-
深度解析NLP定义、应用与PyTorch实战
1. 概述
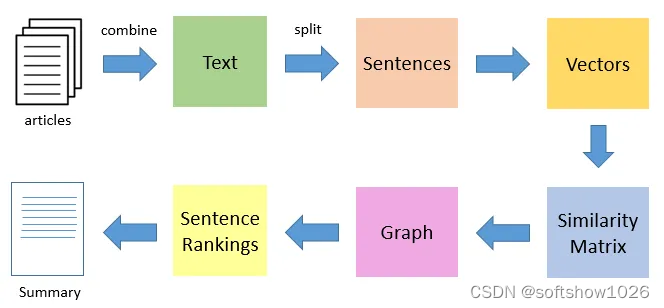
文本摘要是自然语言处理(NLP)的一个重要分支,其核心目的是提取文本中的关键信息,生成简短、凝练的内容摘要。这不仅有助于用户快速获取信息,还能有效地组织和归纳大量的文本数据。
1.1 什么是文本摘要?
文本摘要的目标是从一个或多个文本源中提取主要思想,创建一个短小、连贯且与原文保持一致性的描述性文本。
例子: 假设有一篇新闻文章,描述了一个国家领导人的访问活动,包括他的行程、会面的外国领导人和他们讨论的议题。文本摘要的任务可能是生成一段如下的摘要:“国家领导人A于日期B访问了国家C,并与领导人D讨论了E议题。”
1.2 为什么需要文本摘要?
随着信息量的爆炸性增长,人们需要处理的文本数据量也在快速增加。文本摘要为用户提供了一个高效的方法,可以快速获取文章、报告或文档的核心内容,无需阅读整个文档。
例子: 在学术研究中,研究者们可能需要查阅数十篇或数百篇的文献来撰写文献综述。如果每篇文献都有一个高质量的文本摘要,研究者们可以迅速了解每篇文献的主要内容和贡献,从而更加高效地完成文献综述的撰写。
文本摘要的应用场景非常广泛,包括但不限于新闻摘要、学术文献摘要、商业报告摘要和医学病历摘要等。通过自动化的文本摘要技术,不仅可以提高信息获取的效率,还可以在多种应用中带来巨大的商业价值和社会效益。
2. 发展历程
文本摘要的历史可以追溯到计算机科学和人工智能的早期阶段。从最初的基于规则的方法,到现今的深度学习技术,文本摘要领域的研究和应用都取得了长足的进步。
2.1 早期技术
在计算机科学早期,文本摘要主要依赖基于规则和启发式的方法。这些方法主要根据特定的关键词、短语或文本的句法结构来提取关键信息。
例子: 假设在一个新闻报道中,频繁出现的词如“总统”、“访问”和“协议”可能会被认为是文本的关键内容。因此,基于这些关键词,系统可能会从文本中选择包含这些词的句子作为摘要的内容。
2.2 统计方法的崛起
随着统计学方法在自然语言处理中的应用,文本摘要也开始利用TF-IDF、主题模型等技术来自动生成摘要。这些方法在某种程度上改善了摘要的质量,使其更加接近人类的思考方式。
例子: 通过TF-IDF权重,可以识别出文本中的重要词汇,然后根据这些词汇的权重选择句子。例如,在一篇关于环境保护的文章中,“气候变化”和“可再生能源”可能具有较高的TF-IDF权重,因此包含这些词汇的句子可能会被选为摘要的一部分。
2.3 深度学习的应用
近年来,随着深度学习技术的发展,尤其是循环神经网络(RNN)和变压器(Transformers)的引入,文本摘要领域得到了革命性的提升。这些技术能够捕捉文本中的深层次语义关系,生成更为流畅和准确的摘要。
例子: 使用BERT或GPT等变压器模型进行文本摘要,模型不仅仅是根据关键词进行选择,而是可以理解文本的整体含义,并生成与原文内容一致但更为简洁的摘要。
2.4 文本摘要的演变趋势
文本摘要的方法和技术持续在进化。目前,研究的焦点包括多模态摘要、交互式摘要以及对抗生成网络在摘要生成中的应用等。
例子: 在一个多模态摘要任务中,系统可能需要根据给定的文本和图片生成一个摘要。例如,对于一个报道某项体育赛事的文章,系统不仅需要提取文本中的关键信息,还需要从与文章相关的图片中提取重要内容,将二者结合生成摘要。
Python实现
import re
from collections import defaultdict
from nltk.tokenize import word_tokenize, sent_tokenizedef extractive_summary(text, num_sentences=2):
# 1. Tokenize the text
words = word_tokenize(text.lower())
sentences = sent_tokenize(text)
# 2. Compute word frequencies
frequency = defaultdict(int)
for word in words:
if word.isalpha(): # ignore non-alphabetic tokens
frequency[word] += 1
# 3. Rank sentences
ranked_sentences = sorted(sentences, key=lambda x: sum([frequency[word] for word in word_tokenize(x.lower())]), reverse=True)
# 4. Get the top sentences
return ' '.join(ranked_sentences[:num_sentences])# Test
text = "北京是中国的首都。它有着悠久的历史和丰富的文化遗产。故宫、长城和天安门都是著名的旅游景点。"
print(extractive_summary(text))
-
相关阅读:
深入剖析:正则表达式的奥秘
五款可替代163邮箱的电子邮件服务
WPF --- 非Button自定义控件实现点击功能
OPLSAA力场参数之快速建模—MS+Moltemplate
ThingsBoard IoT Gateway MQTT 连接器配置 第二部分
1465. 切割后面积最大的蛋糕
[python 刷题] 143 Reorder List
基于LSTM+FCN处理多变量时间序列问题记录(二)
Springboot、Tomcat+skywalking 链路追踪、日志收集配置
STL—string
- 原文地址:https://blog.csdn.net/softshow1026/article/details/134360342