-
混淆矩阵和相应参数详解
如果一个模型在能够尽量捕获少数类的情况下,还能够尽量对多数类判断正确,则这个模型就非常优秀了。为了评估这样的能力,我们将引入新的模型评估指标:混淆矩阵和ROC曲线。
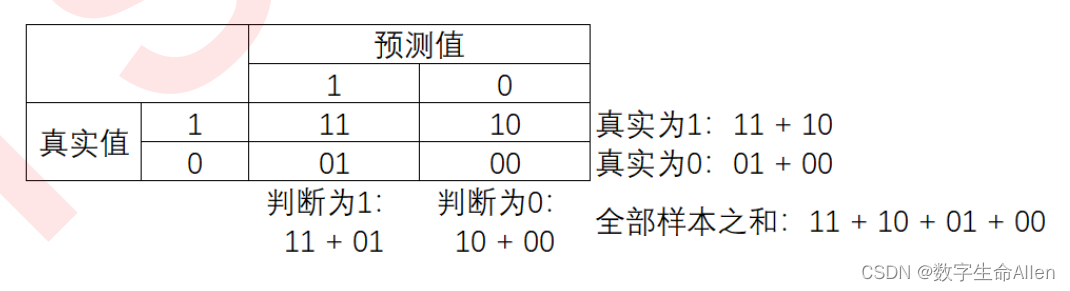
上面是混淆矩阵。接下来我们结合图像解释一下准确率,精确率,召回率和假正率
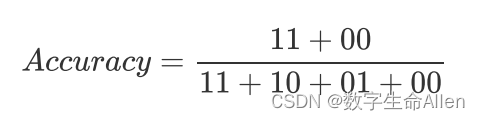
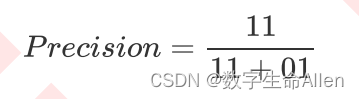
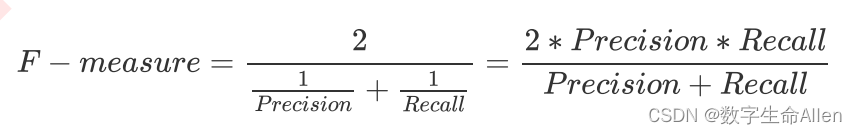

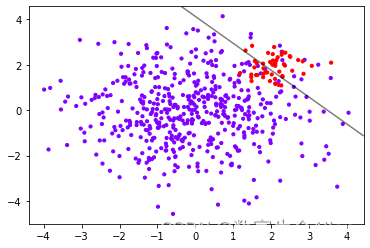
准确率可以理解为:分类正确的点(决策超平面上方的红色点+决策超平面下方的紫色点)/全部样本点
精确率可以理解为:决策超平面上方的红色点/决策超平面上方的全部样本点
召回率可以理解为:决策超平面上方的红色点/全部红色样本点。衡量模型捕捉少数类的能力
特异度可以理解为:决策超平面下方的紫色点/全部紫色样本点。衡量模型将多数类判别正确的能力
假正率可以理解为:决策超平面上方的紫色点/全部紫色样本点。衡量模型将多数类判别错误的能力
F1 measure:是精确率和召回率的平衡指标
ROC曲线是一条以不同阈值下的假正率FPR为横坐 标,不同阈值下的召回率Recall为纵坐标的曲线。
我们在追求较高的Recall的时候,Precision会下降,就是说随着更多的少数 类被捕捉出来,会有更多的多数类被判断错误,但我们很好奇,随着Recall的逐渐增加,模型将多数类判断错误的 能力如何变化呢?我们希望理解,我每判断正确一个少数类,就有多少个多数类会被判断错误。假正率正好可以帮 助我们衡量这个能力的变化。相对的,Precision无法判断这些判断错误的多数类在全部多数类中究竟占多大的比 例,所以无法在提升Recall的过程中也顾及到模型整体Accuracy。因此,我们可以使用Recall和FPR之间的平 衡,来替代Recall和Precision之间的平衡,让我们衡量模型在尽量捕捉少数类的时候,误伤多数类的情况如何变化,这就是我们的ROC曲线衡量的平衡。
接下来我们用代码来实现上述过程:
首先导入相应的库:
- import numpy as np
- import matplotlib.pyplot as plt
- from matplotlib.colors import ListedColormap
- from sklearn import svm
- from sklearn.datasets import make_blobs
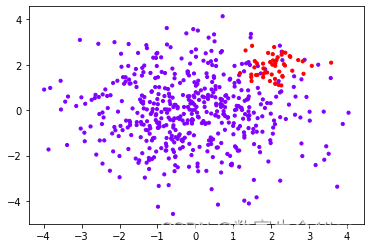
再来绘制散点图:
- class_1 = 500 #类别1有500个样本
- class_2 = 50 #类别2只有50个
- centers = [[0.0, 0.0], [2.0, 2.0]] #设定两个类别的中心
- clusters_std = [1.5, 0.5] #设定两个类别的方差,通常来说,样本量比较大的类别会更加松散
- X, y = make_blobs(n_samples=[class_1, class_2],
- centers=centers,
- cluster_std=clusters_std,
- random_state=0, shuffle=False)
- plt.scatter(X[:, 0], X[:, 1], c=y, cmap="rainbow",s=10)
再来绘制决策超平面:
导入混淆矩阵:
from sklearn.metrics import confusion_matrix as CM, precision_score as P, recall_score as RCM中第一个参数传入真实值,第二个参数传入预测值:
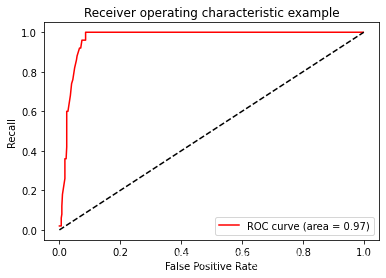
CM(prob.loc[:,"y_true"],prob.loc[:,"pred"],labels=[1,0])接下来我们绘制ROC曲线:
先导入相应的模块:
from sklearn.metrics import roc_curve计算假正率,召回率和阈值:
FPR, recall, thresholds = roc_curve(y,clf_proba.decision_function(X), pos_label=1) #计算真正率和假正率 #pos_label=1意思是把1当做正例导入AUC:
from sklearn.metrics import roc_auc_score as AUC画图:
- plt.figure()
- plt.plot(FPR, recall, color='red',
- label='ROC curve (area = %0.2f)' % area)
- plt.plot([0, 1], [0, 1], color='black',linestyle='--')
- plt.xlim([-0.05, 1.05])
- plt.ylim([-0.05, 1.05])
- plt.xlabel('False Positive Rate')
- plt.ylabel('Recall')
- plt.title('Receiver operating characteristic example')
- plt.legend(loc="lower right")
- plt.show()
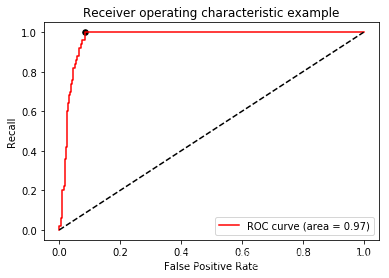
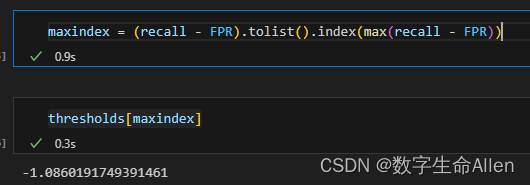
接下来我们通过recall和FPR差异最大的点对应的阈值作为我们最佳的阈值:
- maxindex = (recall - FPR).tolist().index(max(recall - FPR))
- plt.figure()
- plt.plot(FPR, recall, color='red',
- label='ROC curve (area = %0.2f)' % area)
- plt.plot([0, 1], [0, 1], color='black', linestyle='--')
- plt.scatter(FPR[maxindex],recall[maxindex],c="black",s=30)
- plt.xlim([-0.05, 1.05])
- plt.ylim([-0.05, 1.05])
- plt.xlabel('False Positive Rate')
- plt.ylabel('Recall')
- plt.title('Receiver operating characteristic example')
- plt.legend(loc="lower right")
- plt.show()
最后通过下述代码查看最佳的阈值:
-
相关阅读:
C++知识精讲15 | 三类基于贪心思想的区间覆盖问题【配套资源详解】
【手把手带你学JavaSE】全方面带你了解异常
R语言ggplot2可视化:使用ggpubr包的ggbarplot函数可视化柱状图、fill参数指定柱状图的填充色
【C++】:STL——标准模板库介绍 || string类
代理模式
pyinstaller打包python/fastapi项目为exe
7.1-WY22 Fibonacci数列
3.6.4、随机接入-CSMA/CA协议
geant4代码讲解:basicB1(没写完)
安卓Ampere Pro(充电评测)v4.09解锁专业版,供大家学习研究参考!
- 原文地址:https://blog.csdn.net/2301_78195908/article/details/134313133