-
开放领域问答机器人2——开发流程和方案
开放领域问答机器人是指在任何领域都能够回答用户提问的智能机器人。与特定领域问答机器人不同,开放领域问答机器人需要具备更广泛的知识和更灵活的语义理解能力,以便能够回答各种不同类型的问题。
开发开放领域问答机器人的流程和方案可以包括以下步骤:
- 需求分析:明确机器人的功能和特性,包括问题类型、答案来源、用户交互方式等。
- 数据收集和处理:收集和整理相关的数据,包括文本、语音、图像等,并进行预处理,如分词、去除停用词、词性标注等。
- 模型训练:选择合适的机器学习或深度学习模型,如循环神经网络、卷积神经网络、BERT等,并进行训练。
- 模型评估和优化:对训练好的模型进行评估和优化,如使用交叉验证、调整超参数等。
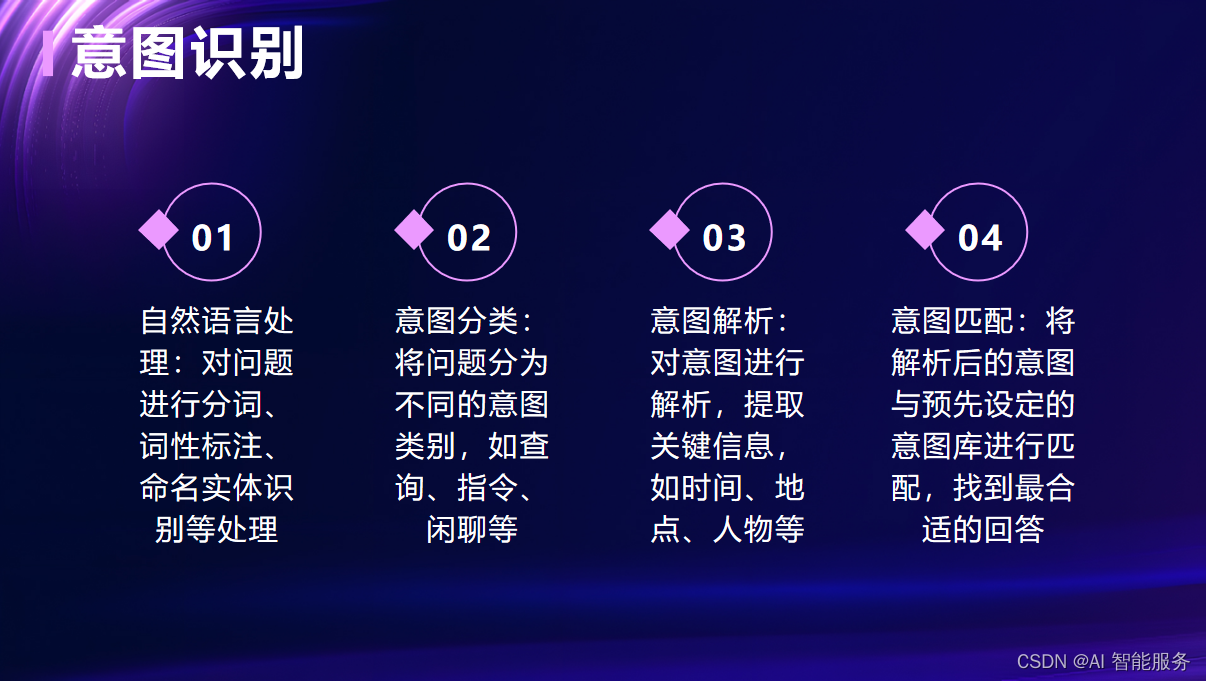
- 自然语言处理:设计和开发与用户交互的对话系统,包括自然语言理解(NLU)和自然语言生成(NLG)模块。NLU模块将用户输入的问题转化为机器可理解的表示形式,NLG模块则将机器生成的答案转化为自然语言。
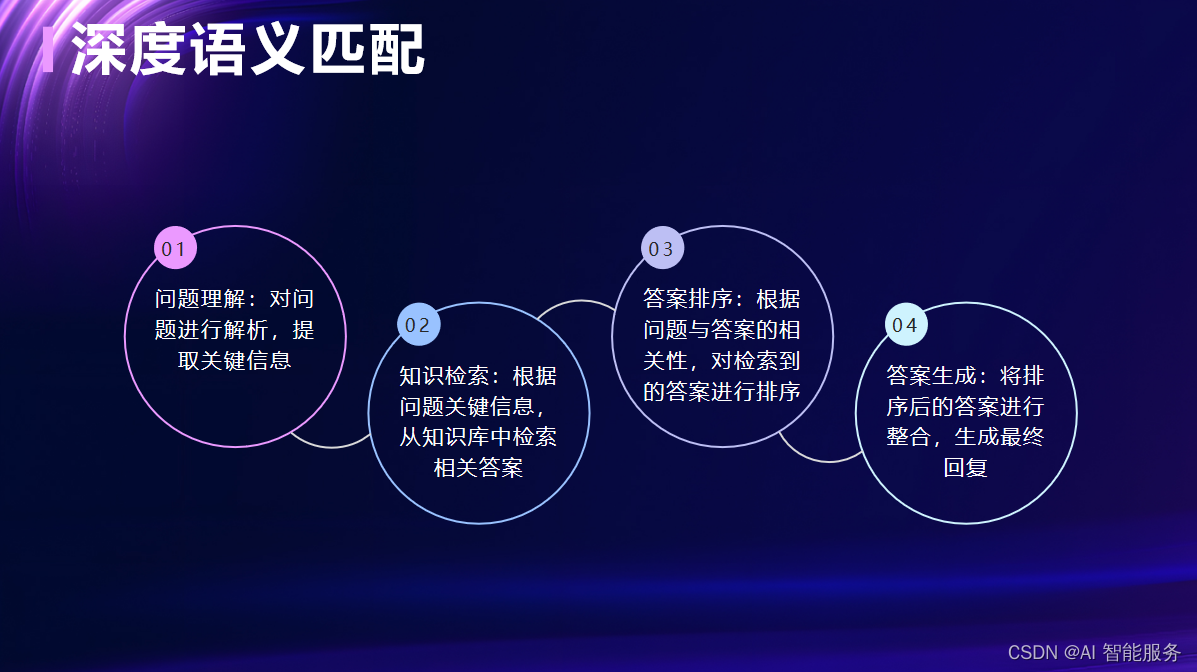
- 测试和评估:对开发的问答机器人进行测试和评估,检查其回答的准确性、流畅度和实用性。通过人工评估和自动评估指标进行结果分析和改进。
- 部署和上线:将问答机器人部署到实际应用环境中,并进行线上测试和调优。监控机器人的性能和用户反馈,及时修复问题并提供持续的优化和升级。
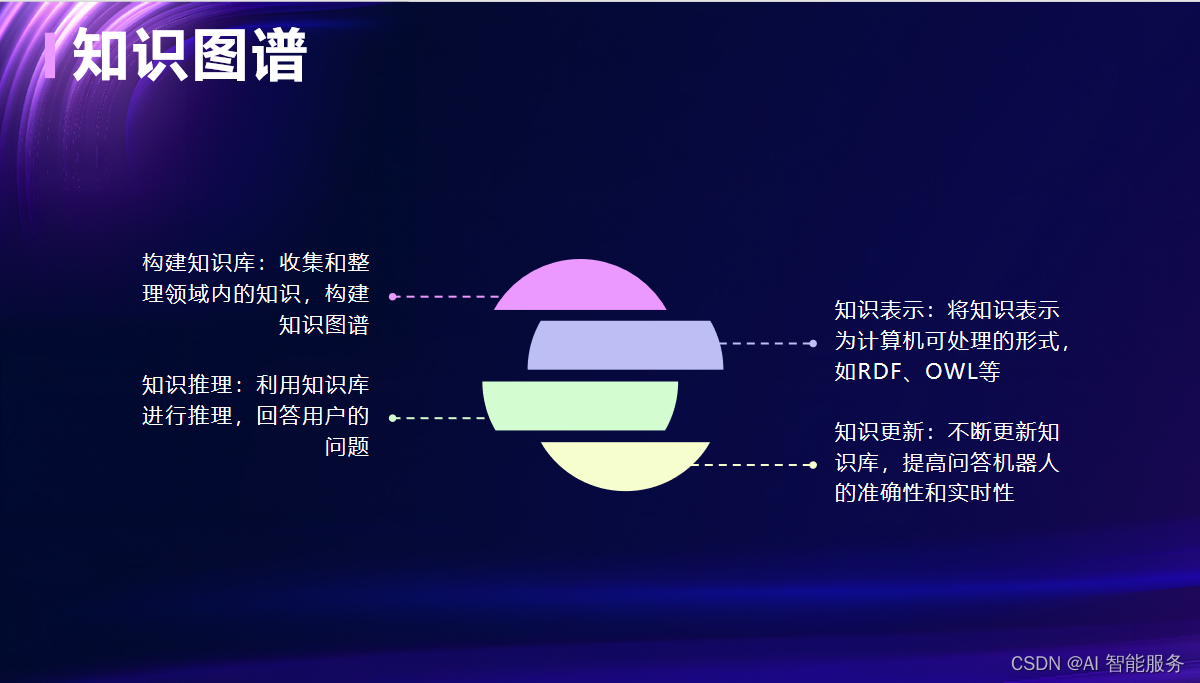
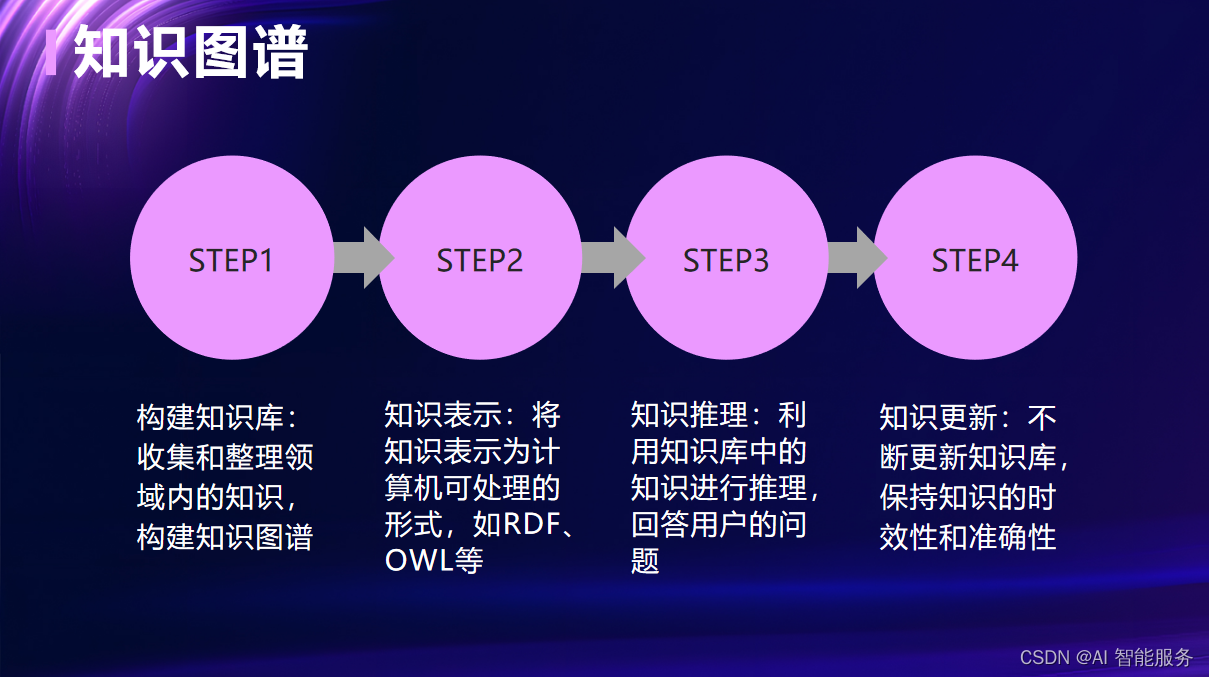
- 持续改进:根据用户反馈和需求变化,不断改进和扩展问答机器人的功能和性能。定期更新知识库和模型,保持机器人的准确性和实用性。
下面我们来看看开发流程:
1.开发流程




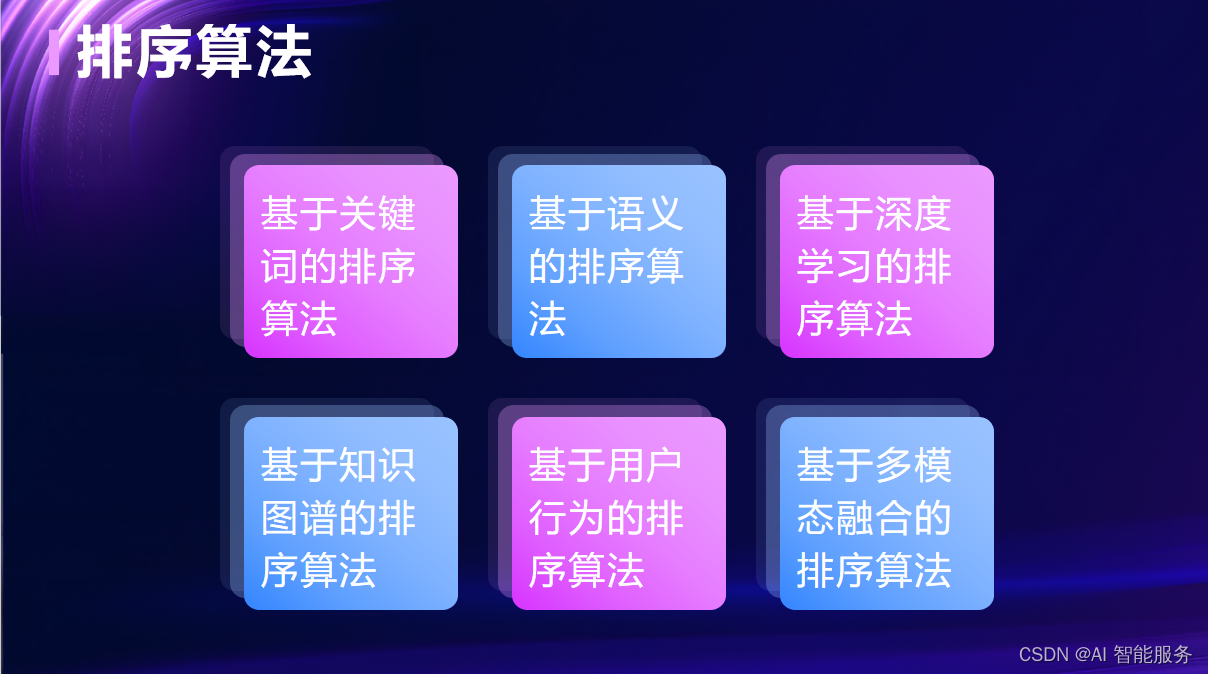
1.1排序算法

- def bubble_sort(arr):
- n = len(arr)
- # 遍历所有数组元素
- for i in range(n):
- # 最后 i 个元素已经有序,无需比较
- for j in range(0, n-i-1):
- # 遍历数组,从 0 到 n-i-1,如果当前元素比下一个元素大,则交换它们
- if arr[j] > arr[j+1] :
- arr[j], arr[j+1] = arr[j+1], arr[j]
- # 测试算法
- arr = [64, 34, 25, 12, 22, 11, 90]
- bubble_sort(arr)
- print("排序后的数组:")
- for i in range(len(arr)):
- print("%d" %arr[i]),
1.2计算相似度
要计算问题与候选答案之间的相似度,可以使用各种相似度计算方法,如余弦相似度、Jaccard相似度或编辑距离。以下是使用余弦相似度计算问题与候选答案之间相似度的示例Python代码:
- import numpy as np
- from sklearn.metrics.pairwise import cosine_similarity
- # 假设问题和答案都是经过分词处理的单词列表
- question = ['我', '喜欢', '看电影']
- answer1 = ['我', '喜欢', '打篮球']
- answer2 = ['我', '喜欢', '听音乐']
- # 将问题答案转换为向量
- question_vec = np.zeros((1, 3))
- answer1_vec = np.zeros((1, 3))
- answer2_vec = np.zeros((1, 3))
- # 假设使用词袋模型,将每个单词映射为一个整数向量
- # 这里使用随机生成的向量,实际应用中需要使用真实的词向量模型
- question_vec[0] = [1, 0, 0]
- answer1_vec[0] = [0, 1, 0]
- answer2_vec[0] = [0, 0, 1]
- # 计算问题与答案之间的余弦相似度
- similarity1 = cosine_similarity(question_vec, answer1_vec)
- similarity2 = cosine_similarity(question_vec, answer2_vec)
- print("问题与答案1的相似度:", similarity1[0][0])
- print("问题与答案2的相似度:", similarity2[0][0])
在这个例子中,我们首先将问题和答案转换为向量。这里我们使用了一个简单的词袋模型,将每个单词映射为一个整数向量。在实际应用中,您可能需要使用更复杂的词向量模型,如Word2Vec或GloVe。然后,我们使用余弦相似度计算问题与每个答案之间的相似度。最后,我们打印出相似度的值。

2.方案细节


3.持续改进
持续改进是确保问答机器人能够适应不断变化的环境和用户需求的关键。通过定期收集和分析用户反馈,我们可以了解机器人在哪些方面表现良好,哪些方面需要改进。同时,我们还需要密切关注市场趋势和新技术发展,以便将最新的技术和算法应用于我们的产品中。
为了实现持续改进,我们将采取以下措施:
- 建立用户反馈机制:我们将通过调查问卷、在线评价和社交媒体等渠道收集用户反馈,并定期分析这些反馈,以了解机器人的优点和不足之处。
- 定期更新知识库:我们将定期更新和维护机器人的知识库,以确保其能够涵盖最新的信息和趋势。同时,我们还将建立一个内容审核机制,以确保知识库中的信息准确可靠。
- 优化模型算法:我们将不断优化机器人的模型算法,以提高其性能和准确率。例如,我们可以使用更先进的自然语言处理技术和深度学习算法来提高机器人的理解和回答能力。
- 扩展功能和性能:我们将根据用户需求和市场趋势,不断扩展机器人的功能和性能。例如,我们可以增加语音识别和语音合成功能,以便用户可以通过语音与机器人进行交互。
- 保持与用户的沟通:我们将定期与用户进行沟通,了解他们的需求和期望,并向他们介绍机器人的新功能和改进。同时,我们还将建立一个用户社区,以便用户可以分享使用经验和提供建议。
持续改进是一个不断循环的过程,需要我们不断地收集反馈、优化模型、扩展功能、保持沟通,以保持机器人的准确性和实用性。
-
相关阅读:
持续性输出,继续推荐5款好用的软件
centos7停服之后换阿里云的源
Vue rules校验规则详解
在GitHub上学黑客 --- 黑客成长技术清单
RNA-seq——一、Linux软件安装
识别评估项目风险常用6大方法
深度学习——使用块的网络VGG(笔记)
秋初 WAMP 集成环境 v2.1
【老生谈算法】matlab实现低阶函数的二维图像获取——二维图像获取
CentOS 7 安装新版本的Nginx
- 原文地址:https://blog.csdn.net/2202_75469062/article/details/132437078
