-
Netty第三部
继续Netty第二部的内容
一、ChannelHandler
1、ChannelHandler接口
ChannelHandler是Netty的主要组件,处理所有的入站和出站数据的应用程序逻辑的容器,可以应用在数据的格式转换、异常处理、数据报文统计等
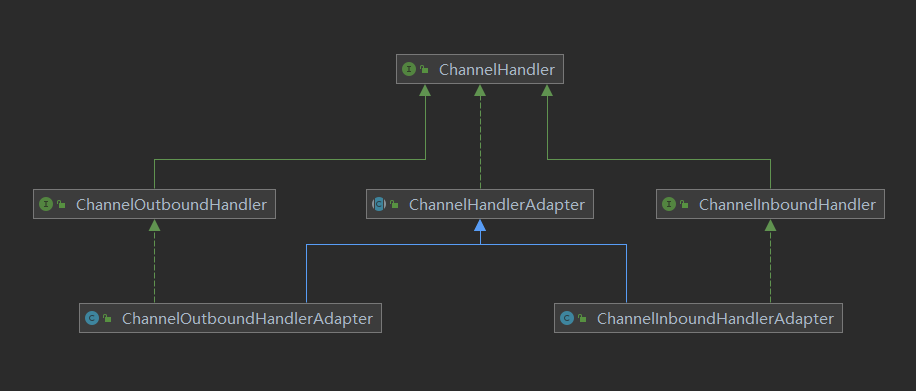
继承ChannelHandler的两个子接口:
ChannelInboundHandler:处理入站数据以及各种状态变化
ChannelOutboundHandler:处理出站数据并且允许拦截所有的操作
2、ChannelInboundHandler接口
- channelRegistered当Channel已经注册到它的EventLoop并且能够处理I/O时被调用
- channelUnregistered当Channel从它的EventLoop注销并且无法处理任何I/O时被调用
- channelActive当Channel处于活动状态时被调用;Channel已经连接/绑定并且已经就绪
- channelInactive当 Channel离开活动状态并且不再连接它的远程节点时被调用
- channelReadComplete当Channel上的一个读操作完成时被调用
- channelRead 当从Channel读取数据时被调用
- channelWritabilityChanged当Channel的可写状态发生改变时被调用。可以通过调用Channel的 isWritable()方法来检测Channel的可写性。与可写性相关的阈值可以通过 Channel.config().setWriteHighWaterMark()和Channel.config().setWriteLowWaterMark()方法来设置
- userEventTriggered当ChannelnboundHandler.fireUserEventTriggered()方法被调用时被调用。
3、ChannelOutboundHandler接口
出站操作和数据将由 ChannelOutboundHandler 处理。它的方法将被 Channel、ChannelPipeline 以及 ChannelHandlerContext 调用。
所有由 ChannelOutboundHandler 本身所定义的方法:
- bind(ChannelHandlerContext,SocketAddress,ChannelPromise) 当请求将 Channel 绑定到本地地址时被调用
- connect(ChannelHandlerContext,SocketAddress,SocketAddress,ChannelPromise) 当请求将 Channel 连接到远程节点时被调用
- disconnect(ChannelHandlerContext,ChannelPromise) 当请求将 Channel 从远程节点断开时被调用
- close(ChannelHandlerContext,ChannelPromise) 当请求关闭 Channel 时被调用
- deregister(ChannelHandlerContext,ChannelPromise) 当请求将 Channel 从它的 EventLoop 注销时被调用
- read(ChannelHandlerContext) 当请求从 Channel 读取更多的数据时被调用
- flush(ChannelHandlerContext) 当请求通过 Channel 将入队数据冲刷到远程节点时被调用
- write(ChannelHandlerContext,Object,ChannelPromise) 当请求通过 Channel 将数据写到 远程节点时被调用
4、ChannelHandler的适配器
ChannelInboundHandlerAdapter(处理入站)和ChannelOutboundHandlerAdapter(处理出站)是Netty提供的ChannelHandler基类,降低了ChannelHandler实现的复杂度
为什么ChannelOutboundHandlerAdapter会有read()方法
ChannelOutboundHandler.read()是主动触发读事件的,或者是处理读事件的前置处理器;调用ChannelOutboundHandler.read()方法时Channel会向Selector读取数据,读取数据之后会交给ChannelPipeline,这时候ChannelPipeline就会触发ChannelInboundHandler.channelRead()读事件
如何在一个ChannelHandler实现同时实现入栈出战
继承ChannelDuplexHandler,也可以同时实现ChannelOutboundHandler, ChannelInboundHandler这两个接口
5、共享Handler
ChannelHandlerAdapter提供了isSharable()方法,如果实现ChannelHandler的类上指定了@Sharable注解,isSharable()方法就会返回true,反之则否;
每个SocketChannel都有自己的ChannelPipeline,同时SocketChannel会对应一个EventLoop,也就是说只会一个线程来处理,ChannelHandler实例之间是完全独立,只要不是共享了全局变量,ChannelHandler是线程安全的
如何通过共享Handler实现包统计
继承ChannelDuplexHandler类,同时类上加上@Sharable注解注解,指定该实例为static,保证只有一个,添加到ChannelPipeline中,重写read()和flush()方法,就可以具体发包收包记录了
6、资源管理和SimpleChannelInboundHandler
在NIO实现中需要依靠创建buffer来进行Channel之间的数据交换;
Netty也是同样的设计,在read网络数据时由Netty创建Buffer,write时会拿到这个Buffer写到网络中(outBoundHandler处理了write()操作并丢弃了数据,而read()需要继续往下一个Handler传递,所以没有相关处理)
可能产生内存泄露的情况:
- 没有调用相关的fireChannelRead方法,也不释放Buffer
- 执行channelRead方法抛出异常导致fireChannelRead方法未执行,同时也不释放Buffer
正常执行fireChannelRead方法入站往后传递Buffer,Netty都会释放Buffer,Netty提供了SimpleChannelInboundHandler类来支持这种情况,继承SimpleChannelInboundHandler类,重写channelRead0方法,即使不抛出异常,也不调用fireChannelRead方法,最终Netty也会帮我们做Buffer的释放
- @Override
- public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
- boolean release = true;
- try {
- if (acceptInboundMessage(msg)) {
- @SuppressWarnings("unchecked")
- I imsg = (I) msg;
- channelRead0(ctx, imsg);
- } else {
- release = false;
- ctx.fireChannelRead(msg);
- }
- } finally {
- if (autoRelease && release) {
- ReferenceCountUtil.release(msg);
- }
- }
- }
- /**
- * Is called for each message of type {@link I}.
- *
- * @param ctx the {@link ChannelHandlerContext} which this {@link SimpleChannelInboundHandler}
- * belongs to
- * @param msg the message to handle
- * @throws Exception is thrown if an error occurred
- */
- protected abstract void channelRead0(ChannelHandlerContext ctx, I msg) throws Exception;
二、Netty内置通信传输模式
- NIO:io.netty.channel.socket.nio 使用java.nio.channels包作为基础——基于选择器的方式
- Epoll:io.netty.channel.epoll 由JNI驱动的epoll()和非阻塞 IO。这个传输支持只有在Linux上可用的多种特性,如SO_REUSEPORT,比NIO传输更快,而且是完全非阻塞的。将NioEventLoopGroup替换为EpollEventLoopGroup,并且将NioServerSocketChannel.class替换为EpollServerSocketChannel.class即可。
- OIO:io.netty.channel.socket.oio 使用java.net包作为基础——使用阻塞流
- Local:io.netty.channel.local 可以在VM内部通过管道进行通信的本地传输
- Embedded:io.netty.channel.embedded Embedded 传输,允许使用ChannelHandler而又不需要一个真正的基于网络的传输。在测试ChannelHandler实现时非常有用
三、引导Bootstrap
ServerBootstrap将绑定到一个端口,因为服务器必须要监听连接,而Bootstrap则是由想要连接到远程节点的客户端应用程序所使用的。
引导一个客户端只需要一个EventLoopGroup,但是一个ServerBootstrap则需要两个(也可以是同一个实例)
- @Override
- public ServerBootstrap group(EventLoopGroup group) {
- return group(group, group);
- }
- /**
- * Set the {@link EventLoopGroup} for the parent (acceptor) and the child (client). These
- * {@link EventLoopGroup}'s are used to handle all the events and IO for {@link ServerChannel} and
- * {@link Channel}'s.
- */
- public ServerBootstrap group(EventLoopGroup parentGroup, EventLoopGroup childGroup) {
- super.group(parentGroup);
- if (this.childGroup != null) {
- throw new IllegalStateException("childGroup set already");
- }
- this.childGroup = ObjectUtil.checkNotNull(childGroup, "childGroup");
- return this;
- }
与ServerChannel相关联的EventLoopGroup将分配一个负责为传入连接请求创建Channel的EventLoop。一旦连接被接受,第二个EventLoopGroup就会给它的Channel分配 一个EventLoop。
四、ChannelInitializer
ChannelInitializer是ChannelInboundHandlerAdapter的子类,当中的initChannel()方法提供了一种将多个ChannelHandler添加到一个ChannelPipeline中的简便方法。你只需要简单地向Bootstrap或ServerBootstrap的实例提供你的ChannelInitializer实现即可,并且一旦Channel被注册到了它的EventLoop之后,就会调用你的initChannel()版本。在该方法返回之后,ChannelInitializer的实例将会从ChannelPipeline中移除它自己。
- /**
- * This method will be called once the {@link Channel} was registered. After the method returns this instance
- * will be removed from the {@link ChannelPipeline} of the {@link Channel}.
- *
- * @param ch the {@link Channel} which was registered.
- * @throws Exception is thrown if an error occurs. In that case it will be handled by
- * {@link #exceptionCaught(ChannelHandlerContext, Throwable)} which will by default close
- * the {@link Channel}.
- */
- protected abstract void initChannel(C ch) throws Exception;
- @SuppressWarnings("unchecked")
- private boolean initChannel(ChannelHandlerContext ctx) throws Exception {
- if (initMap.add(ctx)) { // Guard against re-entrance.
- try {
- initChannel((C) ctx.channel());
- } catch (Throwable cause) {
- // Explicitly call exceptionCaught(...) as we removed the handler before calling initChannel(...).
- // We do so to prevent multiple calls to initChannel(...).
- exceptionCaught(ctx, cause);
- } finally {
- ChannelPipeline pipeline = ctx.pipeline();
- if (pipeline.context(this) != null) {
- pipeline.remove(this);
- }
- }
- return true;
- }
- return false;
- }
五、ChannelOption
- ChannelOption.SO_BACKLOG:对应的是 tcp/ip 协议 listen 函数中的 backlog 参数,从Linux2.2开始,backlog的参数行为在Linux2.2中发生了变化,现在它指定等待接受的完全建立的套接字的队列长度,而不是不完整的连接请求的数量
- ChannelOption.SO_REUSEADDR:对应于套接字选项中的SO_REUSEADDR,这个参数表示允许重复使用本地地址和端口
- ChannelOption.SO_KEEPALIVE:对应于套接字选项中的 SO_KEEPALIVE,如果在两小时内没有数据的通信时,TCP会自动发送一 个活动探测数据报文,确定连接状态
- ChannelOption.SO_SNDBUF和ChannelOption.SO_RCVBUF:对应于套接字选项中的 SO_SNDBUF和 SO_RCVBUF,这两个参数用于操作接 收缓冲区和发送缓冲区的大小
- ChannelOption.SO_LINGER: 对应于套接字选项中的 SO_LINGER,保证TCP四次回收最后一次发送close()时数据传输完毕
- ChannelOption.TCP_NODELAY:对应于套接字选项中的TCP_NODELAY,该参数的使用与Nagle算法有关,Nagle算法是将小的数据包组装为更大的帧然后进行发送,而不是输入一次发送一次,因此在数据包不足的时候会等待其他数据的到了,组装成大的数据包进行发送,虽然该方式有效提高网络的有效负载,但是却造成了延时,而该参数的作用就是禁止使用Nagle算法,使用于小数据即时传输,于TCP_NODELAY相对应的是TCP_CORK,该选项是需要等到发送的数据量最大的时候,一次性发送数据,适用于文件传输。
六、ByteBuf
ByteBuf 维护了两个不同的索引,名称以 read 或者 write 开头的 ByteBuf 方法,将会 推进其对应的索引,而名称以 set 或者 get 开头的操作则不会。 如果打算读取字节直到 readerIndex 达到和 writerIndex 同样的值时会发生什么。在那 时,你将会到达“可以读取的”数据的末尾。就如同试图读取超出数组末尾的数据一样,试 图读取超出该点的数据将会触发一个 IndexOutOf-BoundsException。 可以指定 ByteBuf 的最大容量。试图移动写索引(即 writerIndex)超过这个值将会触发 一个异常。(默认的限制是 Integer.MAX_VALUE。)
七、粘包/半包问题
1、TCP粘包/半包发生的原因
分包产生的原因就简单的多:就是一个数据包被分成了多次接收。 更具体的原因至少包括:
- 应用程序写入数据的字节大小大于套接字发送缓冲区的大小
- 进行 MSS大小的TCP分段。MSS是最大报文段长度的缩写。MSS是TCP报文段中的 数据字段的最大长度。数据字段加上TCP首部才等于整个的TCP报文段。所以MSS并不是TCP报文段的最大长度,而是:MSS=TCP报文段长度-TCP首部长度。
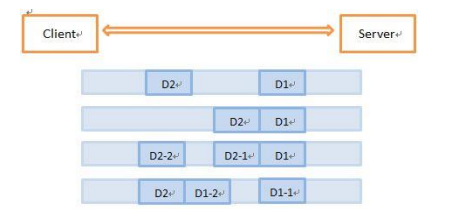
假设客户端分别发送了两个数据包D1和D2给服务端,由于服务端一次读取到的字节 数是不确定的,故可能存在以下 4 种情况。
- 服务端分两次读取到了两个独立的数据包,分别是D1和D2,没有粘包和拆包;
- 服务端一次接收到了两个数据包,D1和D2粘合在一起,被称为TCP粘包;
- 服务端分两次读取到了两个数据包,第一次读取到了完整的D1包和D2包的部分内容,第二次读取到了D2包的剩余内容,这被称为TCP拆包;
- 服务端分两次读取到了两个数据包,第一次读取到了D1包的部分内容D1_1,第 二次读取到了D1包的剩余内容D1_2和D2包的整包。
如果此时服务端TCP接收滑窗非常小,而数据包D1和D2比较大,很有可能会发生第五种可能,即服务端分多次才能将D1和D2包接收完全,期间发生多次拆包。
2、解决TCP粘包/半包问题
由于底层的 TCP 无法理解上层的业务数据,所以在底层是无法保证数据包不被拆分和重 组的,这个问题只能通过上层的应用协议栈设计来解决,根据业界的主流协议的解决方案, 可以归纳如下。
- 在包尾增加分割符,比如回车换行符进行分割,例如 FTP 协议; 参见 cn.tuling.nettybasic.splicing.linebase(回车换行符进行分割)和 cn.tuling.nettybasic.splicing.delimiter(自定义分割符)下的代码
- 消息定长,例如每个报文的大小为固定长度 200 字节,如果不够,空位补空格; 参见 cn.tuling.nettybasic.splicing.fixed 下的代码
- 将消息分为消息头和消息体,消息头中包含表示消息总长度(或者消息体长度) 的字段,通常设计思路为消息头的第一个字段使用 int32 来表示消息的总长度,使用 LengthFieldBasedFrameDecoder
4、分析channelRead和channelReadComplete
- Netty是在读到完整的业务请求报文后才调用一次业务ChannelHandler的channelRead方法
- 如果一个业务消息被TCP协议栈发送了N次,则服务端的channelReadComplete方法就会被调用N次。
九、编码器和解码器
- 将字节解码为消息——ByteToMessageDecoder
- 将一种消息类型解码为另一种——MessageToMessageDecoder。
十、序列化问题
1、Java序列化的缺点
- 无法跨语言
- 序列化后的码流太大
- 序列化性能太低
2、序列化框架
具体可以参考:几种Java常用序列化框架的选型与对比-阿里云开发者社区
-
相关阅读:
element vue表格单选
小学生python游戏编程arcade----单词对错检测及记录写入excel中
牛客--放苹果python
汽车行业使用LDO直接连接电池的应用
chatGPT的耳朵!OpenAI的开源语音识别AI:Whisper !
啥样的python语法值得收藏?
再回首 Java核心技术 2 —— Java数据类型
k8s 增加 node 节点
vue利用openlayers实现动态轨迹
装饰者模式
- 原文地址:https://blog.csdn.net/gp3056/article/details/134322649
