-
【微软技术栈】C#.NET 正则表达式源生成器
本文内容
- 已编译的正则表达式
- 源生成
- 在源生成的文件中
- 何时使用
正则表达式 (regex) 是一个字符串,它使开发人员能够表达要搜索的模式,使其成为搜索文本和提取结果作为已搜索字符串子集的一种很常见的方法。 在 .NET 中,
System.Text.RegularExpressions命名空间用于定义 Regex 实例和静态方法,并匹配用户定义的模式。 本文介绍如何使用源生成来生成Regex实例以优化性能。备注
请尽可能地使用源生成的正则表达式,而不是使用 RegexOptions.Compiled 选项编译正则表达式。 源生成可帮助应用更快地启动、更快地运行且更易剪裁。
1、已编译的正则表达式
编写
new Regex("somepattern")时,会发生一些事情。 将分析指定的模式,既要确保模式的有效性,又要将其转换为表示已分析正则表达式的内部树。 然后,以各种方式优化树,将模式转换为功能上等效的变体,可以更高效地执行。 该树被写入一种形式,可以解释为一系列操作码和操作数,它们提供有关如何匹配的正则表达式解释器引擎的说明。 执行匹配时,解释器只需遍历这些指令,针对输入文本处理它们。 实例化新的Regex实例或调用Regex上的一个静态方法时,解释器是采用的默认引擎。指定 RegexOptions.Compiled 时,将执行所有相同的构造时间工作。 生成的指令将由基于反射发出的编译器进一步转换为 IL 指令,这些指令将写入几个 DynamicMethod。 执行匹配时,将调用这些
DynamicMethod。 此 IL 实质上将完全执行解释器将执行的操作,但专用于所处理的确切模式除外。 例如,如果模式包含[ac],解释器将看到一个操作码,表示“将当前位置的输入字符与在此集说明中指定的集匹配”,而编译的 IL 将包含有效表示“将目前位置的输入字母与'a'或'c'相匹配”的代码。 这种特殊的大小写和基于模式知识执行优化的能力是指定RegexOptions.Compiled比解释器产生更快的匹配吞吐量的主要原因。RegexOptions.Compiled有几个缺点。 最有影响力的是,它产生的构造成本比使用解释器要多得多。 不仅要为解释器支付相同的成本,而且还需要将生成的RegexNode树和生成的操作码/操作数编译到 IL 中,这会增加不小的开销。 生成的 IL 还需要在首次使用时进行 JIT 编译,这会导致启动时产生更多费用。RegexOptions.Compiled表示首次使用开销与每次后续使用开销之间的基本权衡。 System.Reflection.Emit 的使用也会抑制某些环境中RegexOptions.Compiled的使用;某些操作系统不允许动态生成的代码执行,并且在此类系统上,Compiled将变为无操作。2、源生成
.NET 7 引入了新的
RegexGenerator源生成器。 当 C# 编译器重写为“Roslyn”C# 编译器时,它将公开整个编译管道的对象模型以及分析器。 最近,Roslyn 已启用源生成器。 就像分析器一样,源生成器是插入编译器的组件,并且可以提供与分析器相同的所有信息,但除了能够发出诊断信息外,它还可以使用其他源代码来增强编译单元。 .NET 7 SDK 包含一个新的源生成器,用于识别返回Regex的分部方法上的新 GeneratedRegexAttribute。 源生成器提供该方法的实现,该方法用于实现Regex的所有逻辑。 例如,可能已编写如下所示的代码:- private static readonly Regex s_abcOrDefGeneratedRegex =
- new(pattern: "abc|def",
- options: RegexOptions.Compiled | RegexOptions.IgnoreCase);
- private static void EvaluateText(string text)
- {
- if (s_abcOrDefGeneratedRegex.IsMatch(text))
- {
- // Take action with matching text
- }
- }
现在可以按如下所示重写前面的代码:
- [GeneratedRegex("abc|def", RegexOptions.IgnoreCase, "en-US")]
- private static partial Regex AbcOrDefGeneratedRegex();
- private static void EvaluateText(string text)
- {
- if (AbcOrDefGeneratedRegex().IsMatch(text))
- {
- // Take action with matching text
- }
- }
生成的
AbcOrDefGeneratedRegex()实现同样缓存Regex单一实例,因此不需要额外的缓存来使用代码。提示
源生成器会忽略标志
RegexOptions.Compiled,因此在源生成的版本中不再需要它。
但可以看到,它不仅仅是在执行
new Regex(...)。 相反,源生成器以 C# 代码的形式发出自定义Regex派生实现,其逻辑类似于 IL 中RegexOptions.Compiled发出的内容。 可以获得RegexOptions.Compiled的所有吞吐量性能优势(实际上更多)和Regex.CompileToAssembly的启动优势,但没有CompileToAssembly的复杂性。 发出的源是项目的一部分,这意味着它也可以轻松查看和调试。
提示
在 Visual Studio 中,右键单击分部方法声明,然后选择“转到定义”。 或者,也可以在“解决方案资源管理器”中选择项目节点,然后展开“依赖项”>“分析器”>“System.Text.RegularExpressions.Generator”>“System.Text.RegularExpressions.Generator.RegexGenerator”>“RegexGenerator.gcs”,查看从此正则表达式生成器生成的 C# 代码。
可以在其中设置断点,可以逐步执行,并可以使用它作为学习工具来准确了解正则表达式引擎使用输入处理模式的方式。 生成器甚至会生成三斜杠 (XML) 注释,以帮助使表达式一目了然和了解使用的位置。
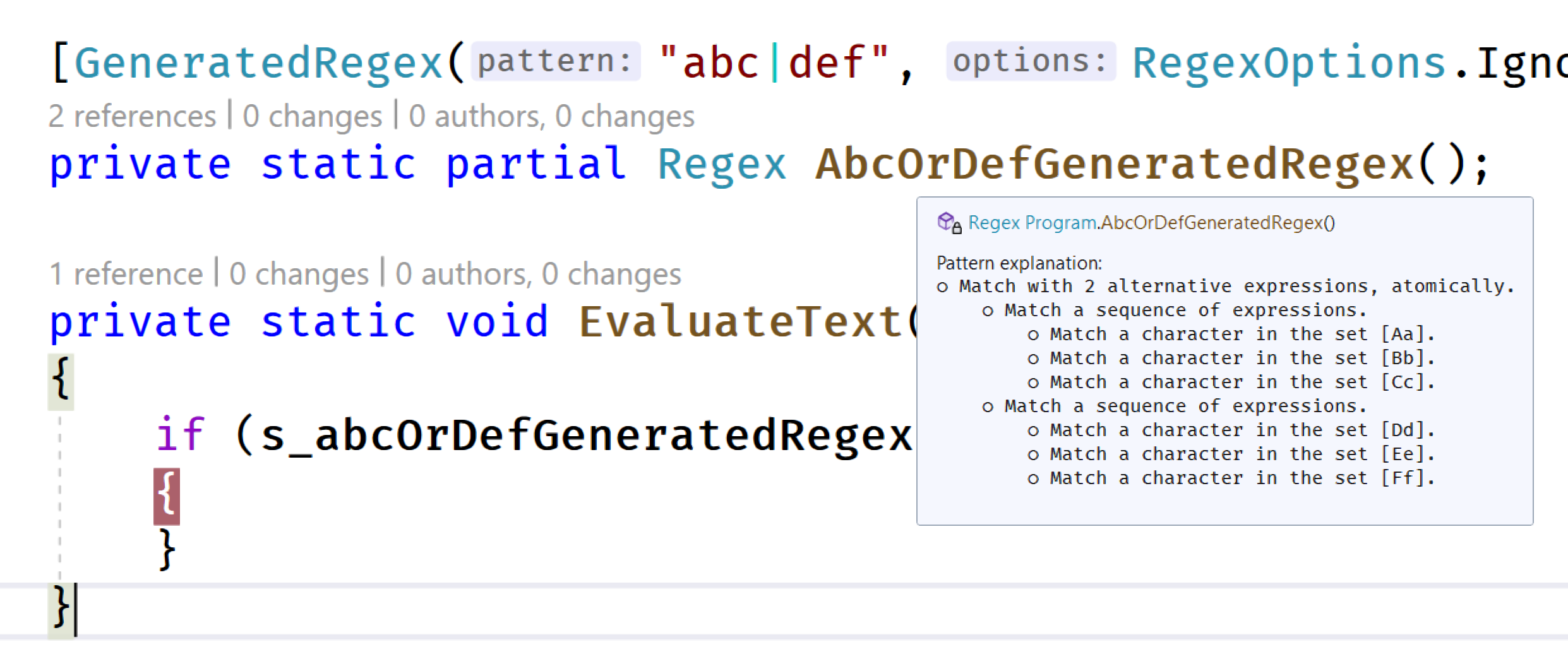
3、在源生成的文件中
使用 .NET 7 时,源生成器和
RegexCompiler几乎完全重写,从根本上改变了生成的代码的结构。 此方法已扩展,以处理所有构造(有一个警告),RegexCompiler和源生成器仍遵循新方法以 1:1 的方式彼此映射。 请考虑(a|bc)d表达式中某个主要函数的源生成器输出:- private bool TryMatchAtCurrentPosition(ReadOnlySpan<char> inputSpan)
- {
- int pos = base.runtextpos;
- int matchStart = pos;
- int capture_starting_pos = 0;
- ReadOnlySpan<char> slice = inputSpan.Slice(pos);
- // 1st capture group.
- //{
- capture_starting_pos = pos;
- // Match with 2 alternative expressions.
- //{
- if (slice.IsEmpty)
- {
- UncaptureUntil(0);
- return false; // The input didn't match.
- }
- switch (slice[0])
- {
- case 'a':
- pos++;
- slice = inputSpan.Slice(pos);
- break;
- case 'b':
- // Match 'c'.
- if ((uint)slice.Length < 2 || slice[1] != 'c')
- {
- UncaptureUntil(0);
- return false; // The input didn't match.
- }
- pos += 2;
- slice = inputSpan.Slice(pos);
- break;
- default:
- UncaptureUntil(0);
- return false; // The input didn't match.
- }
- //}
- base.Capture(1, capture_starting_pos, pos);
- //}
- // Match 'd'.
- if (slice.IsEmpty || slice[0] != 'd')
- {
- UncaptureUntil(0);
- return false; // The input didn't match.
- }
- // The input matched.
- pos++;
- base.runtextpos = pos;
- base.Capture(0, matchStart, pos);
- return true;
- // <summary>Undo captures until it reaches the specified capture position.</summary>
- [MethodImpl(MethodImplOptions.AggressiveInlining)]
- void UncaptureUntil(int capturePosition)
- {
- while (base.Crawlpos() > capturePosition)
- {
- base.Uncapture();
- }
- }
- }
源生成的代码的目标易于理解,具有易于遵循的结构,具有解释每个步骤正在执行的操作的注释,并且通常根据指导原则发出代码,即生成器应发出代码,就像人类编写代码一样。 即使涉及回溯,回溯的结构也会成为代码结构的一部分,而不是依赖堆栈来指示下一步的跳转位置。 例如,以下是表达式为
[ab]*[bc]时生成的相同匹配函数的代码:- private bool TryMatchAtCurrentPosition(ReadOnlySpan<char> inputSpan)
- {
- int pos = base.runtextpos;
- int matchStart = pos;
- int charloop_starting_pos = 0, charloop_ending_pos = 0;
- ReadOnlySpan<char> slice = inputSpan.Slice(pos);
- // Match a character in the set [ab] greedily any number of times.
- //{
- charloop_starting_pos = pos;
- int iteration = slice.IndexOfAnyExcept('a', 'b');
- if (iteration < 0)
- {
- iteration = slice.Length;
- }
- slice = slice.Slice(iteration);
- pos += iteration;
- charloop_ending_pos = pos;
- goto CharLoopEnd;
- CharLoopBacktrack:
- if (Utilities.s_hasTimeout)
- {
- base.CheckTimeout();
- }
- if (charloop_starting_pos >= charloop_ending_pos ||
- (charloop_ending_pos = inputSpan.Slice(
- charloop_starting_pos, charloop_ending_pos - charloop_starting_pos)
- .LastIndexOfAny('b', 'c')) < 0)
- {
- return false; // The input didn't match.
- }
- charloop_ending_pos += charloop_starting_pos;
- pos = charloop_ending_pos;
- slice = inputSpan.Slice(pos);
- CharLoopEnd:
- //}
- // Advance the next matching position.
- if (base.runtextpos < pos)
- {
- base.runtextpos = pos;
- }
- // Match a character in the set [bc].
- if (slice.IsEmpty || !char.IsBetween(slice[0], 'b', 'c'))
- {
- goto CharLoopBacktrack;
- }
- // The input matched.
- pos++;
- base.runtextpos = pos;
- base.Capture(0, matchStart, pos);
- return true;
- }
可以在代码中看到回溯的结构,其中发出了一个
CharLoopBacktrack标签(用于回溯到的位置)和一个goto(用于在正则表达式后续部分失败时跳转到该位置)。如果查看实现
RegexCompiler的代码和源生成器,它们看起来非常相似:类似命名的方法、类似的调用结构,甚至整个实现中的类似注释。 在大多数情况下,它们会生成相同的代码,尽管一个在 IL 中,一个在 C# 中。 当然,C# 编译器负责将 C# 转换为 IL,因此这两种情况下生成的 IL 可能不相同。 源生成器依赖于在各种情况下,利用 C# 编译器进一步优化各种 C# 构造的事实。 因此,与RegexCompiler相比,源生成器将生成一些更优化的匹配代码。 例如,在前面的一个示例中,可以看到发出 switch 语句的源生成器,其中一个分支用于'a',另一个分支用于'b'。 由于 C# 编译器非常擅长优化 switch 语句,可以使用多种策略来有效地优化语句,因此源生成器具有一种RegexCompiler无法进行的特殊优化。 对于交替,源生成器将查看所有分支,如果可以证明每个分支都以不同的起始字符开头,它将在第一个字符上发出 switch 语句,并避免为该交替输出任何回溯代码。下面是一个稍微复杂的相关示例。 在 .NET 7 中,将更深入地分析交替,以确定是否可以采用某种方式重构它们,从而使它们更容易被回溯引擎优化,这将导致更简单的源生成的代码。 其中一种优化支持从分支中提取常见前缀,如果交替是原子性的,则排序并不重要,重新排序分支以允许更多此类提取。 可以看到这对以下工作日模式
Monday|Tuesday|Wednesday|Thursday|Friday|Saturday|Sunday的影响,该模式生成如下匹配函数:- private bool TryMatchAtCurrentPosition(ReadOnlySpan
inputSpan) - {
- int pos = base.runtextpos;
- int matchStart = pos;
- ReadOnlySpan
slice = inputSpan.Slice(pos); - // Match with 5 alternative expressions, atomically.
- {
- if (slice.IsEmpty)
- {
- return false; // The input didn't match.
- }
- switch (slice[0])
- {
- case 'M':
- // Match the string "onday".
- if (!slice.Slice(1).StartsWith("onday"))
- {
- return false; // The input didn't match.
- }
- pos += 6;
- slice = inputSpan.Slice(pos);
- break;
- case 'T':
- // Match with 2 alternative expressions, atomically.
- {
- if ((uint)slice.Length < 2)
- {
- return false; // The input didn't match.
- }
- switch (slice[1])
- {
- case 'u':
- // Match the string "esday".
- if (!slice.Slice(2).StartsWith("esday"))
- {
- return false; // The input didn't match.
- }
- pos += 7;
- slice = inputSpan.Slice(pos);
- break;
- case 'h':
- // Match the string "ursday".
- if (!slice.Slice(2).StartsWith("ursday"))
- {
- return false; // The input didn't match.
- }
- pos += 8;
- slice = inputSpan.Slice(pos);
- break;
- default:
- return false; // The input didn't match.
- }
- }
- break;
- case 'W':
- // Match the string "ednesday".
- if (!slice.Slice(1).StartsWith("ednesday"))
- {
- return false; // The input didn't match.
- }
- pos += 9;
- slice = inputSpan.Slice(pos);
- break;
- case 'F':
- // Match the string "riday".
- if (!slice.Slice(1).StartsWith("riday"))
- {
- return false; // The input didn't match.
- }
- pos += 6;
- slice = inputSpan.Slice(pos);
- break;
- case 'S':
- // Match with 2 alternative expressions, atomically.
- {
- if ((uint)slice.Length < 2)
- {
- return false; // The input didn't match.
- }
- switch (slice[1])
- {
- case 'a':
- // Match the string "turday".
- if (!slice.Slice(2).StartsWith("turday"))
- {
- return false; // The input didn't match.
- }
- pos += 8;
- slice = inputSpan.Slice(pos);
- break;
- case 'u':
- // Match the string "nday".
- if (!slice.Slice(2).StartsWith("nday"))
- {
- return false; // The input didn't match.
- }
- pos += 6;
- slice = inputSpan.Slice(pos);
- break;
- default:
- return false; // The input didn't match.
- }
- }
- break;
- default:
- return false; // The input didn't match.
- }
- }
- // The input matched.
- base.runtextpos = pos;
- base.Capture(0, matchStart, pos);
- return true;
- }
请注意
Thursday是如何被重新排序为紧跟在Tuesday之后的,以及Tuesday/Thursday对和Saturday/Sunday对如何以多级开关结束。 在极端情况下,如果你要创建许多不同单词的长交替,源生成器最终会发出 trie^1 的逻辑等效项,从而读取每个字符并switch(切换)到用于处理单词的其余部分的分支。 这是匹配字词的一种非常高效的方法,也是源生成器在此处执行的操作。同时,源生成器还有其他问题需要解决,直接输出到 IL 时根本不存在这些问题。 如果你回过头来看看几个代码示例,可以看到一些大括号有些奇怪地注释掉了。这不是一个错误。 源生成器认识到,如果未注释掉这些大括号,则回溯的结构依赖于从范围外跳到该范围内定义的标签;此类标签对于此类
goto不可见,代码将无法编译。 因此,源生成器需要避免在方式上存在范围。 在某些情况下,只需按照此处所述注释掉范围。 在其他不可能的情况下,如果这样做会有问题,有时可能会避免需要范围的构造(例如多语句if块)。源生成器处理所有
RegexCompiler句柄,但有一个例外。 与处理RegexOptions.IgnoreCase一样,实现现在使用大小写表在构造时生成集,以及IgnoreCase向后引用匹配需要查阅该大小写表的方式。 该表是System.Text.RegularExpressions.dll的内部表,至少目前,该程序集的外部代码(包括源生成器发出的代码)没有访问该表的权限。 这使得处理IgnoreCase向后引用在源生成器中成为一个挑战,并且它们不受支持。 这是RegexCompiler支持的源生成器不支持的一个构造。 如果尝试使用具有其中之一(这种情况很少见)的模式,源生成器不会发出自定义实现,而是回退到缓存常规Regex实例:
此外,
RegexCompiler和源生成器都不支持新的RegexOptions.NonBacktracking。 如果指定RegexOptions.Compiled | RegexOptions.NonBacktracking,则只会忽略Compiled标志,如果将NonBacktracking指定给源生成器,它将同样回退到缓存常规Regex实例。4、何时使用
一般指导是,如果可以使用源生成器,请使用它。 如果当前在 C# 中使用
Regex,并且在编译时有已知的参数,特别是如果你已经在使用RegexOptions.Compiled(因为正则表达式已被确定为一个热点,可以从更快的吞吐量中受益),则应更倾向于使用源生成器。 源生成器将为正则表达式提供以下优势:RegexOptions.Compiled的所有吞吐量优势。- 在运行时不必执行所有正则表达式解析、分析和编译的启动优势。
- 将提前编译与为正则表达式生成的代码一起使用的选项。
- 更好的可调试性和对正则表达式的理解。
- 通过剪裁与
RegexCompiler关联的大量代码(甚至可能是反射发出自身),可以减小剪裁后的应用程序的大小。
当与源生成器无法为其生成自定义实现的
RegexOptions.NonBacktracking等选项一起使用时,它仍将发出描述实现的缓存和 XML 注释,使其很有价值。 源生成器的主要缺点是它会向程序集发出其他代码,因此可能会增加大小。 应用程序中的正则表达式越多,它们就越大,将为它们发出的代码就越多。 在某些情况下,同样RegexOptions.Compiled可能不是必要的,源生成器也可能不是必要的。 例如,如果你有一个仅需要很少且吞吐量无关紧要的正则表达式,那么仅依赖解释器进行零星使用可能更有益。重要
.NET 7 包含一个分析器,用于标识可转换为源生成器的
Regex的使用,还包含一个为你执行转换的修复程序:
-
相关阅读:
(黑马出品_02)SpringCloud+RabbitMQ+Docker+Redis+搜索+分布式
一个简单的HTML网页 故宫学生网页设计作品 dreamweaver作业静态HTML网页设计模板 旅游景点网页作业制作
第1讲:MyBatis简介与入门
JavaScript 日常开发的 9 个实用代码片段 (part 1)
LegalAI领域大规模预训练语言模型的整理、总结及介绍(持续更新ing…)
Qt区分左右Shift按键
Android — 使用 Runtime 获取日志并保存至 download 目录
Pytorch与keras的差别
百趣代谢组学资讯:哮喘真的和痰液有关系?来问问科研大佬们怎么说
数据结构之单向链表
- 原文地址:https://blog.csdn.net/m0_51887793/article/details/134235445



