-
卡尔曼家族从零解剖-(06) 一维卡尔曼滤波编程(c++)实践、透彻理解公式结果
讲解关于slam一系列文章汇总链接:史上最全slam从零开始,针对于本栏目讲解的 卡尔曼家族从零解剖 链接 :卡尔曼家族从零解剖-(00)目录最新无死角讲解:https://blog.csdn.net/weixin_43013761/article/details/133846882
文末正下方中心提供了本人 联系方式, 点击本人照片即可显示 W X → 官方认证 {\color{blue}{文末正下方中心}提供了本人 \color{red} 联系方式,\color{blue}点击本人照片即可显示WX→官方认证} 文末正下方中心提供了本人联系方式,点击本人照片即可显示WX→官方认证郑重声明:该系列博客为本人 ( W e n h a i Z h u ) 独家私有 , 禁止转载与抄袭 , 首次举报有谢 ! \color{red}郑重声明:该系列博客为本人(WenhaiZhu)独家私有,禁止转载与抄袭,首次举报有谢! 郑重声明:该系列博客为本人(WenhaiZhu)独家私有,禁止转载与抄袭,首次举报有谢!
一、前言
通过五个章节的分析,目前对于一维卡尔曼滤波有了一定层次的理解,这里先给出上篇博客推导出来的结论(卡尔曼五大公式):
①: x ˇ k = f x ^ k − 1 ②: σ X k − = f 2 σ X k − 1 + + σ Q k − 1 (01) \color{red} ①:\tag{01}\check x_{k}= f\hat x_{k-1}~~~~~~~~~~~~~~~②:\sigma^{-}_{X_{k}}=f^2\sigma_{X_{k-1}}^{+}+\sigma_{Q_{k-1}} ①:xˇk=fx^k−1 ②:σXk−=f2σXk−1++σQk−1(01) ③: k k = h σ X k − h 2 σ X k − + σ R k (02) \color{red} \tag{02}③:k_k=\frac{h \sigma_{X_k}^{-} }{h^{2} \sigma_{X_k}^{-} +\sigma_{R_k}} ③:kk=h2σXk−+σRkhσXk−(02) ④: x ^ k = k k ( y k − h x ˇ ) + x ˇ ⑤: σ X k + = ( 1 − h k k ) σ X k − (03) \color{red} \tag{03} ④:\hat x_{k}=k_k(y_k-h\check x)+\check x~~~~~~~~~~~~~~~~~~⑤:\sigma^+_{X_{k}}=(1-hk_k) \sigma_{X_k}^{-} ④:x^k=kk(yk−hxˇ)+xˇ ⑤:σXk+=(1−hkk)σXk−(03)
上面的五个式子很明显是递推的若假设已知 x ^ 0 \hat x_0 x^0、 σ X 0 + \sigma_{X_{0}}^+ σX0+、以及各个时刻观测 y k y_k yk,则可推导出出 x ^ k \hat x_k x^k、 σ X k + \sigma_{X_{k}}^+ σXk+,如下:
【 x ^ 0 , σ X 0 + , y 1 】 → 【 x ^ 1 , σ X 1 + , y 2 】 → ⋯ → 【 x ^ k , σ X k + 】 (04) \color{Green} \tag{04}【\hat x_0,\sigma_{X_{0}}^+,y_1】→【\hat x_1,\sigma_{X_{1}}^+,y_2】→\cdots→【\hat x_k,\sigma_{X_{k}}^+】 【x^0,σX0+,y1】→【x^1,σX1+,y2】→⋯→【x^k,σXk+】(04)该篇本博客主要是进行编程实践,为了公式与源码更好的对应起来,对上述公式公式进行改写,因为编程中通常需要进行模块下,所以代码中会实现一个函数,该函数只完成一次递推,故上5式符号简写为:
①: x m i n u s = f x p l u s ②: σ m i n u s = f 2 σ p l u s + q (05) \color{red} ①:\tag{05} x_ {minus}= f x_{plus}~~~~~~~~~~~~~~~②:\sigma_{minus}=f^2\sigma_{plus}+q ①:xminus=fxplus ②:σminus=f2σplus+q(05) ③: k = h σ m i n u s h 2 σ m i n u s + r (06) \color{red} \tag{06}③:k=\frac{h \sigma_{minus} }{h^{2} \sigma_{minus} +r} ③:k=h2σminus+rhσminus(06) ④: x p l u s = k ( y − h x m i n u s ) + x m i n u s ⑤: σ p l u s = ( 1 − h k ) σ m i n u s (07) \color{red} \tag{07} ④: x_{plus}=k(y-h x_{minus})+x_{minus}~~~~~~~~~~~~~~~~~~⑤:\sigma_{plus}=(1-hk) \sigma_{minus} ④:xplus=k(y−hxminus)+xminus ⑤:σplus=(1−hk)σminus(07)上式中的 r = σ R k r=\sigma_{R_k} r=σRk(预测过程标准差,主要影响收敛速度), q = σ R k q=\sigma_{R_k} q=σRk(观测过程标准差,理解为传感器精度,可以通过实验获得),这两个值都是固定值,迭代过程中通常不会改变。由于是编程,(05) 式中的 x m i n u s x_ {minus} xminus 最终会被 (07) 式中的 x p l u s x_{plus} xplus 覆盖,同理 σ p l u s \sigma_{plus} σplus 也会被覆盖。每次计算出来的 x p l u s x_{plus} xplus 与 σ p l u s \sigma_{plus} σplus 又会作为下一次的 x m i n u s x_{minus} xminus 与 σ m i n u s \sigma_{minus} σminus 进行输入。二、C++一维示例
这是一个c++的示例程序,其主要演示如何使用一维卡尔曼滤波对一个线性方程进行预测,该线性方程建模十分简单,即为 a x 2 ax^2 ax2 的形式,容易看出这是一个二次函数,对应代码如下:
float observe = a * std::pow(x, 2) + normal(mt); // 生成 ax*x + b 加上一个高斯噪声的观测值- 1
这里生成的是观测数据,另外一个重要的地方就是关于卡尔曼滤波初始化过程:
// 创建一个卡尔曼滤波,分别设置参数 f, h, q, r; 这些数值迭代过程中是不会改变的 KalmanFilter1D kalman_filter(1.0, 1.0, 1, 10); // 设置初始状态的均值与方差,后续迭代过程中会改变 float x_plus = 100, sigma_plus = 0.0;- 1
- 2
- 3
- 4
有兴趣的朋友可以调整一个参数,看下输出数据的变化,代码会把数据进行保存,通过 file_path 参数可以修改该保存路径,曲线图查看工具本人使用的是 plotjuggler,有兴趣的朋友可以自行百度以下使用方式,下面是整体代码(含注释):
/* * @Author: WenhaiZhu 944284742@qq.com * @Date: 2023-11-13 14:22:04 * @LastEditors: WenhaiZhu 944284742@qq.com * @LastEditTime: 2023-11-14 06:28:20 * @FilePath: /slam_in_autonomous_driving/src/kalman_filter/kalman_filter1_zwh.cc * @Description: 这是默认设置,请设置`customMade`, 打开koroFileHeader查看配置 进行设置: https://github.com/OBKoro1/koro1FileHeader/wiki/%E9%85%8D%E7%BD%AE */ #include#include #include #include #include #include class KalmanFilter1D { public: KalmanFilter1D(float f, float h, float q, float r) : f_(f), h_(h), q_(q), r_(r) {} ~KalmanFilter1D() {} void operator()(float x_plus, float sigma_plus, float observe) { float x_minus = f_ * x_plus + q_; // 求先验均值 float sigma_minus = std::pow(f_, 2) * sigma_plus + q_; // 求先验方差 k_ = (h_ * sigma_minus) / (std::pow(h_, 2) * sigma_minus + r_); // 求卡尔曼增益系数 x_plus_ = x_minus + k_ * (observe - h_ * x_minus); // 对先验均值更新,得到后验均值 sigma_plus_ = (1 - h_ * k_) * sigma_minus; // 对先验更新,获得后验方标准差 } float GetXMinus() { return x_plus_; } float GetSigmaMinus() { return sigma_plus_; } float Get_k() {} private: float f_; float h_; float q_; float r_; float k_ = 0; float x_plus_ = 0; float sigma_plus_ = 0; }; int main(int argc, char* argv[]) { // 预备工作,可以忽略 google::InitGoogleLogging(argv[0]); FLAGS_stderrthreshold = google::INFO; FLAGS_colorlogtostderr = true; google::ParseCommandLineFlags(&argc, &argv, true); // 创建一个卡尔曼滤波,分别设置参数 f, h, q, r; 这些数值迭代过程中是不会改变的 // q越大收敛速度越快,r越大越倾向于预测结果, r越小越倾向于观测结果 KalmanFilter1D kalman_filter(1.0, 1.0, 1, 10); // 设置初始状态的均值与方差,后续迭代过程中会改变 float x_plus = 100, sigma_plus = 0.0; // 创建文件,用于保存数据,方便可视化 std::string file_path = "./samples_zwh.csv"; std::ofstream fd(file_path); if (!fd.is_open()) { LOG(ERROR) << "Unable to open file: " << file_path; } fd << "t," << "x_plus," << "observe," << std::endl; std::mt19937 mt(0); // 随机种子 std::normal_distribution<> normal(0.0, 20.0); // 用于随机生成符合高斯分布的数据 float a = 0.1, b = 0.2; // 真实模型为 ax*x + b float x = 0.0, dt = 0.1; // x标识x轴数值,后面会刷新,dt标识采样间隔 for (int i = 0; i < 1000; ++i) { float observe = a * std::pow(x, 2) + normal(mt); // 生成 ax*x + b 加上一个高斯噪声的观测值 kalman_filter(x_plus, sigma_plus, observe); // 进行卡尔曼滤波,observe 等于观测方程中的 y x_plus = kalman_filter.GetXMinus(); // 获取滤波之后的均值 sigma_plus = kalman_filter.GetSigmaMinus(); // 获取滤波之后的标准差 x += dt; // 采样更新 fd << x << "," << x_plus << "," << observe << "," << std::endl; // 保存数据用于可视化 } fd.close(); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
下面曲线是本人通过 plotjuggler 绘画结果,红色为 observe(y),绿色为为 x_plus,可以很明显看出 x_plus 的抖动小了很多,这就是滤波的效果。下图中,并没有把真值刻画出来,因为实际在应用的时候,也是没有办法知道真值的,如果是兴趣的朋友,可以简单修改一下源码把代码中 a * std::pow(x, 2) 结果保存下来即可。

三、透彻理解公式
1.先验分析
本博客的最开始,已经把公式给出,在前面文章中虽然大致给出了推导过程,但是并没有深入的探讨过这个公式,先来说一下 (05) 式,如下:
①: x m i n u s = f x p l u s ②: σ m i n u s = f 2 σ p l u s + q (08) \color{Green} ①:\tag{08} x_ {minus}= f x_{plus}~~~~~~~~~~~~~~~②:\sigma_{minus}=f^2\sigma_{plus}+q ①:xminus=fxplus ②:σminus=f2σplus+q(08)上式中的 q q q 表示符合噪声高斯噪声 N ( 0 , q ) N(0,q) N(0,q) 的标准差,可以看出,每次迭代,预测状态 x m i n u s x_ {minus} xminus 对应的标准差 σ m i n u s \sigma_{minus} σminus 都会在原来的基础( σ p l u s \sigma_{plus} σplus)上叠加一个 q q q,假如没后续没有观测方程对齐进行修正,可想而知, σ m i n u s \sigma_{minus} σminus 会约来越打,即 x m i n u s x_{minus} xminus 的可信度越来越低,其是没有办法当作一个可信的结果输出的。另外,为了方便讲解,对 状态方程 x p l u s = f ( x m i n u s ) x_{plus} = f(x_ {minus}) xplus=f(xminus) 进行了简化,直接变成了 x p l u s = f ∗ x m i n u s x_{plus} = f*x_ {minus} xplus=f∗xminus 形式,其实这里的 f ( x ) f(x) f(x) 是一个广义的概念,并不局限于 x x x 一个参数, 回忆一下前面的博客 卡尔曼家族从零解剖-(03)贝叶斯滤波→公式推导与示例 中 (5) 式 : x k = f ( x k − 1 , v k − 1 ) + q k x_{k}=f(x_{k-1},v_{k-1})+q_k xk=f(xk−1,vk−1)+qk,可以知道其接收两个参数,其实不止,只要保证 f ( x ) f(x) f(x) 是线性的,完全可以接收更多的参数。如书写成 x k = f ( x k − 1 , v k − 1 , u k − 1 , t k − 1 , ) + q k x_{k}=f(x_{k-1},v_{k-1},u_{k-1},t_{k-1},)+q_k xk=f(xk−1,vk−1,uk−1,tk−1,)+qk 等。值得 注意 : \color{red} 注意: 注意: 只有 x x x 才是由卡尔曼递推的,其他的只能类似于 y y y 通过观测或者测量或者。且 f ( x k − 1 , v k − 1 , u k − 1 , t k − 1 , ) + q k f(x_{k-1},v_{k-1},u_{k-1},t_{k-1},)+q_k f(xk−1,vk−1,uk−1,tk−1,)+qk 的结果只能为状态 x x x 而不是 v v v、 u u u 等。
2.卡尔曼增益
卡尔曼增益就是上面的 (06),英文通常称为 Kalman Gain,如下:
③: k = h σ m i n u s h 2 σ m i n u s + r (09) \color{Green} \tag{09}③:k=\frac{h \sigma_{minus} }{h^{2} \sigma_{minus} +r} ③:k=h2σminus+rhσminus(09) 其就是一个比值,由于 h h h 是一个常数,所以下面的讨论忽略他,单独来分析 σ m i n u s \sigma_{minus} σminus 与 r r r,前者是预测出来的标准差,值越小则表示预测的状态 x m i n u s x_{minus} xminus 可信度越高,这里假设他无穷小,也就是说预测出来的结果无线接近真实值,根据上式,其结果 k k k 就无限趋近于 0。再反过来,如果 x m i n u s x_{minus} xminus 无限趋向于无穷大,易知结果 k k k 趋向于 1(前面提到不考虑 h h h)。那么总结起来, k k k 越大,表示预测结果 x m i n u s x_{minus} xminus 越不可信, k k k 越小表示预测结果 x m i n u s x_{minus} xminus 越可信。下面就是看如何把这个 k k k 用起来。
3.状态更新
其实观测方程也是一个广义的概念,其并不局限于一个观测值 y y y,也就是说在 k k k 时刻状态 x k x_k xk 下,你可以观测到 y k 1 、 y k 2 、 y k 3 、 ⋯ 、 y k j y_{k1}、y_{k2}、y_{k3}、\cdots、y_{kj} yk1、yk2、yk3、⋯、ykj。这里举一个例子,算法估算出温度是 35 35 35(先验),但是你可以用 j j j 个体温计进行测量,获得 j j j 个观测值,也就是说观测方程可以书写成 ( y k 1 , y k 1 , ⋯ , y k j ) = f ( x k ) (y_{k1},y_{k1},\cdots, y_{kj})=f(x_k) (yk1,yk1,⋯,ykj)=f(xk),使用逆函数变换一下就成了 x k = f − 1 ( k 1 , y k 1 , ⋯ , y k j ) x_k=f^{-1}(_{k1},y_{k1},\cdots, y_{kj}) xk=f−1(k1,yk1,⋯,ykj),这里看起来可能更加合理一点,后续讲解矩阵形式的卡尔曼滤波,或许会为大家示例一下,这里就暂且略过了,回到 (07) 式: ④: x p l u s = k ( y − h x m i n u s ) + x m i n u s ⑤: σ p l u s = ( 1 − h k ) σ m i n u s (10) \color{Green} \tag{10} ④: x_{plus}=k(y-h x_{minus})+x_{minus}~~~~~~~~~~~~~~~~~~⑤:\sigma_{plus}=(1-hk) \sigma_{minus} ④:xplus=k(y−hxminus)+xminus ⑤:σplus=(1−hk)σminus(10)
根据前面的结论, k k k 越大,表示预测结果 x m i n u s x_{minus} xminus 越不可信, k k k 越小表示预测 结果 x m i n u s x_{minus} xminus 越可信。来看看是不是这么一回事,首先看 ④, y − h x m i n u s y-hx_{minus} y−hxminus 表示观测误差,如果观测误差比较大,那么说明观测结果不可信,应该相信预测结果,即前面因子 k k k 应该越小越好。与前面【卡尔曼增益】的逻辑吻合。
再来看⑤,如果 σ m i n u s \sigma_{minus} σminus 较大,说明预测结果不可信,那么因子 1 − h k 1-hk 1−hk 的结果越小越好,即 k k k 越大越好。与前面【卡尔曼增益】的逻辑吻合。
4.思维拓展
思考 : \color{red} 思考: 思考: 不知道有没有细心的朋友发现到示例程序中,每次递推都对应一个观测。其实呢,在实际应用过程中,通常不会这样的。好比如温度的测量,通常间隔 1 个小时,或者 3 个小时测量一次都是可以的,没有必要时时刻刻进行观测,这样太浪费资源了。
除了浪费资源,有的时候可能因为条件的限制,没有办法进行观测,就拿 GPS 来说,有的时候信号不好可能就收不到数据,或者受到无效数据,这个时候都类似于没有观测。但是,即使没有观测,卡尔曼滤波也是可以进行递推的,只进行 (08) 式的操作,放弃 (09) (10) 式。
这样很显然会存在一个缺点,那就是每次递推都会叠加一个 q q q 的噪声,所以长时间没有观测,随着累计误差(噪声)的增加,算法就失效了,所以,间隔时间不能太长了。
那么问题又来了,多长时间算长,多短时间算短呢?实际上没有很固定的答案,其主要与你的观测有关,如果你的观测很准确,那么不观测的时间就可以相对延长,等到一次观测,则可以把跑偏的算法拉回正轨。如果你的观测本省就不太精准,那么就不能间隔时间太长不进行观测,容易跑飞。
有兴趣的朋友可以简单修改一下代码,看看调整一下观测频率,再对比一下曲线图,
5.深度解剖
重点 : \color{red} 重点: 重点: 卡尔曼滤波递推公式虽然是线性的,但是这并不意味着其只能应用于线性变换的场景。来看 (5) 式 ①: x m i n u s = f x p l u s ②: σ m i n u s = f 2 σ p l u s + q (11) \color{red} ①:\tag{11} x_ {minus}= f x_{plus}~~~~~~~~~~~~~~~②:\sigma_{minus}=f^2\sigma_{plus}+q ①:xminus=fxplus ②:σminus=f2σplus+q(11) 其线性,表示的是 x m i n u s x_ {minus} xminus 与 x p l u s x_{plus} xplus 之间的为线性变换,并不是说再整个时间轴(举例),状态 x x x 需要呈现为线性变换。那上面例子来说,其是一个二次函数,但是卡尔曼滤波预测效果还是挺好的。
其实卡尔曼滤波,只要你观测足够密集,基本可以预测任意复杂的曲线,两点之间无线接近,可以当作直线来对待。但是如果两时刻状态发生的变换剧烈了,其预测效果与 q q q 的关系比较大,因为变换太剧烈了,使用通用的直线去进行拟合(如预先设定的 ax),是十分困难的,这个时候就需要依靠噪声 q q q 去弥补,因为根据前面的推导,如果 q q q 比较大,则预测结果 x ^ k \hat x_{k} x^k 才允许距离 x ^ k − 1 \hat x_{k-1} x^k−1 较远,从而实现剧烈变化的吻合。
这里就可以看出卡尔曼一个明显的弊端,其不适合预测高次函数,因为存在两点之间的特别剧烈变化的情况,除非把 q q q 设置为无穷大,不过这样就没有意义了,等价于直接选择观测值了。
6.上帝视角
其实个人查阅过很多博客或教学视频,可能就是看多了反而更加杂乱,到最后发现自己连离散与连续都云里雾里了,明明前面理解的是离散,突然视角一转,又变变成连续了。这里主要的原因是大部分博客,或者 u p up up 没有从一个出血者的角度去考虑,先回顾一下 卡尔曼家族从零解剖-(03) 贝叶斯滤波→公式推导与示例 这篇博客中,的如下图像:
 先从宏观的角度来看,对
k
0
k_0
k0、
k
1
k_1
k1、
⋯
\cdots
⋯、
k
k
k_k
kk 时刻的预测与观测,不用多说把,肯定是离散的,对吧。所以对于贝叶斯滤波经常可以看到公式
P
(
X
∣
Y
k
)
=
P
(
Y
k
∣
X
)
P
(
X
)
P
(
Y
k
)
=
η
P
(
Y
k
∣
X
)
P
(
X
)
(12)
\color{Green} \tag{12} P\left(X \mid Y_k \right)=\frac{P\left(Y_k \mid X\right) P\left(X\right)}{P(Y_k)}=\eta P\left(Y_k \mid X\right) P\left(X\right)
P(X∣Yk)=P(Yk)P(Yk∣X)P(X)=ηP(Yk∣X)P(X)(12)不用质疑,这肯定是正确的,因为这就是离散的贝叶斯公式。
坑点
:
\color{red} 坑点:
坑点: 离散概率分布可以通过概率密度积分获得,这个时候容易进入的一个误区是,以为对状态轴
x
x
x 进行积分就可以了如下:
先从宏观的角度来看,对
k
0
k_0
k0、
k
1
k_1
k1、
⋯
\cdots
⋯、
k
k
k_k
kk 时刻的预测与观测,不用多说把,肯定是离散的,对吧。所以对于贝叶斯滤波经常可以看到公式
P
(
X
∣
Y
k
)
=
P
(
Y
k
∣
X
)
P
(
X
)
P
(
Y
k
)
=
η
P
(
Y
k
∣
X
)
P
(
X
)
(12)
\color{Green} \tag{12} P\left(X \mid Y_k \right)=\frac{P\left(Y_k \mid X\right) P\left(X\right)}{P(Y_k)}=\eta P\left(Y_k \mid X\right) P\left(X\right)
P(X∣Yk)=P(Yk)P(Yk∣X)P(X)=ηP(Yk∣X)P(X)(12)不用质疑,这肯定是正确的,因为这就是离散的贝叶斯公式。
坑点
:
\color{red} 坑点:
坑点: 离散概率分布可以通过概率密度积分获得,这个时候容易进入的一个误区是,以为对状态轴
x
x
x 进行积分就可以了如下:
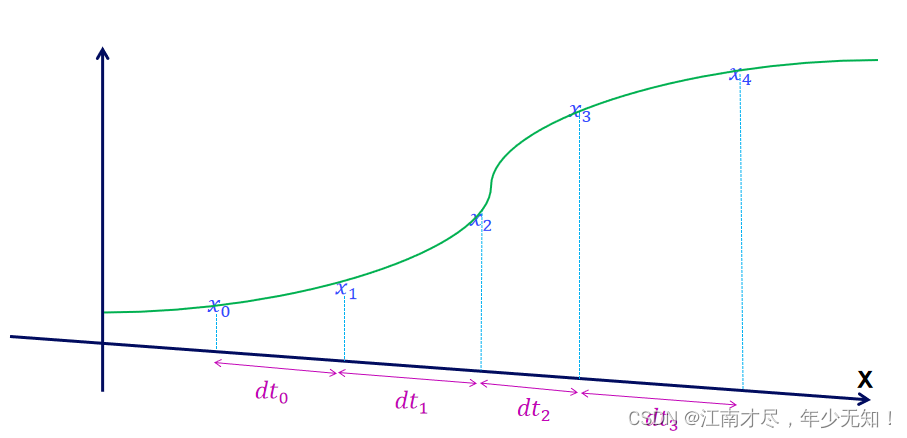
假设状态分随机变量 X X X 符合高斯分布,那么也就是如下所示( d t dt dt移动了一下):
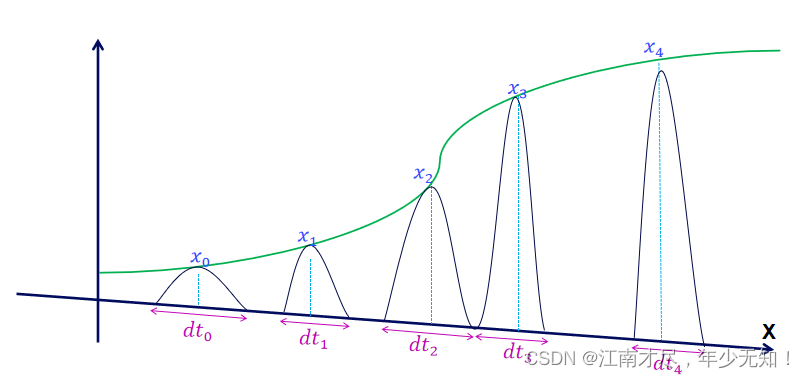
每个状态 x k x_k xk 都符合高斯分布,那么对高斯分布进行 d t \mathrm{d} t dt f范围的积分不久可以了吗?但是这样积分是不行的,因为你积分出来有什么意义?既然是高斯分布,那么他的期望不就是他的均值吗?,结果不依旧是 x 0 x_0 x0 到 x k x_k xk 吗?为什么,因为你本质上只使用到了递推公式 f ( x ) f(x) f(x),少了观测的参与,下面的图示,更加符合实际:
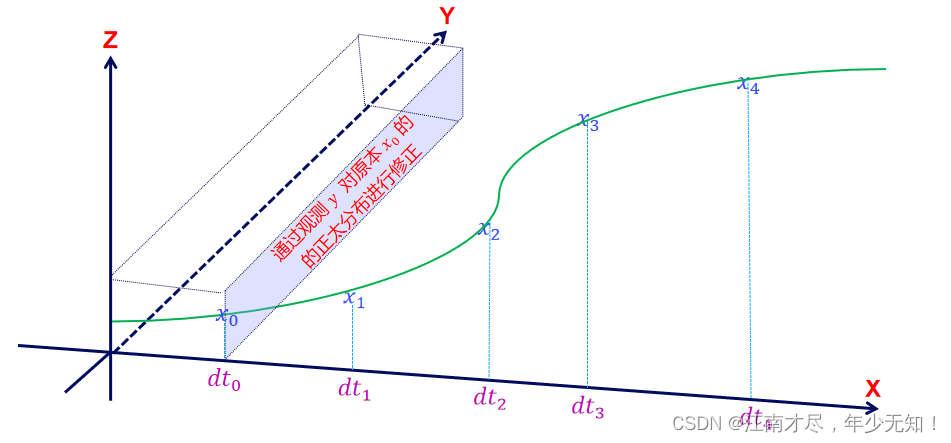
因为观测 y y y 的存在,每个状态分布都会进行调整,调整之后再进行积分。为了简单方便积分,所以即使通过观测 y y y 调整之后得分布依旧为高斯分布。 Y Y Y 轴观测对状态的修正结果通常类似于下图(两个高斯函数的乘积):

其中红色部分就是修正之后的结果,可以看出其是介于预测状态与观测状态两者之间的,后续会详细推导这个过程。也就是是说,对于卡尔曼滤波来说,直观看到状态轴(图示x),其应该是离散的,所以使用离散的方式进行建模,如 x k = f x k − 1 x_k=fx_{k-1} xk=fxk−1,由这个时刻的状态递推到下个时刻(因为通常来说, k k k 不是连续的)。但是再处理每个时刻观测的时候,通常是需要连续建模的,如高斯概率密度函数就是连续,上图就是一个示例。
总结 : \color{red} 总结: 总结: 通常来说,实际应用的卡尔曼滤波(或贝叶斯等),从状态轴 x x x 来看,通常都是离散的。但是对于每个状态处理时,若有观测 y y y 参与,则通常会涉及到连续处理。 仅供参考,结论: \color{red} 仅供参考,结论: 仅供参考,结论: 卡尔曼滤波即包含了离散,也融入了连续。这就是我的个人体会。所以,那些博客或者视频教材等,说是连续或离散都是正确的,或者说,都是错误的。
四、总结
到目前为止,对于卡尔曼滤波的了解应该是比较深入了,虽然仅仅局限于一维。且前面还有太多的疑惑没有具体分析,如:
①高斯分布分布负无穷到正无穷的积分为什么是1?
② 高斯分布经过线性变换为什么还是高斯分布?
③ 两个高斯分布函数的乘积为什么依旧是高斯分布?
④ 多维(多元)卡尔曼滤波应该如何推导与编程?
…如果再加上后面还要分析扩展卡尔曼滤波(EKF)、误差状态卡尔曼滤波 (ESKF)、粒子滤波、迭代卡尔曼滤波等。任务量,确实比较庞大,不过没有关系,踏踏实实走好每一步,总会到终点的。
-
相关阅读:
04.9. 环境和分布偏移
python getopt模块的使用
“音响”事件对国产豪华品牌车汽车厂商的警示
ES delete_by_query条件删除的几种方式
自动驾驶技术解析与关键步骤
golang数据库连接池参数设置
ClickHouse技术研究及语法简介
利用Python进行数据分析系列之:数组和矢量计算
OS2.1.4:进程通信
C# —— 方法的参数列表
- 原文地址:https://blog.csdn.net/weixin_43013761/article/details/134353022