-
【pandas】数据清洗的几种方法
引言
在数据处理和分析过程中,数据清洗是至关重要的一步。Pandas是Python中用于数据处理和分析的强大库,提供了多种数据清洗方法。本文将介绍几种常用的数据清洗方法:缺失值处理、重复值处理、异常值处理。
准备
这里准备了一份数据集,为了演示数据清洗的过程,该数据集包含了空值、重复行、异常值。
异常值包括过大值和过小值。
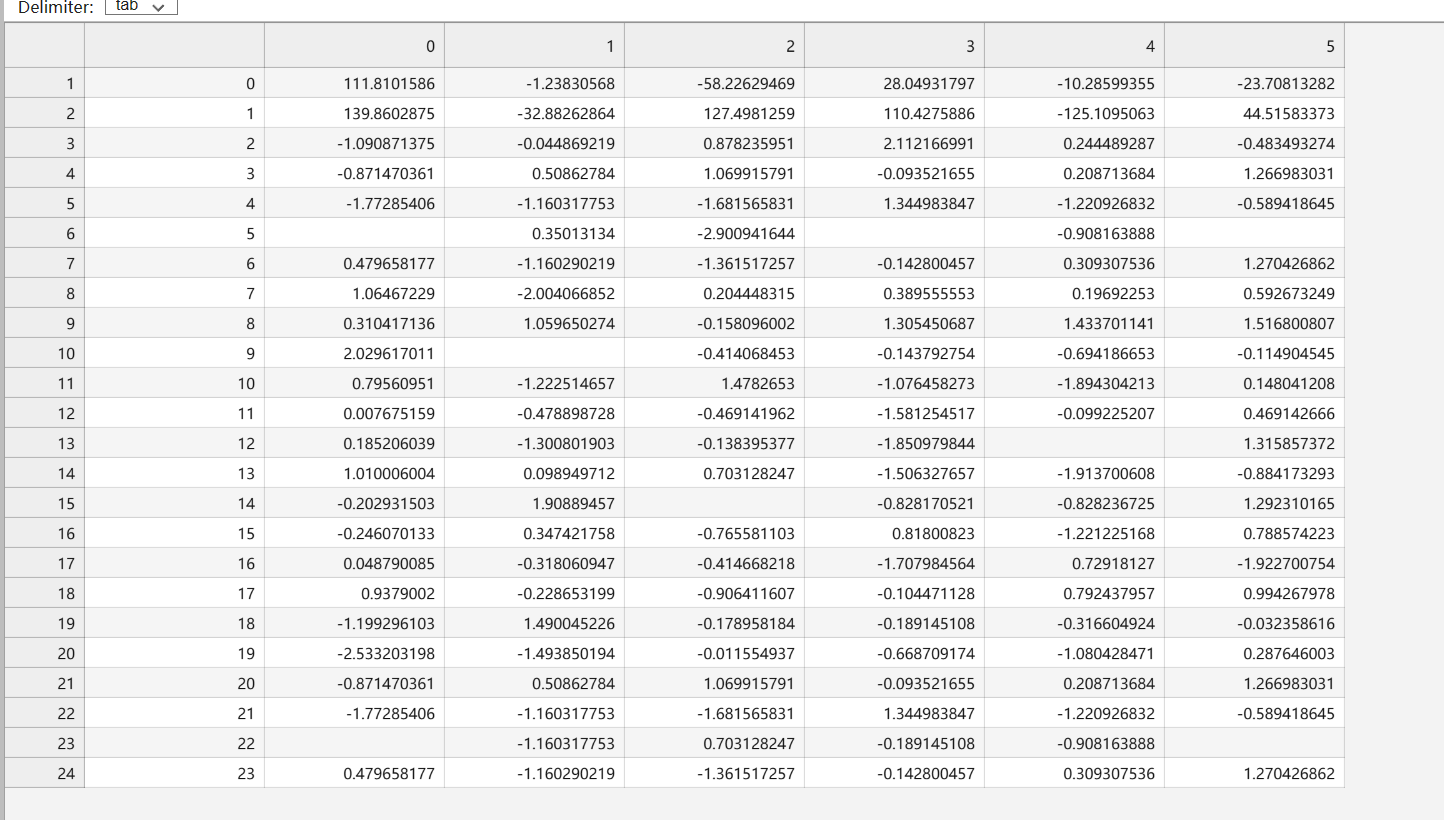
- 读取数据集
import pandas as pd data = pd.read_csv("./tmp.tsv",sep="\t",encoding="gbk") print(data.head(5)) print(data.shape)- 1
- 2
- 3
- 4
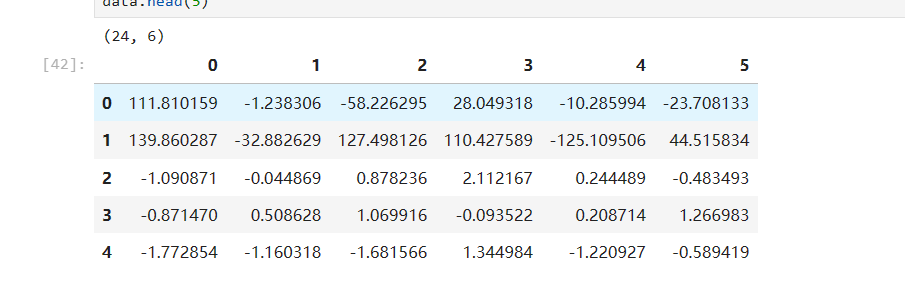
去除重复行
拿到数据集的第一步,我们可以先做去除重复行的操作,该操作可以去除冗余数据,从而提高数据的准确性。
data.drop_duplicates(inplace=True) # 删除重复行 print(data.shape)- 1
- 2

可以看到数据减少了两行填充空值
去除重复行之后数据的样子:

可以看到剩余的数据还有空值的存在,所以接下来的一步就是填充空值。
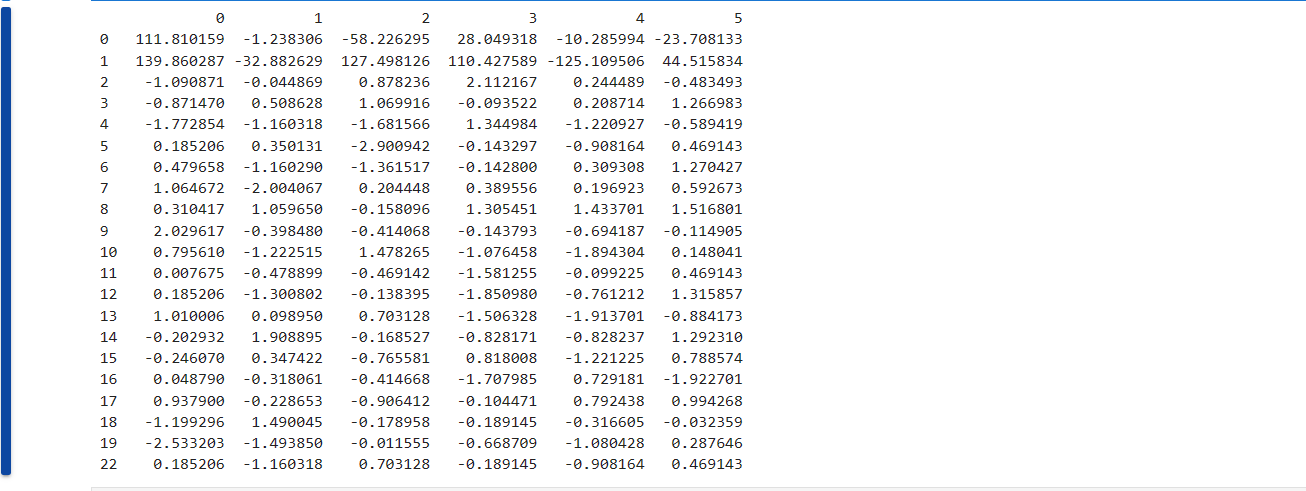
我们可以使用中位数去填充,也可以使用这列的中值填充。- 用中值填充
for col in data.columns: quantile = data[col].quantile() data[col].fillna(quantile,inplace=True) print(data)- 1
- 2
- 3
- 4
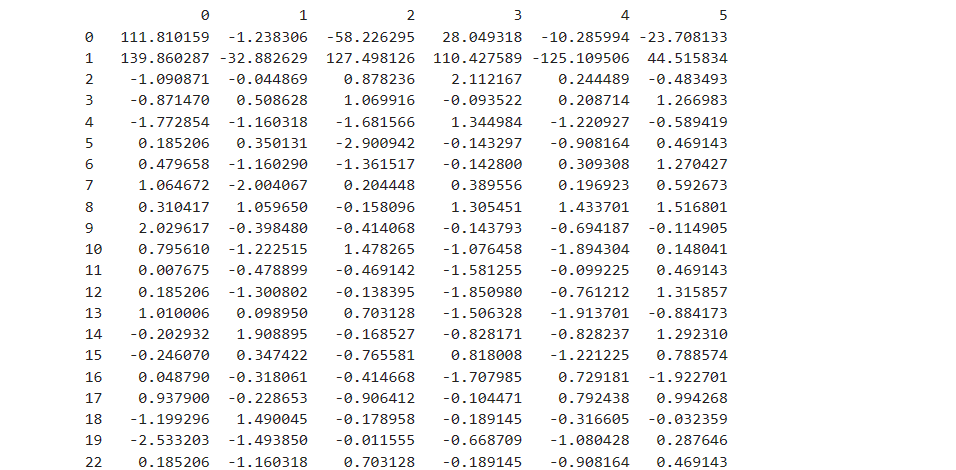
- 用均值填充
for col in data.columns: quantile = data[col].mean() data[col].fillna(quantile,inplace=True) print(data)- 1
- 2
- 3
- 4
去除异常值
填充空值之后,就可以观察数据,找到自己认为的正常数据的范围,并把脱离这个范围的数据整行去除,该操作可以不符合实际情况的异常数据删除,提高数据的质量和准确性,使得数据分析结果更加准确可靠。
查看去除异常值前的data形状:

for col in data.columns: q1 = data[col].quantile(0.25) q3 = data[col].quantile(0.75) iqr = q3 - q1 data = data[(data[col] > q1 - 1.5*iqr) & (data[col] < q3 + 1.5*iqr)]- 1
- 2
- 3
- 4
- 5
- 6
查看去除异常值后的数据形状

这里使用的是IQR方法:
IQR方法是一种基于四分位数的异常值检测方法。它通过计算每个数据点与四分位数之间的距离,来衡量数据点的离散程度。如果某个数据点距离四分位数的距离超过1.5倍的四分位距,则可以将其视为异常值并剔除。
其他常用操作
在数据集中还有一些查看表格的常用方法:
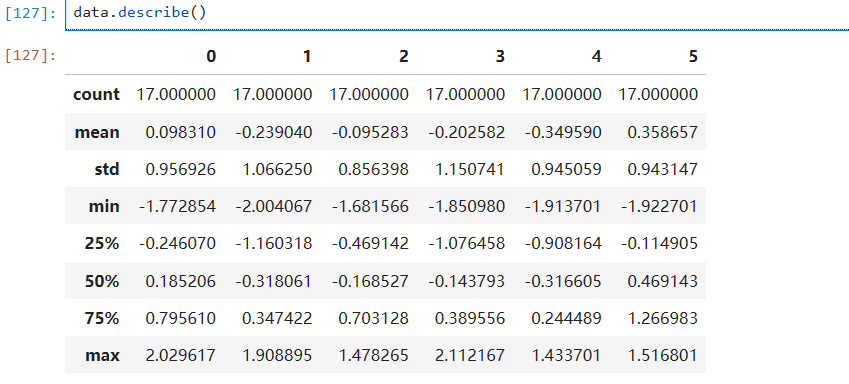
- df.describe()
查看数据的整体情况
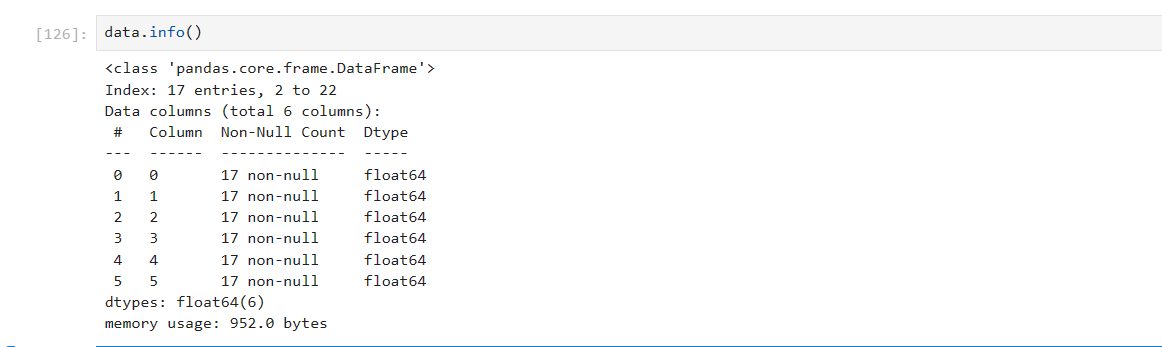
- df.info()
查看数据每列的基本类型,以及每列的空值数量
-
相关阅读:
“一馆一策”保亚运,精准气象服务背后的数据魔法
微擎模块 文明城市小程序1.0.5 文明城市+智慧工商+智慧城管随手拍
【NLP入门教程】十八、支持向量机(Support Vector Machines)
查找内轮廓(孔洞)
【高等数学】微分中值定理
MySQL 日期函数大全(更新中.....)
SpringSecurity基础概念和案例代码
vivado HW_DEVICE
快速排序(非递归)和归并排序
操作系统:银行家算法
- 原文地址:https://blog.csdn.net/fuhao6363/article/details/134331227