy: 0.9904 - val_loss: 0.0371 - val_accuracy: 0.9880 Epoch 4/10 1875/1875 [==============================] - 14s 7ms/step - loss: 0.0234 - accuracy: 0.9925 - val_loss: 0.0330 - val_accuracy: 0.9900 Epoch 5/10 1875/1875 [==============================] - 14s 8ms/step - loss: 0.0176 - accuracy: 0.9944 - val_loss: 0.0311 - val_accuracy: 0.9904 Epoch 6/10 1875/1875 [==============================] - 16s 9ms/step - loss: 0.0136 - accuracy: 0.9954 - val_loss: 0.0300 - val_accuracy: 0.9911 Epoch 7/10 1875/1875 [==============================] - 14s 8ms/step - loss: 0.0109 - accuracy: 0.9964 - val_loss: 0.0328 - val_accuracy: 0.9909 Epoch 8/10 1875/1875 [==============================] - 14s 7ms/step - loss: 0.0097 - accuracy: 0.9969 - val_loss: 0.0340 - val_accuracy: 0.9903 Epoch 9/10 1875/1875 [==============================] - 15s 8ms/step - loss: 0.0078 - accuracy: 0.9974 - val_loss: 0.0499 - val_accuracy: 0.9879 Epoch 10/10 1875/1875 [==============================] - 13s 7ms/step - loss: 0.0078 - accuracy: 0.9976 - val_loss: 0.0350 - val_accuracy: 0.9902- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
五、预测
通过下面的网络结构我们可以简单理解为,输入一张图片,将会得到一组数,这组代表这张图片上的数字为0~9中每一个数字的几率,out数字越大可能性越大。
plt.imshow(test_images[1])- 1
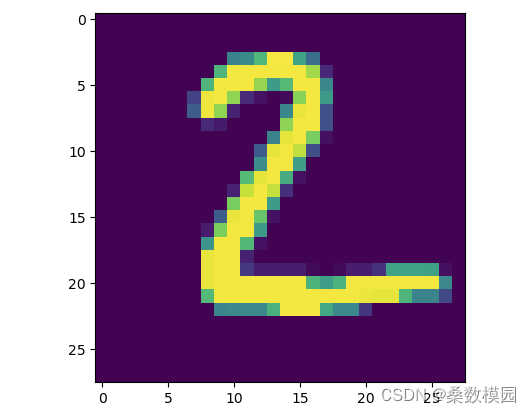
输出测试集中第一张图片的预测结果
pre = model.predict(test_images) pre[1]- 1
- 2
313/313 [==============================] - 1s 2ms/step array([ 3.3290668 , 0.29532072, 21.943724 , -7.09336 , -15.3133955 , -28.765621 , -1.8459738 , -5.761892 , -2.966585 , -19.222878 ], dtype=float32)- 1
- 2
- 3
- 4
六、知识点详解
本文使用的是最简单的CNN模型- -LeNet-5,如果是第一次接触深度学习的话,可以先试着把代码跑通,然后再尝试去理解其中的代码。
1. MNIST手写数字数据集介绍
MNIST手写数字数据集来源于是美国国家标准与技术研究所,是著名的公开数据集之一。数据集中的数字图片是由250个不同职业的人纯手写绘制,数据集获取的网址为:http://yann.lecun.com/exdb/mnist/ (下载后需解压)。我们一般会采用
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()这行代码直接调用,这样就比较简单MNIST手写数字数据集中包含了70000张图片,其中60000张为训练数据,10000为测试数据,70000张图片均是
28*28,数据集样本如下:
如果我们把每一张图片中的像素转换为向量,则得到长度为
28*28=784的向量。因此我们可以把训练集看成是一个[60000,784]的张量,第一个维度表示图片的索引,第二个维度表示每张图片中的像素点。而图片里的每个像素点的值介于0-1之间。
2. 神经网络程序说明
神经网络程序可以简单概括如下:
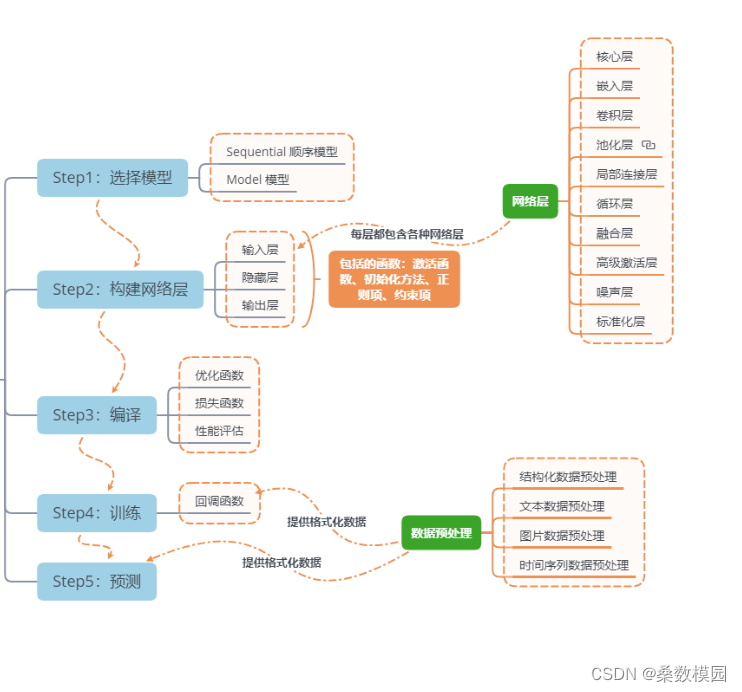
3. 网络结构说明
各层的作用
- 输入层:用于将数据输入到训练网络
- 卷积层:使用卷积核提取图片特征
- 池化层:进行下采样,用更高层的抽象表示图像特征
- Flatten层:将多维的输入一维化,常用在卷积层到全连接层的过渡
- 全连接层:起到“特征提取器”的作用
-
相关阅读:
51单片机简易时钟闹钟八位数码管显示仿真( proteus仿真+程序+原理图+报告+讲解视频)
Windows重定向技术【文件重定向与注册表重定向】
【算法速查】一篇文章带你快速入门八大排序(上)
a标签设置下划线动画
上传npm包到私有nexus仓库中《解决服务端安装npm依赖失败的问题》
Python——基础
线性搜索简介
洛谷刷题C语言:ZAMKA、Number、子弦、NOI、Emacs
教培机构如何线上抢客招生?
微软推送win11 22622.575补丁!
- 原文地址:https://blog.csdn.net/weixin_45822638/article/details/134429465