-
LeetCode146.LRU缓存
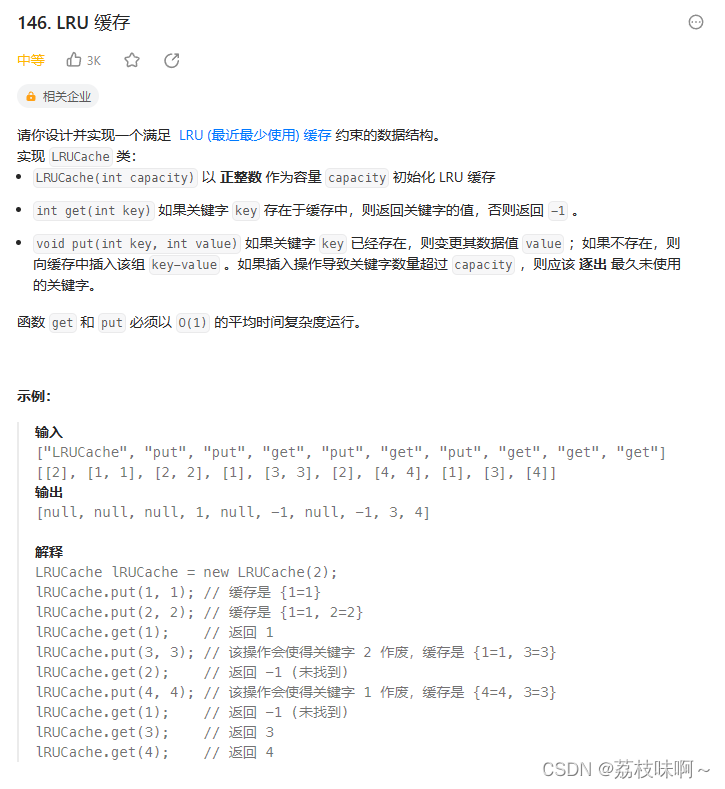
写了一个小时,终于把示例跑过了,没想到啊提交之后第19/22个测试用例没过

我把测试用例的输出复制在word上看看和我的有什么不同,没想到有18页的word,然后我一直检查终于找出了问题,而且这个bug真的太活该了,感觉只有傻屌才能写出这种bug,以下是我之前的代码:
- class LRUCache {
- HashMap
- int cap;
- int useIndex;
- HashMap
- public LRUCache(int capacity) {
- map = new HashMap
- lastUseMap = new HashMap
- cap = capacity;
- useIndex =0;
- }
- public int get(int key) {
- if(map.containsKey(key)){
- lastUseMap.put(key,useIndex);
- useIndex++;
- return map.get(key);
- }else{
- return -1;
- }
- }
- public void put(int key, int value) {
- if(!map.containsKey(key)){
- if(map.size() == cap){
- int min = 10000;
- int delKey = -1;
- Set
- for (Map.Entry
- if(entry.getValue() < min){
- min = entry.getValue();
- delKey = entry.getKey();
- }
- }
- map.remove(delKey);
- lastUseMap.remove(delKey);
- }
- }
- map.put(key,value);
- lastUseMap.put(key,useIndex);
- useIndex++;
- }
- }
我想讲我的算法思想,最后再讲里面的那个bug。
我的想法是,用hashmap来进行put和get操作,这样就不用自己写真正put和get的代码了(其实一开始看到题目写put和get算法复杂度是O1我用的是数组,写了很久没写出来,直接换成了hashmap,因为一开始我以为hashmap的算法复杂度大于1,但其实不是的,因为hashmap是数组--->数组+链表 ---->数组+红黑树,最简单的情况是用hash函数直接算出数组下标,算法复杂度是O1,如果数组的这个位置上是个链表,那么还要用O(n)遍历链表,如数组的这个位置上是个红黑树,那么还要用O(nlogn)遍历红黑树,但大多数情况还是O(1))
那么put和get操作解决了,只需要解决过期淘汰就可以了,我是用一个
HashMap进行正真的putget缓存操作,然后用一个
int useIndex;来记录每次get和put操作的序号(从0开始,每次自增,如果get失败就不自增),然后再用一个map
HashMap来记录map中的每个元素的最新一次的操作序号。
构造函数就不用说了,把这几个属性初始化以下就行。
先讲get方法,如果map中没有这个key返回-1,如果有这个key,把lastUseMap中的这个key的value更新为本次操作的序号,再把序号加一,再把map中这个key的value返回。
再讲讲put方法,先对size进行判断,如果达到最大容量cap那么就要删除掉map中的一个最久未使用的元素,要找出最久未使用的元素只需要对lastUseMapz进行一次遍历即可,这个就属于基操了,先定义个较大数min,然后把遍历出来的value和min进行比较,如果小于min就把min更新为这个value,找到了这个最久没用的元素后再map和lastUseMap中把这个元素删除就可以了,然后是进行put操作,除了把key和value put进map以外还要记得把key和当前操作序号put进lastUseMap,然后操作序号自增。
需要注意的一点是,在尽心put操作之前先看看map里面有没有这个key,如果有直接put就行不用删除,这是个坑,有个测试用例就是这个。
最后讲讲那个傻逼bug,就是min的初值,我当时也没想到操作次数会达到18页word啊,就直接给了10000,所以在第19个测试用例报错了,只要把min的初值赋为Integer.MAX_VALUE就可以了。
再看看官方题解吧:
题解用的是hsahMap+双向链表的做法,并且它并没有用封装好的LinkedList,而是自己写一个简介的链表,以下是题解代码:
- public class LRUCache {
- class DLinkedNode {
- int key;
- int value;
- DLinkedNode prev;
- DLinkedNode next;
- public DLinkedNode() {}
- public DLinkedNode(int _key, int _value) {key = _key; value = _value;}
- }
- private Map
- private int size;
- private int capacity;
- private DLinkedNode head, tail;
- public LRUCache(int capacity) {
- this.size = 0;
- this.capacity = capacity;
- // 使用伪头部和伪尾部节点
- head = new DLinkedNode();
- tail = new DLinkedNode();
- head.next = tail;
- tail.prev = head;
- }
- public int get(int key) {
- DLinkedNode node = cache.get(key);
- if (node == null) {
- return -1;
- }
- // 如果 key 存在,先通过哈希表定位,再移到头部
- moveToHead(node);
- return node.value;
- }
- public void put(int key, int value) {
- DLinkedNode node = cache.get(key);
- if (node == null) {
- // 如果 key 不存在,创建一个新的节点
- DLinkedNode newNode = new DLinkedNode(key, value);
- // 添加进哈希表
- cache.put(key, newNode);
- // 添加至双向链表的头部
- addToHead(newNode);
- ++size;
- if (size > capacity) {
- // 如果超出容量,删除双向链表的尾部节点
- DLinkedNode tail = removeTail();
- // 删除哈希表中对应的项
- cache.remove(tail.key);
- --size;
- }
- }
- else {
- // 如果 key 存在,先通过哈希表定位,再修改 value,并移到头部
- node.value = value;
- moveToHead(node);
- }
- }
- private void addToHead(DLinkedNode node) {
- node.prev = head;
- node.next = head.next;
- head.next.prev = node;
- head.next = node;
- }
- private void removeNode(DLinkedNode node) {
- node.prev.next = node.next;
- node.next.prev = node.prev;
- }
- private void moveToHead(DLinkedNode node) {
- removeNode(node);
- addToHead(node);
- }
- private DLinkedNode removeTail() {
- DLinkedNode res = tail.prev;
- removeNode(res);
- return res;
- }
- }
hashMap的key是key,value是链表的节点。链表中越头部的节点是越新的节点,越再尾部的节点是越久未使用的节点。
get方法只需要通过key拿到node节点,如果为null直接返回-1,否则返回node.val,并且需要把这个node移到链表的最前面。
put方法也是通过key拿到node节点,如果node不存在就创建一个node,然后把key和这个node放进hashMap,把这个node放到链表的头部,然后size++,如果这个时候size>最大容量了那么就把尾部节点删除,并且再map中删除这个key,size--;如果node存在直接把node的value改成参数value然后把node移到链表头部,剩下的方法都是关于双向链表的操作了。
-
相关阅读:
Prometheus 简介
计算机毕业设计Java教工公寓管理(源码+系统+mysql数据库+lw文档)
【Linux】文件重定向以及一切皆文件
2023年网络安全市场五大增长热点
腾讯云Linux轻量应用服务器一键部署WordPress个人博客教程
python 绘制3D图
Linux进程间通信——共享内存
坚持了 10 年的 9 个编程好习惯
UVA 10375 选择与除法 Choose and divide
电脑不小心格式化了,怎么恢复?
- 原文地址:https://blog.csdn.net/qq_61009660/article/details/134352612
