-
Pytorch R-CNN目标检测-汽车car
概述
目标检测(Object Detection)就是一种基于目标几何和统计特征的图像分割,它将目标的分割和识别合二为一,通俗点说就是给定一张图片要精确的定位到物体所在位置,并完成对物体类别的识别。其准确性和实时性是整个系统的一项重要能力。
R-CNN的全称是Region-CNN(区域卷积神经网络),是第一个成功将深度学习应用到目标检测上的算法。R-CNN基于卷积神经网络(CNN),线性回归,和支持向量机(SVM)等算法,实现目标检测技术。
以下的代码和项目工程是引用他人的,此文只对其做一个简单的流程梳理。
这里先贴出工具脚本util.py的代码如下
- # -*- coding: utf-8 -*-
- """
- @date: 2020/2/29 下午7:31
- @file: util.py
- @author: zj
- @description:
- """
- import os
- import numpy as np
- import xmltodict
- import torch
- import matplotlib.pyplot as plt
- def check_dir(data_dir):
- if not os.path.exists(data_dir):
- os.mkdir(data_dir)
- def parse_car_csv(csv_dir):
- csv_path = os.path.join(csv_dir, 'car.csv')
- samples = np.loadtxt(csv_path, dtype='str')
- return samples
- def parse_xml(xml_path):
- """
- 解析xml文件,返回标注边界框坐标
- """
- # print(xml_path)
- with open(xml_path, 'rb') as f:
- xml_dict = xmltodict.parse(f)
- # print(xml_dict)
- bndboxs = list()
- objects = xml_dict['annotation']['object']
- if isinstance(objects, list):
- for obj in objects:
- obj_name = obj['name']
- difficult = int(obj['difficult'])
- if 'car'.__eq__(obj_name) and difficult != 1:
- bndbox = obj['bndbox']
- bndboxs.append((int(bndbox['xmin']), int(bndbox['ymin']), int(bndbox['xmax']), int(bndbox['ymax'])))
- elif isinstance(objects, dict):
- obj_name = objects['name']
- difficult = int(objects['difficult'])
- if 'car'.__eq__(obj_name) and difficult != 1:
- bndbox = objects['bndbox']
- bndboxs.append((int(bndbox['xmin']), int(bndbox['ymin']), int(bndbox['xmax']), int(bndbox['ymax'])))
- else:
- pass
- return np.array(bndboxs)
- def iou(pred_box, target_box):
- """
- 计算候选建议和标注边界框的IoU
- :param pred_box: 大小为[4]
- :param target_box: 大小为[N, 4]
- :return: [N]
- """
- if len(target_box.shape) == 1:
- target_box = target_box[np.newaxis, :]
- xA = np.maximum(pred_box[0], target_box[:, 0])
- yA = np.maximum(pred_box[1], target_box[:, 1])
- xB = np.minimum(pred_box[2], target_box[:, 2])
- yB = np.minimum(pred_box[3], target_box[:, 3])
- # 计算交集面积
- intersection = np.maximum(0.0, xB - xA) * np.maximum(0.0, yB - yA)
- # 计算两个边界框面积
- boxAArea = (pred_box[2] - pred_box[0]) * (pred_box[3] - pred_box[1])
- boxBArea = (target_box[:, 2] - target_box[:, 0]) * (target_box[:, 3] - target_box[:, 1])
- scores = intersection / (boxAArea + boxBArea - intersection)
- return scores
- def compute_ious(rects, bndboxs):
- iou_list = list()
- for rect in rects:
- scores = iou(rect, bndboxs)
- iou_list.append(max(scores))
- return iou_list
- def save_model(model, model_save_path):
- # 保存最好的模型参数
- check_dir('./models')
- torch.save(model.state_dict(), model_save_path)
- def plot_loss(loss_list):
- x = list(range(len(loss_list)))
- fg = plt.figure()
- plt.plot(x, loss_list)
- plt.title('loss')
- plt.savefig('./loss.png')
数据集准备
数据集下载
运行项目中的pascal_voc.py脚本,这个脚本是下载数据集。
- # -*- coding: utf-8 -*-
- """
- @date: 2020/2/29 下午2:51
- @file: pascal_voc.py
- @author: zj
- @description: 加载PASCAL VOC 2007数据集
- """
- import cv2
- import numpy as np
- from torchvision.datasets import VOCDetection
- if __name__ == '__main__':
- """
- 下载PASCAL VOC数据集
- """
- dataset = VOCDetection('../../data', year='2007', image_set='trainval', download=True)
- # img, target = dataset.__getitem__(1000)
- # img = np.array(img)
- #
- # print(target)
- # print(img.shape)
- #
- # cv2.imshow('img', img)
- # cv2.waitKey(0)
从数据集中提取出car相关的数据
由于本文只针对汽车car进行目标检测,所以只需要car相关的数据。
执行pascal_voc_car.py脚本,脚本依次做了以下事:
①读取'../../data/VOCdevkit/VOC2007/ImageSets/Main/car_train.txt'文件和'../../data/VOCdevkit/VOC2007/ImageSets/Main/car_val.txt'文件
car_train.txt和car_val.txt文件的内容格式如下
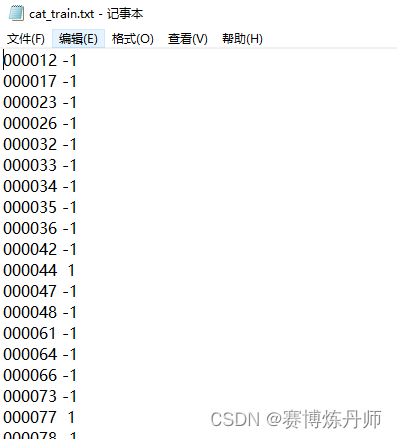
②然后将以上文件内容分别保存到'../../data/voc_car/train/car.csv'和'../../data/voc_car/val/car.csv'中
car.csv的内容格式如下
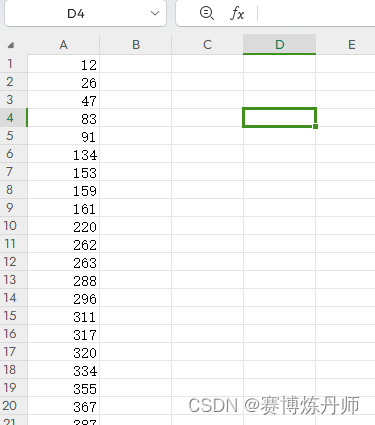
③最后根据筛选出来的car的相关数据,从'../../data/VOCdevkit/VOC2007/Annotations/'中复制相关.xml文件到'../../data/voc_car/train/Annotations/'和'../../data/voc_car/val/Annotations/',以及从'../../data/VOCdevkit/VOC2007/JPEGImages/'中复制相关.jpg文件到'../../data/voc_car/train/JPEGImages/'和'../../data/voc_car/val/JPEGImages/'
以下是pascal_voc_car.py脚本代码
- # -*- coding: utf-8 -*-
- """
- @date: 2020/2/29 下午2:43
- @file: pascal_voc_car.py
- @author: zj
- @description: 从PASCAL VOC 2007数据集中抽取类别Car。保留1/10的数目
- """
- import os
- import shutil
- import random
- import numpy as np
- import xmltodict
- from utils.util import check_dir
- suffix_xml = '.xml'
- suffix_jpeg = '.jpg'
- car_train_path = '../../data/VOCdevkit/VOC2007/ImageSets/Main/car_train.txt'
- car_val_path = '../../data/VOCdevkit/VOC2007/ImageSets/Main/car_val.txt'
- voc_annotation_dir = '../../data/VOCdevkit/VOC2007/Annotations/'
- voc_jpeg_dir = '../../data/VOCdevkit/VOC2007/JPEGImages/'
- car_root_dir = '../../data/voc_car/'
- def parse_train_val(data_path):
- """
- 提取指定类别图像
- """
- samples = []
- with open(data_path, 'r') as file:
- lines = file.readlines()
- for line in lines:
- res = line.strip().split(' ')
- if len(res) == 3 and int(res[2]) == 1:
- samples.append(res[0])
- return np.array(samples)
- def sample_train_val(samples):
- """
- 随机采样样本,减少数据集个数(留下1/10)
- """
- for name in ['train', 'val']:
- dataset = samples[name]
- length = len(dataset)
- random_samples = random.sample(range(length), int(length / 10))
- # print(random_samples)
- new_dataset = dataset[random_samples]
- samples[name] = new_dataset
- return samples
- def save_car(car_samples, data_root_dir, data_annotation_dir, data_jpeg_dir):
- """
- 保存类别Car的样本图片和标注文件
- """
- for sample_name in car_samples:
- src_annotation_path = os.path.join(voc_annotation_dir, sample_name + suffix_xml)
- dst_annotation_path = os.path.join(data_annotation_dir, sample_name + suffix_xml)
- shutil.copyfile(src_annotation_path, dst_annotation_path)
- src_jpeg_path = os.path.join(voc_jpeg_dir, sample_name + suffix_jpeg)
- dst_jpeg_path = os.path.join(data_jpeg_dir, sample_name + suffix_jpeg)
- shutil.copyfile(src_jpeg_path, dst_jpeg_path)
- csv_path = os.path.join(data_root_dir, 'car.csv')
- np.savetxt(csv_path, np.array(car_samples), fmt='%s')
- if __name__ == '__main__':
- samples = {'train': parse_train_val(car_train_path), 'val': parse_train_val(car_val_path)}
- print(samples)
- # samples = sample_train_val(samples)
- # print(samples)
- check_dir(car_root_dir)
- for name in ['train', 'val']:
- data_root_dir = os.path.join(car_root_dir, name)
- data_annotation_dir = os.path.join(data_root_dir, 'Annotations')
- data_jpeg_dir = os.path.join(data_root_dir, 'JPEGImages')
- check_dir(data_root_dir)
- check_dir(data_annotation_dir)
- check_dir(data_jpeg_dir)
- save_car(samples[name], data_root_dir, data_annotation_dir, data_jpeg_dir)
- print('done')
卷积神经网络微调模型
准备微调数据正负样本集
执行create_finetune_data.py脚本,这个脚本主要做了以下事
①把'../../data/voc_car/train/JPEGImages/'和'../../data/voc_car/val/JPEGImages/'中的.jpg文件复制到'../../data/finetune_car/train/JPEGImages/'和'../../data/finetune_car/val/JPEGImages/',然后又把'../../data/voc_car/train/car.csv'和'../../data/voc_car/val/car.csv'分别复制到'../../data/finetune_car/train/car.csv'和'../../data/finetune_car/val/car.csv'
②根据'../../data/finetune_car/train/car.csv'和'../../data/finetune_car/val/car.csv'文件内容分别读取'../../data/finetune_car/train/JPEGImages/'和'../../data/finetune_car/val/JPEGImages/'中的图片,并传入parse_annotation_jpeg方法
③parse_annotation_jpeg方法中,先获取候选框rects,然后从.xml文件中获取标注框bndboxs,接着计算候选框和标注框的IoU得到iou_list,遍历iou_list,选出IoU≥0.5的作为正样本,0

其文件内容格式如下
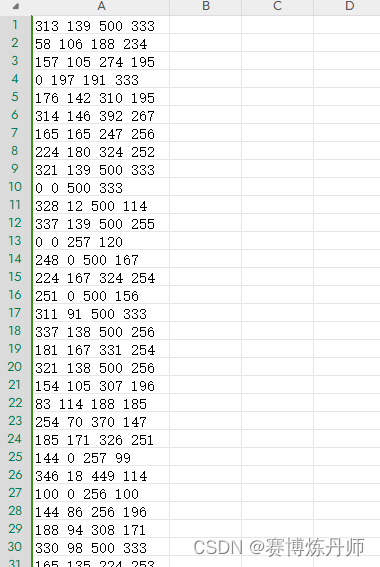
以下是create_finetune_data.py脚本代码
- # -*- coding: utf-8 -*-
- """
- @date: 2020/2/29 下午7:22
- @file: create_finetune_data.py
- @author: zj
- @description: 创建微调数据集
- """
- import time
- import shutil
- import numpy as np
- import cv2
- import os
- import selectivesearch
- from utils.util import check_dir
- from utils.util import parse_car_csv
- from utils.util import parse_xml
- from utils.util import compute_ious
- # train
- # positive num: 66517
- # negatie num: 464340
- # val
- # positive num: 64712
- # negative num: 415134
- def parse_annotation_jpeg(annotation_path, jpeg_path, gs):
- """
- 获取正负样本(注:忽略属性difficult为True的标注边界框)
- 正样本:候选建议与标注边界框IoU大于等于0.5
- 负样本:IoU大于0,小于0.5。为了进一步限制负样本数目,其大小必须大于标注框的1/5
- """
- img = cv2.imread(jpeg_path)
- selectivesearch.config(gs, img, strategy='q')
- # 计算候选建议
- rects = selectivesearch.get_rects(gs)
- # 获取标注边界框
- bndboxs = parse_xml(annotation_path)
- # 标注框大小
- maximum_bndbox_size = 0
- for bndbox in bndboxs:
- xmin, ymin, xmax, ymax = bndbox
- bndbox_size = (ymax - ymin) * (xmax - xmin)
- if bndbox_size > maximum_bndbox_size:
- maximum_bndbox_size = bndbox_size
- # 获取候选建议和标注边界框的IoU
- iou_list = compute_ious(rects, bndboxs)
- positive_list = list()
- negative_list = list()
- for i in range(len(iou_list)):
- xmin, ymin, xmax, ymax = rects[i]
- rect_size = (ymax - ymin) * (xmax - xmin)
- iou_score = iou_list[i]
- if iou_list[i] >= 0.5:
- # 正样本
- positive_list.append(rects[i])
- if 0 < iou_list[i] < 0.5 and rect_size > maximum_bndbox_size / 5.0:
- # 负样本
- negative_list.append(rects[i])
- else:
- pass
- return positive_list, negative_list
- if __name__ == '__main__':
- car_root_dir = '../../data/voc_car/'
- finetune_root_dir = '../../data/finetune_car/'
- check_dir(finetune_root_dir)
- gs = selectivesearch.get_selective_search()
- for name in ['train', 'val']:
- src_root_dir = os.path.join(car_root_dir, name)
- src_annotation_dir = os.path.join(src_root_dir, 'Annotations')
- src_jpeg_dir = os.path.join(src_root_dir, 'JPEGImages')
- dst_root_dir = os.path.join(finetune_root_dir, name)
- dst_annotation_dir = os.path.join(dst_root_dir, 'Annotations')
- dst_jpeg_dir = os.path.join(dst_root_dir, 'JPEGImages')
- check_dir(dst_root_dir)
- check_dir(dst_annotation_dir)
- check_dir(dst_jpeg_dir)
- total_num_positive = 0
- total_num_negative = 0
- samples = parse_car_csv(src_root_dir)
- # 复制csv文件
- src_csv_path = os.path.join(src_root_dir, 'car.csv')
- dst_csv_path = os.path.join(dst_root_dir, 'car.csv')
- shutil.copyfile(src_csv_path, dst_csv_path)
- for sample_name in samples:
- since = time.time()
- src_annotation_path = os.path.join(src_annotation_dir, sample_name + '.xml')
- src_jpeg_path = os.path.join(src_jpeg_dir, sample_name + '.jpg')
- # 获取正负样本
- positive_list, negative_list = parse_annotation_jpeg(src_annotation_path, src_jpeg_path, gs)
- total_num_positive += len(positive_list)
- total_num_negative += len(negative_list)
- dst_annotation_positive_path = os.path.join(dst_annotation_dir, sample_name + '_1' + '.csv')
- dst_annotation_negative_path = os.path.join(dst_annotation_dir, sample_name + '_0' + '.csv')
- dst_jpeg_path = os.path.join(dst_jpeg_dir, sample_name + '.jpg')
- # 保存图片
- shutil.copyfile(src_jpeg_path, dst_jpeg_path)
- # 保存正负样本标注
- np.savetxt(dst_annotation_positive_path, np.array(positive_list), fmt='%d', delimiter=' ')
- np.savetxt(dst_annotation_negative_path, np.array(negative_list), fmt='%d', delimiter=' ')
- time_elapsed = time.time() - since
- print('parse {}.png in {:.0f}m {:.0f}s'.format(sample_name, time_elapsed // 60, time_elapsed % 60))
- print('%s positive num: %d' % (name, total_num_positive))
- print('%s negative num: %d' % (name, total_num_negative))
- print('done')
自定义微调数据集类
custom_finetune_dataset.py,该脚本不用主动执行,在训练微调模型的时候,自然会调用到,以下只说这个脚本做了什么事
①CustomFinetuneDataset类继承自Dataset
②__init__时读取'../../data/finetune_car/train/JPEGImages/'或'../../data/finetune_car/val/JPEGImages/'文件夹中的图片,读取'../../data/finetune_car/train/Annotations/'或'../../data/finetune_car/val/Annotations/'中的正负样本集,记录正样本总数self.total_positive_num,负样本总数self.total_negative_num,正样本候选框positive_rects,负样本候选框negative_rects
③__getitem__方法传入index,如果index小于正样本总数self.total_positive_num,那么返回对应正样本的图片和标签(1),否则返回对应负样本的图片和标签(0)。
以下是custom_finetune_dataset.py脚本代码
- # -*- coding: utf-8 -*-
- """
- @date: 2020/3/3 下午7:06
- @file: custom_finetune_dataset.py
- @author: zj
- @description: 自定义微调数据类
- """
- import numpy as np
- import os
- import cv2
- from PIL import Image
- from torch.utils.data import Dataset
- from torch.utils.data import DataLoader
- import torchvision.transforms as transforms
- from utils.util import parse_car_csv
- class CustomFinetuneDataset(Dataset):
- def __init__(self, root_dir, transform=None):
- samples = parse_car_csv(root_dir)
- jpeg_images = [cv2.imread(os.path.join(root_dir, 'JPEGImages', sample_name + ".jpg"))
- for sample_name in samples]
- positive_annotations = [os.path.join(root_dir, 'Annotations', sample_name + '_1.csv')
- for sample_name in samples]
- negative_annotations = [os.path.join(root_dir, 'Annotations', sample_name + '_0.csv')
- for sample_name in samples]
- # 边界框大小
- positive_sizes = list()
- negative_sizes = list()
- # 边界框坐标
- positive_rects = list()
- negative_rects = list()
- for annotation_path in positive_annotations:
- rects = np.loadtxt(annotation_path, dtype=int, delimiter=' ')
- # 存在文件为空或者文件中仅有单行数据
- if len(rects.shape) == 1:
- # 是否为单行
- if rects.shape[0] == 4:
- positive_rects.append(rects)
- positive_sizes.append(1)
- else:
- positive_sizes.append(0)
- else:
- positive_rects.extend(rects)
- positive_sizes.append(len(rects))
- for annotation_path in negative_annotations:
- rects = np.loadtxt(annotation_path, dtype=int, delimiter=' ')
- # 和正样本规则一样
- if len(rects.shape) == 1:
- if rects.shape[0] == 4:
- negative_rects.append(rects)
- negative_sizes.append(1)
- else:
- positive_sizes.append(0)
- else:
- negative_rects.extend(rects)
- negative_sizes.append(len(rects))
- print(positive_rects)
- self.transform = transform
- self.jpeg_images = jpeg_images
- self.positive_sizes = positive_sizes
- self.negative_sizes = negative_sizes
- self.positive_rects = positive_rects
- self.negative_rects = negative_rects
- self.total_positive_num = int(np.sum(positive_sizes))
- self.total_negative_num = int(np.sum(negative_sizes))
- def __getitem__(self, index: int):
- # 定位下标所属图像
- image_id = len(self.jpeg_images) - 1
- if index < self.total_positive_num:
- # 正样本
- target = 1
- xmin, ymin, xmax, ymax = self.positive_rects[index]
- # 寻找所属图像
- for i in range(len(self.positive_sizes) - 1):
- if np.sum(self.positive_sizes[:i]) <= index < np.sum(self.positive_sizes[:(i + 1)]):
- image_id = i
- break
- image = self.jpeg_images[image_id][ymin:ymax, xmin:xmax]
- else:
- # 负样本
- target = 0
- idx = index - self.total_positive_num
- xmin, ymin, xmax, ymax = self.negative_rects[idx]
- # 寻找所属图像
- for i in range(len(self.negative_sizes) - 1):
- if np.sum(self.negative_sizes[:i]) <= idx < np.sum(self.negative_sizes[:(i + 1)]):
- image_id = i
- break
- image = self.jpeg_images[image_id][ymin:ymax, xmin:xmax]
- # print('index: %d image_id: %d target: %d image.shape: %s [xmin, ymin, xmax, ymax]: [%d, %d, %d, %d]' %
- # (index, image_id, target, str(image.shape), xmin, ymin, xmax, ymax))
- if self.transform:
- image = self.transform(image)
- return image, target
- def __len__(self) -> int:
- return self.total_positive_num + self.total_negative_num
- def get_positive_num(self) -> int:
- return self.total_positive_num
- def get_negative_num(self) -> int:
- return self.total_negative_num
- def test(idx):
- root_dir = '../../data/finetune_car/train'
- train_data_set = CustomFinetuneDataset(root_dir)
- print('positive num: %d' % train_data_set.get_positive_num())
- print('negative num: %d' % train_data_set.get_negative_num())
- print('total num: %d' % train_data_set.__len__())
- # 测试id=3/66516/66517/530856
- image, target = train_data_set.__getitem__(idx)
- print('target: %d' % target)
- image = Image.fromarray(image)
- print(image)
- print(type(image))
- # cv2.imshow('image', image)
- # cv2.waitKey(0)
- def test2():
- root_dir = '../../data/finetune_car/train'
- transform = transforms.Compose([
- transforms.ToPILImage(),
- transforms.Resize((227, 227)),
- transforms.ToTensor(),
- transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
- ])
- train_data_set = CustomFinetuneDataset(root_dir, transform=transform)
- image, target = train_data_set.__getitem__(530856)
- print('target: %d' % target)
- print('image.shape: ' + str(image.shape))
- def test3():
- root_dir = '../../data/finetune_car/train'
- transform = transforms.Compose([
- transforms.ToPILImage(),
- transforms.Resize((227, 227)),
- transforms.ToTensor(),
- transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
- ])
- train_data_set = CustomFinetuneDataset(root_dir, transform=transform)
- data_loader = DataLoader(train_data_set, batch_size=128, num_workers=8, drop_last=True)
- inputs, targets = next(data_loader.__iter__())
- print(targets)
- print(inputs.shape)
- if __name__ == '__main__':
- # test(159622)
- # test(4051)
- test3()
自定义批量采样器类
custom_batch_sampler.py,该脚本也不用主动执行,在训练微调模型的时候,自然会调用到,以下只说这个脚本做了什么事
①CustomBatchSampler类继承自(Sampler)
②__init__时通过传入的正样本总数num_positive和负样本总数num_negative得出一个列表self.idx_list,并结合传入的单次正样本数batch_positive和单次负样本数batch_negative算出可迭代次数self.num_iter
③__iter__方法中循环self.num_iter次,每次循环中会对正样本随机采集self.batch_positive次index,以及对负样本随机采集self.batch_negative次index,然后打乱存入sampler_list,最后返回一个迭代器iter(sampler)
以下是custom_batch_sampler.py脚本代码
- # -*- coding: utf-8 -*-
- """
- @date: 2020/3/3 下午7:38
- @file: custom_batch_sampler.py
- @author: zj
- @description: 自定义采样器
- """
- import numpy as np
- import random
- from torch.utils.data import Sampler
- from torch.utils.data import DataLoader
- import torchvision.transforms as transforms
- from utils.data.custom_finetune_dataset import CustomFinetuneDataset
- class CustomBatchSampler(Sampler):
- def __init__(self, num_positive, num_negative, batch_positive, batch_negative) -> None:
- """
- 2分类数据集
- 每次批量处理,其中batch_positive个正样本,batch_negative个负样本
- @param num_positive: 正样本数目
- @param num_negative: 负样本数目
- @param batch_positive: 单次正样本数
- @param batch_negative: 单次负样本数
- """
- self.num_positive = num_positive
- self.num_negative = num_negative
- self.batch_positive = batch_positive
- self.batch_negative = batch_negative
- length = num_positive + num_negative
- self.idx_list = list(range(length))
- self.batch = batch_negative + batch_positive
- self.num_iter = length // self.batch
- def __iter__(self):
- sampler_list = list()
- for i in range(self.num_iter):
- tmp = np.concatenate(
- (random.sample(self.idx_list[:self.num_positive], self.batch_positive),
- random.sample(self.idx_list[self.num_positive:], self.batch_negative))
- )
- random.shuffle(tmp)
- sampler_list.extend(tmp)
- return iter(sampler_list)
- def __len__(self) -> int:
- return self.num_iter * self.batch
- def get_num_batch(self) -> int:
- return self.num_iter
- def test():
- root_dir = '../../data/finetune_car/train'
- train_data_set = CustomFinetuneDataset(root_dir)
- train_sampler = CustomBatchSampler(train_data_set.get_positive_num(), train_data_set.get_negative_num(), 32, 96)
- print('sampler len: %d' % train_sampler.__len__())
- print('sampler batch num: %d' % train_sampler.get_num_batch())
- first_idx_list = list(train_sampler.__iter__())[:128]
- print(first_idx_list)
- # 单次批量中正样本个数
- print('positive batch: %d' % np.sum(np.array(first_idx_list) < 66517))
- def test2():
- root_dir = '../../data/finetune_car/train'
- transform = transforms.Compose([
- transforms.ToPILImage(),
- transforms.Resize((227, 227)),
- transforms.ToTensor(),
- transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
- ])
- train_data_set = CustomFinetuneDataset(root_dir, transform=transform)
- train_sampler = CustomBatchSampler(train_data_set.get_positive_num(), train_data_set.get_negative_num(), 32, 96)
- data_loader = DataLoader(train_data_set, batch_size=128, sampler=train_sampler, num_workers=8, drop_last=True)
- inputs, targets = next(data_loader.__iter__())
- print(targets)
- print(inputs.shape)
- if __name__ == '__main__':
- test()
训练微调模型
执行finetune.py脚本
①调用custom_finetune_dataset.py脚本和custom_batch_sampler.py脚本,得到训练数据data_loaders
②使用预训练模型AlexNet网络模型,修改分类器对象classifier的输出为2类(1类是car,一类是背景),然后定义损失函数为交叉熵损失函数,优化函数为SGD,学习率更新器为StepLR,然后开始训练,保存准确率最高的权重到'models/alexnet_car.pth'
以下是finetune.py脚本代码
- # -*- coding: utf-8 -*-
- """
- @date: 2020/3/1 上午9:54
- @file: finetune.py
- @author: zj
- @description:
- """
- import os
- import copy
- import time
- import torch
- import torch.nn as nn
- import torch.optim as optim
- from torch.utils.data import DataLoader
- import torchvision.transforms as transforms
- import torchvision.models as models
- from torchvision.models import AlexNet_Weights
- from utils.data.custom_finetune_dataset import CustomFinetuneDataset
- from utils.data.custom_batch_sampler import CustomBatchSampler
- from utils.util import check_dir
- def load_data(data_root_dir):
- transform = transforms.Compose([
- transforms.ToPILImage(),
- transforms.Resize((227, 227)),
- transforms.RandomHorizontalFlip(),
- transforms.ToTensor(),
- transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
- ])
- data_loaders = {}
- data_sizes = {}
- for name in ['train', 'val']:
- data_dir = os.path.join(data_root_dir, name)
- data_set = CustomFinetuneDataset(data_dir, transform=transform)
- data_sampler = CustomBatchSampler(data_set.get_positive_num(), data_set.get_negative_num(), 32, 96)
- data_loader = DataLoader(data_set, batch_size=128, sampler=data_sampler, num_workers=8, drop_last=True)
- data_loaders[name] = data_loader
- data_sizes[name] = data_sampler.__len__()
- return data_loaders, data_sizes
- def train_model(data_loaders, model, criterion, optimizer, lr_scheduler, num_epochs=25, device=None):
- since = time.time()
- best_model_weights = copy.deepcopy(model.state_dict())
- best_acc = 0.0
- for epoch in range(num_epochs):
- print('Epoch {}/{}'.format(epoch, num_epochs - 1))
- print('-' * 10)
- # Each epoch has a training and validation phase
- for phase in ['train', 'val']:
- if phase == 'train':
- model.train() # Set model to training mode
- else:
- model.eval() # Set model to evaluate mode
- running_loss = 0.0
- running_corrects = 0
- # Iterate over data.
- for inputs, labels in data_loaders[phase]:
- inputs = inputs.to(device)
- labels = labels.to(device)
- # zero the parameter gradients
- optimizer.zero_grad()
- # forward
- # track history if only in train
- with torch.set_grad_enabled(phase == 'train'):
- outputs = model(inputs)
- _, preds = torch.max(outputs, 1)
- loss = criterion(outputs, labels)
- # backward + optimize only if in training phase
- if phase == 'train':
- loss.backward()
- optimizer.step()
- # statistics
- running_loss += loss.item() * inputs.size(0)
- running_corrects += torch.sum(preds == labels.data)
- if phase == 'train':
- lr_scheduler.step()
- epoch_loss = running_loss / data_sizes[phase]
- epoch_acc = running_corrects.double() / data_sizes[phase]
- print('{} Loss: {:.4f} Acc: {:.4f}'.format(
- phase, epoch_loss, epoch_acc))
- # deep copy the model
- if phase == 'val' and epoch_acc > best_acc:
- best_acc = epoch_acc
- best_model_weights = copy.deepcopy(model.state_dict())
- print()
- time_elapsed = time.time() - since
- print('Training complete in {:.0f}m {:.0f}s'.format(
- time_elapsed // 60, time_elapsed % 60))
- print('Best val Acc: {:4f}'.format(best_acc))
- # load best model weights
- model.load_state_dict(best_model_weights)
- return model
- if __name__ == '__main__':
- device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
- data_loaders, data_sizes = load_data('./data/finetune_car')
- model = models.alexnet(weights=AlexNet_Weights.IMAGENET1K_V1)
- # print(model)
- num_features = model.classifier[6].in_features
- model.classifier[6] = nn.Linear(num_features, 2)
- # print(model)
- model = model.to(device)
- criterion = nn.CrossEntropyLoss()
- optimizer = optim.SGD(model.parameters(), lr=1e-3, momentum=0.9)
- lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
- best_model = train_model(data_loaders, model, criterion, optimizer, lr_scheduler, device=device, num_epochs=25)
- # 保存最好的模型参数
- check_dir('./models')
- torch.save(best_model.state_dict(), 'models/alexnet_car.pth')
分类器训练
准备分类器数据集
执行create_classifier_data.py脚本
①把'../../data/finetune_car/train/JPEGImages/'和'../../data/finetune_car/val/JPEGImages/'中的.jpg文件复制到'../../data/classifier_car/train/JPEGImages/'和'../../data/classifier_car/val/JPEGImages/',然后又把'../../data/finetune_car/train/car.csv'和'../../data/finetune_car/val/car.csv'分别复制到'../../data/classifier_car/train/car.csv'和'../../data/classifier_car/val/car.csv'
②根据'../../data/classifier_car/train/car.csv'和'../../data/classifier_car/val/car.csv'文件内容分别读取'../../data/classifier_car/train/JPEGImages/'和'../../data/classifier_car/val/JPEGImages/'中的图片,并传入parse_annotation_jpeg方法
③parse_annotation_jpeg方法中,先获取候选框rects,然后从.xml文件中获取标注框bndboxs,接着计算候选框和标注框的IoU得到iou_list,遍历iou_list,选出0
以下是create_classifier_data.py脚本代码
- # -*- coding: utf-8 -*-
- """
- @date: 2020/3/1 下午7:17
- @file: create_classifier_data.py
- @author: zj
- @description: 创建分类器数据集
- """
- import random
- import numpy as np
- import shutil
- import time
- import cv2
- import os
- import xmltodict
- import selectivesearch
- from utils.util import check_dir
- from utils.util import parse_car_csv
- from utils.util import parse_xml
- from utils.util import iou
- from utils.util import compute_ious
- # train
- # positive num: 625
- # negative num: 366028
- # val
- # positive num: 625
- # negative num: 321474
- def parse_annotation_jpeg(annotation_path, jpeg_path, gs):
- """
- 获取正负样本(注:忽略属性difficult为True的标注边界框)
- 正样本:标注边界框
- 负样本:IoU大于0,小于等于0.3。为了进一步限制负样本数目,其大小必须大于标注框的1/5
- """
- img = cv2.imread(jpeg_path)
- selectivesearch.config(gs, img, strategy='q')
- # 计算候选建议
- rects = selectivesearch.get_rects(gs)
- # 获取标注边界框
- bndboxs = parse_xml(annotation_path)
- # 标注框大小
- maximum_bndbox_size = 0
- for bndbox in bndboxs:
- xmin, ymin, xmax, ymax = bndbox
- bndbox_size = (ymax - ymin) * (xmax - xmin)
- if bndbox_size > maximum_bndbox_size:
- maximum_bndbox_size = bndbox_size
- # 获取候选建议和标注边界框的IoU
- iou_list = compute_ious(rects, bndboxs)
- positive_list = list()
- negative_list = list()
- for i in range(len(iou_list)):
- xmin, ymin, xmax, ymax = rects[i]
- rect_size = (ymax - ymin) * (xmax - xmin)
- iou_score = iou_list[i]
- if 0 < iou_score <= 0.3 and rect_size > maximum_bndbox_size / 5.0:
- # 负样本
- negative_list.append(rects[i])
- else:
- pass
- return bndboxs, negative_list
- if __name__ == '__main__':
- car_root_dir = '../../data/voc_car/'
- classifier_root_dir = '../../data/classifier_car/'
- check_dir(classifier_root_dir)
- gs = selectivesearch.get_selective_search()
- for name in ['train', 'val']:
- src_root_dir = os.path.join(car_root_dir, name)
- src_annotation_dir = os.path.join(src_root_dir, 'Annotations')
- src_jpeg_dir = os.path.join(src_root_dir, 'JPEGImages')
- dst_root_dir = os.path.join(classifier_root_dir, name)
- dst_annotation_dir = os.path.join(dst_root_dir, 'Annotations')
- dst_jpeg_dir = os.path.join(dst_root_dir, 'JPEGImages')
- check_dir(dst_root_dir)
- check_dir(dst_annotation_dir)
- check_dir(dst_jpeg_dir)
- total_num_positive = 0
- total_num_negative = 0
- samples = parse_car_csv(src_root_dir)
- # 复制csv文件
- src_csv_path = os.path.join(src_root_dir, 'car.csv')
- dst_csv_path = os.path.join(dst_root_dir, 'car.csv')
- shutil.copyfile(src_csv_path, dst_csv_path)
- for sample_name in samples:
- since = time.time()
- src_annotation_path = os.path.join(src_annotation_dir, sample_name + '.xml')
- src_jpeg_path = os.path.join(src_jpeg_dir, sample_name + '.jpg')
- # 获取正负样本
- positive_list, negative_list = parse_annotation_jpeg(src_annotation_path, src_jpeg_path, gs)
- total_num_positive += len(positive_list)
- total_num_negative += len(negative_list)
- dst_annotation_positive_path = os.path.join(dst_annotation_dir, sample_name + '_1' + '.csv')
- dst_annotation_negative_path = os.path.join(dst_annotation_dir, sample_name + '_0' + '.csv')
- dst_jpeg_path = os.path.join(dst_jpeg_dir, sample_name + '.jpg')
- # 保存图片
- shutil.copyfile(src_jpeg_path, dst_jpeg_path)
- # 保存正负样本标注
- np.savetxt(dst_annotation_positive_path, np.array(positive_list), fmt='%d', delimiter=' ')
- np.savetxt(dst_annotation_negative_path, np.array(negative_list), fmt='%d', delimiter=' ')
- time_elapsed = time.time() - since
- print('parse {}.png in {:.0f}m {:.0f}s'.format(sample_name, time_elapsed // 60, time_elapsed % 60))
- print('%s positive num: %d' % (name, total_num_positive))
- print('%s negative num: %d' % (name, total_num_negative))
- print('done')
自定义分类器数据集类
custom_classifier_dataset.py,该脚本不用主动执行,在训练分类器模型的时候,自然会调用到,以下只说这个脚本做了什么事
①CustomClassifierDataset类继承自Dataset
②__init__时读取'../../data/classifier_car/train/JPEGImages/'或'../../data/classifier_car/val/JPEGImages/'文件夹中的图片,读取'../../data/classifier_car/train/Annotations/'或'../../data/classifier_car/val/Annotations/'中的正负样本集,记录正样本列表self.positive_list,负样本总数self.negative_list,正样本候选框positive_rects,负样本候选框negative_rects
③__getitem__方法传入index,如果index小于正样本总数len(self.positive_list),那么返回对应正样本的图片和标签(1),否则返回对应负样本的图片和标签(0)。
以下是custom_classifier_dataset.py脚本代码
- # -*- coding: utf-8 -*-
- """
- @date: 2020/3/4 下午4:00
- @file: custom_classifier_dataset.py
- @author: zj
- @description: 分类器数据集类,可进行正负样本集替换,适用于hard negative mining操作
- """
- import numpy as np
- import os
- import cv2
- from PIL import Image
- from torch.utils.data import Dataset
- from torch.utils.data import DataLoader
- import torchvision.transforms as transforms
- from utils.util import parse_car_csv
- class CustomClassifierDataset(Dataset):
- def __init__(self, root_dir, transform=None):
- samples = parse_car_csv(root_dir)
- jpeg_images = list()
- positive_list = list()
- negative_list = list()
- for idx in range(len(samples)):
- sample_name = samples[idx]
- jpeg_images.append(cv2.imread(os.path.join(root_dir, 'JPEGImages', sample_name + ".jpg")))
- positive_annotation_path = os.path.join(root_dir, 'Annotations', sample_name + '_1.csv')
- positive_annotations = np.loadtxt(positive_annotation_path, dtype=int, delimiter=' ')
- # 考虑csv文件为空或者仅包含单个标注框
- if len(positive_annotations.shape) == 1:
- # 单个标注框坐标
- if positive_annotations.shape[0] == 4:
- positive_dict = dict()
- positive_dict['rect'] = positive_annotations
- positive_dict['image_id'] = idx
- # positive_dict['image_name'] = sample_name
- positive_list.append(positive_dict)
- else:
- for positive_annotation in positive_annotations:
- positive_dict = dict()
- positive_dict['rect'] = positive_annotation
- positive_dict['image_id'] = idx
- # positive_dict['image_name'] = sample_name
- positive_list.append(positive_dict)
- negative_annotation_path = os.path.join(root_dir, 'Annotations', sample_name + '_0.csv')
- negative_annotations = np.loadtxt(negative_annotation_path, dtype=int, delimiter=' ')
- # 考虑csv文件为空或者仅包含单个标注框
- if len(negative_annotations.shape) == 1:
- # 单个标注框坐标
- if negative_annotations.shape[0] == 4:
- negative_dict = dict()
- negative_dict['rect'] = negative_annotations
- negative_dict['image_id'] = idx
- # negative_dict['image_name'] = sample_name
- negative_list.append(negative_dict)
- else:
- for negative_annotation in negative_annotations:
- negative_dict = dict()
- negative_dict['rect'] = negative_annotation
- negative_dict['image_id'] = idx
- # negative_dict['image_name'] = sample_name
- negative_list.append(negative_dict)
- self.transform = transform
- self.jpeg_images = jpeg_images
- self.positive_list = positive_list
- self.negative_list = negative_list
- def __getitem__(self, index: int):
- # 定位下标所属图像
- if index < len(self.positive_list):
- # 正样本
- target = 1
- positive_dict = self.positive_list[index]
- xmin, ymin, xmax, ymax = positive_dict['rect']
- image_id = positive_dict['image_id']
- image = self.jpeg_images[image_id][ymin:ymax, xmin:xmax]
- cache_dict = positive_dict
- else:
- # 负样本
- target = 0
- idx = index - len(self.positive_list)
- negative_dict = self.negative_list[idx]
- xmin, ymin, xmax, ymax = negative_dict['rect']
- image_id = negative_dict['image_id']
- image = self.jpeg_images[image_id][ymin:ymax, xmin:xmax]
- cache_dict = negative_dict
- # print('index: %d image_id: %d target: %d image.shape: %s [xmin, ymin, xmax, ymax]: [%d, %d, %d, %d]' %
- # (index, image_id, target, str(image.shape), xmin, ymin, xmax, ymax))
- if self.transform:
- image = self.transform(image)
- return image, target, cache_dict
- def __len__(self) -> int:
- return len(self.positive_list) + len(self.negative_list)
- def get_transform(self):
- return self.transform
- def get_jpeg_images(self) -> list:
- return self.jpeg_images
- def get_positive_num(self) -> int:
- return len(self.positive_list)
- def get_negative_num(self) -> int:
- return len(self.negative_list)
- def get_positives(self) -> list:
- return self.positive_list
- def get_negatives(self) -> list:
- return self.negative_list
- # 用于hard negative mining
- # 替换负样本
- def set_negative_list(self, negative_list):
- self.negative_list = negative_list
- def test(idx):
- root_dir = '../../data/classifier_car/val'
- train_data_set = CustomClassifierDataset(root_dir)
- print('positive num: %d' % train_data_set.get_positive_num())
- print('negative num: %d' % train_data_set.get_negative_num())
- print('total num: %d' % train_data_set.__len__())
- # 测试id=3/66516/66517/530856
- image, target, cache_dict = train_data_set.__getitem__(idx)
- print('target: %d' % target)
- print('dict: ' + str(cache_dict))
- image = Image.fromarray(image)
- print(image)
- print(type(image))
- # cv2.imshow('image', image)
- # cv2.waitKey(0)
- def test2():
- root_dir = '../../data/classifier_car/train'
- transform = transforms.Compose([
- transforms.ToPILImage(),
- transforms.Resize((227, 227)),
- transforms.ToTensor(),
- transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
- ])
- train_data_set = CustomClassifierDataset(root_dir, transform=transform)
- image, target, cache_dict = train_data_set.__getitem__(230856)
- print('target: %d' % target)
- print('dict: ' + str(cache_dict))
- print('image.shape: ' + str(image.shape))
- def test3():
- root_dir = '../../data/classifier_car/train'
- transform = transforms.Compose([
- transforms.ToPILImage(),
- transforms.Resize((227, 227)),
- transforms.ToTensor(),
- transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
- ])
- train_data_set = CustomClassifierDataset(root_dir, transform=transform)
- data_loader = DataLoader(train_data_set, batch_size=128, num_workers=8, drop_last=True)
- inputs, targets, cache_dicts = next(data_loader.__iter__())
- print(targets)
- print(inputs.shape)
- if __name__ == '__main__':
- # test(159622)
- # test(4051)
- test(24768)
- # test2()
- # test3()
自定义批量采样器类
同"卷积神经网络微调模型"中的"自定义批量采样器类",在训练分类器模型的时候,自然会调用到
训练分类器
执行linear_svm.py脚本
①调用custom_classifier_dataset.py脚本和custom_batch_sampler.py脚本,得到训练数据data_loaders
②使用AlexNet网络模型,修改分类器对象classifier的输出为2类(1类是car,一类是背景),加载之前微调训练的权重alexnet_car.pth,并设置参数冻结,然后再添加一个全连接层作为svm分类器,定义损失函数为折页损失函数,优化函数为SGD,学习率更新器为StepLR,然后开始训练,保存准确率最高的权重到'models/best_linear_svm_alexnet_car.pth'
以下是linear_svm.py脚本代码
- # -*- coding: utf-8 -*-
- """
- @date: 2020/3/1 下午2:38
- @file: linear_svm.py
- @author: zj
- @description:
- """
- import time
- import copy
- import os
- import random
- import numpy as np
- import torch
- import torch.nn as nn
- import torch.optim as optim
- from torch.utils.data import DataLoader
- import torchvision.transforms as transforms
- from torchvision.models import alexnet
- from utils.data.custom_classifier_dataset import CustomClassifierDataset
- from utils.data.custom_hard_negative_mining_dataset import CustomHardNegativeMiningDataset
- from utils.data.custom_batch_sampler import CustomBatchSampler
- from utils.util import check_dir
- from utils.util import save_model
- batch_positive = 32
- batch_negative = 96
- batch_total = 128
- def load_data(data_root_dir):
- transform = transforms.Compose([
- transforms.ToPILImage(),
- transforms.Resize((227, 227)),
- transforms.RandomHorizontalFlip(),
- transforms.ToTensor(),
- transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
- ])
- data_loaders = {}
- data_sizes = {}
- remain_negative_list = list()
- for name in ['train', 'val']:
- data_dir = os.path.join(data_root_dir, name)
- data_set = CustomClassifierDataset(data_dir, transform=transform)
- if name == 'train':
- """
- 使用hard negative mining方式
- 初始正负样本比例为1:1。由于正样本数远小于负样本,所以以正样本数为基准,在负样本集中随机提取同样数目负样本作为初始负样本集
- """
- positive_list = data_set.get_positives()
- negative_list = data_set.get_negatives()
- init_negative_idxs = random.sample(range(len(negative_list)), len(positive_list))
- init_negative_list = [negative_list[idx] for idx in range(len(negative_list)) if idx in init_negative_idxs]
- remain_negative_list = [negative_list[idx] for idx in range(len(negative_list))
- if idx not in init_negative_idxs]
- data_set.set_negative_list(init_negative_list)
- data_loaders['remain'] = remain_negative_list
- sampler = CustomBatchSampler(data_set.get_positive_num(), data_set.get_negative_num(),
- batch_positive, batch_negative)
- data_loader = DataLoader(data_set, batch_size=batch_total, sampler=sampler, num_workers=8, drop_last=True)
- data_loaders[name] = data_loader
- data_sizes[name] = len(sampler)
- return data_loaders, data_sizes
- def hinge_loss(outputs, labels):
- """
- 折页损失计算
- :param outputs: 大小为(N, num_classes)
- :param labels: 大小为(N)
- :return: 损失值
- """
- num_labels = len(labels)
- corrects = outputs[range(num_labels), labels].unsqueeze(0).T
- # 最大间隔
- margin = 1.0
- margins = outputs - corrects + margin
- loss = torch.sum(torch.max(margins, 1)[0]) / len(labels)
- # # 正则化强度
- # reg = 1e-3
- # loss += reg * torch.sum(weight ** 2)
- return loss
- def add_hard_negatives(hard_negative_list, negative_list, add_negative_list):
- for item in hard_negative_list:
- if len(add_negative_list) == 0:
- # 第一次添加负样本
- negative_list.append(item)
- add_negative_list.append(list(item['rect']))
- if list(item['rect']) not in add_negative_list:
- negative_list.append(item)
- add_negative_list.append(list(item['rect']))
- def get_hard_negatives(preds, cache_dicts):
- fp_mask = preds == 1
- tn_mask = preds == 0
- fp_rects = cache_dicts['rect'][fp_mask].numpy()
- fp_image_ids = cache_dicts['image_id'][fp_mask].numpy()
- tn_rects = cache_dicts['rect'][tn_mask].numpy()
- tn_image_ids = cache_dicts['image_id'][tn_mask].numpy()
- hard_negative_list = [{'rect': fp_rects[idx], 'image_id': fp_image_ids[idx]} for idx in range(len(fp_rects))]
- easy_negatie_list = [{'rect': tn_rects[idx], 'image_id': tn_image_ids[idx]} for idx in range(len(tn_rects))]
- return hard_negative_list, easy_negatie_list
- def train_model(data_loaders, model, criterion, optimizer, lr_scheduler, num_epochs=25, device=None):
- since = time.time()
- best_model_weights = copy.deepcopy(model.state_dict())
- best_acc = 0.0
- for epoch in range(num_epochs):
- print('Epoch {}/{}'.format(epoch, num_epochs - 1))
- print('-' * 10)
- # Each epoch has a training and validation phase
- for phase in ['train', 'val']:
- if phase == 'train':
- model.train() # Set model to training mode
- else:
- model.eval() # Set model to evaluate mode
- running_loss = 0.0
- running_corrects = 0
- # 输出正负样本数
- data_set = data_loaders[phase].dataset
- print('{} - positive_num: {} - negative_num: {} - data size: {}'.format(
- phase, data_set.get_positive_num(), data_set.get_negative_num(), data_sizes[phase]))
- # Iterate over data.
- for inputs, labels, cache_dicts in data_loaders[phase]:
- inputs = inputs.to(device)
- labels = labels.to(device)
- # zero the parameter gradients
- optimizer.zero_grad()
- # forward
- # track history if only in train
- with torch.set_grad_enabled(phase == 'train'):
- outputs = model(inputs)
- # print(outputs.shape)
- _, preds = torch.max(outputs, 1)
- loss = criterion(outputs, labels)
- # backward + optimize only if in training phase
- if phase == 'train':
- loss.backward()
- optimizer.step()
- # statistics
- running_loss += loss.item() * inputs.size(0)
- running_corrects += torch.sum(preds == labels.data)
- if phase == 'train':
- lr_scheduler.step()
- epoch_loss = running_loss / data_sizes[phase]
- epoch_acc = running_corrects.double() / data_sizes[phase]
- print('{} Loss: {:.4f} Acc: {:.4f}'.format(
- phase, epoch_loss, epoch_acc))
- # deep copy the model
- if phase == 'val' and epoch_acc > best_acc:
- best_acc = epoch_acc
- best_model_weights = copy.deepcopy(model.state_dict())
- # 每一轮训练完成后,测试剩余负样本集,进行hard negative mining
- train_dataset = data_loaders['train'].dataset
- remain_negative_list = data_loaders['remain']
- jpeg_images = train_dataset.get_jpeg_images()
- transform = train_dataset.get_transform()
- with torch.set_grad_enabled(False):
- remain_dataset = CustomHardNegativeMiningDataset(remain_negative_list, jpeg_images, transform=transform)
- remain_data_loader = DataLoader(remain_dataset, batch_size=batch_total, num_workers=8, drop_last=True)
- # 获取训练数据集的负样本集
- negative_list = train_dataset.get_negatives()
- # 记录后续增加的负样本
- add_negative_list = data_loaders.get('add_negative', [])
- running_corrects = 0
- # Iterate over data.
- for inputs, labels, cache_dicts in remain_data_loader:
- inputs = inputs.to(device)
- labels = labels.to(device)
- # zero the parameter gradients
- optimizer.zero_grad()
- outputs = model(inputs)
- # print(outputs.shape)
- _, preds = torch.max(outputs, 1)
- running_corrects += torch.sum(preds == labels.data)
- hard_negative_list, easy_neagtive_list = get_hard_negatives(preds.cpu().numpy(), cache_dicts)
- add_hard_negatives(hard_negative_list, negative_list, add_negative_list)
- remain_acc = running_corrects.double() / len(remain_negative_list)
- print('remain negative size: {}, acc: {:.4f}'.format(len(remain_negative_list), remain_acc))
- # 训练完成后,重置负样本,进行hard negatives mining
- train_dataset.set_negative_list(negative_list)
- tmp_sampler = CustomBatchSampler(train_dataset.get_positive_num(), train_dataset.get_negative_num(),
- batch_positive, batch_negative)
- data_loaders['train'] = DataLoader(train_dataset, batch_size=batch_total, sampler=tmp_sampler,
- num_workers=8, drop_last=True)
- data_loaders['add_negative'] = add_negative_list
- # 重置数据集大小
- data_sizes['train'] = len(tmp_sampler)
- # 每训练一轮就保存
- save_model(model, 'models/linear_svm_alexnet_car_%d.pth' % epoch)
- time_elapsed = time.time() - since
- print('Training complete in {:.0f}m {:.0f}s'.format(
- time_elapsed // 60, time_elapsed % 60))
- print('Best val Acc: {:4f}'.format(best_acc))
- # load best model weights
- model.load_state_dict(best_model_weights)
- return model
- if __name__ == '__main__':
- device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
- # device = 'cpu'
- data_loaders, data_sizes = load_data('./data/classifier_car')
- # 加载CNN模型
- model_path = './models/alexnet_car.pth'
- model = alexnet()
- num_classes = 2
- num_features = model.classifier[6].in_features
- model.classifier[6] = nn.Linear(num_features, num_classes)
- model.load_state_dict(torch.load(model_path))
- model.eval()
- # 固定特征提取
- for param in model.parameters():
- param.requires_grad = False
- # 创建SVM分类器
- model.classifier[6] = nn.Linear(num_features, num_classes)
- # print(model)
- model = model.to(device)
- criterion = hinge_loss
- # 由于初始训练集数量很少,所以降低学习率
- optimizer = optim.SGD(model.parameters(), lr=1e-4, momentum=0.9)
- # 共训练10轮,每隔4论减少一次学习率
- lr_schduler = optim.lr_scheduler.StepLR(optimizer, step_size=4, gamma=0.1)
- best_model = train_model(data_loaders, model, criterion, optimizer, lr_schduler, num_epochs=10, device=device)
- # 保存最好的模型参数
- save_model(best_model, 'models/best_linear_svm_alexnet_car.pth')
边界框回归训练
准备边界框回归数据集
执行create_bbox_regression_data.py脚本
①读取'../../data/voc_car/train/Annotations/'中的标注框信息存入bndboxs和'../../data/finetune_car/train/Annotations/'中的正样本数据存入positive_bndboxes,计算标注框和正样本数据的IoU,针对IoU>0.6的正样本数据,保存其到'../../data/bbox_regression/positive/'中,并保存对应的图片到'../../data/bbox_regression/JPEGImages/'中,保存对应的标注框信息到'../../data/bbox_regression/bndboxs/'中,保存对应的图片名到'../../data/bbox_regression/car.csv'中
以下是create_bbox_regression_data.py脚本代码
- # -*- coding: utf-8 -*-
- """
- @date: 2020/4/3 下午7:19
- @file: create_bbox_regression_data.py
- @author: zj
- @description: 创建边界框回归数据集
- """
- import os
- import shutil
- import numpy as np
- import utils.util as util
- # 正样本边界框数目:37222
- if __name__ == '__main__':
- """
- 从voc_car/train目录中提取标注边界框坐标
- 从finetune_car/train目录中提取训练集正样本坐标(IoU>=0.5),进一步提取IoU>0.6的边界框
- 数据集保存在bbox_car目录下
- """
- voc_car_train_dir = '../../data/voc_car/train'
- # ground truth
- gt_annotation_dir = os.path.join(voc_car_train_dir, 'Annotations')
- jpeg_dir = os.path.join(voc_car_train_dir, 'JPEGImages')
- classifier_car_train_dir = '../../data/finetune_car/train'
- # positive
- positive_annotation_dir = os.path.join(classifier_car_train_dir, 'Annotations')
- dst_root_dir = '../../data/bbox_regression/'
- dst_jpeg_dir = os.path.join(dst_root_dir, 'JPEGImages')
- dst_bndbox_dir = os.path.join(dst_root_dir, 'bndboxs')
- dst_positive_dir = os.path.join(dst_root_dir, 'positive')
- util.check_dir(dst_root_dir)
- util.check_dir(dst_jpeg_dir)
- util.check_dir(dst_bndbox_dir)
- util.check_dir(dst_positive_dir)
- samples = util.parse_car_csv(voc_car_train_dir)
- res_samples = list()
- total_positive_num = 0
- for sample_name in samples:
- # 提取正样本边界框坐标(IoU>=0.5)
- positive_annotation_path = os.path.join(positive_annotation_dir, sample_name + '_1.csv')
- positive_bndboxes = np.loadtxt(positive_annotation_path, dtype=int, delimiter=' ')
- # 提取标注边界框
- gt_annotation_path = os.path.join(gt_annotation_dir, sample_name + '.xml')
- bndboxs = util.parse_xml(gt_annotation_path)
- # 计算符合条件(IoU>0.6)的候选建议
- positive_list = list()
- if len(positive_bndboxes.shape) == 1 and len(positive_bndboxes) != 0:
- scores = util.iou(positive_bndboxes, bndboxs)
- if np.max(scores) > 0.6:
- positive_list.append(positive_bndboxes)
- elif len(positive_bndboxes.shape) == 2:
- for positive_bndboxe in positive_bndboxes:
- scores = util.iou(positive_bndboxe, bndboxs)
- if np.max(scores) > 0.6:
- positive_list.append(positive_bndboxe)
- else:
- pass
- # 如果存在正样本边界框(IoU>0.6),那么保存相应的图片以及标注边界框
- if len(positive_list) > 0:
- # 保存图片
- jpeg_path = os.path.join(jpeg_dir, sample_name + ".jpg")
- dst_jpeg_path = os.path.join(dst_jpeg_dir, sample_name + ".jpg")
- shutil.copyfile(jpeg_path, dst_jpeg_path)
- # 保存标注边界框
- dst_bndbox_path = os.path.join(dst_bndbox_dir, sample_name + ".csv")
- np.savetxt(dst_bndbox_path, bndboxs, fmt='%s', delimiter=' ')
- # 保存正样本边界框
- dst_positive_path = os.path.join(dst_positive_dir, sample_name + ".csv")
- np.savetxt(dst_positive_path, np.array(positive_list), fmt='%s', delimiter=' ')
- total_positive_num += len(positive_list)
- res_samples.append(sample_name)
- print('save {} done'.format(sample_name))
- else:
- print('-------- {} 不符合条件'.format(sample_name))
- dst_csv_path = os.path.join(dst_root_dir, 'car.csv')
- np.savetxt(dst_csv_path, res_samples, fmt='%s', delimiter=' ')
- print('total positive num: {}'.format(total_positive_num))
- print('done')
自定义边界框回归训练数据集类
custom_bbox_regression_dataset.py,该脚本不用主动执行,在训练分类器模型的时候,自然会调用到,以下只说这个脚本做了什么事
①BBoxRegressionDataset类继承自Dataset
②__init__时读取'../../data/bbox_regression/JPEGImages/'文件夹中的图片,存入self.jpeg_list,又读取'../../data/bbox_regression/bndboxs/'中的标注框信息和'../../data/bbox_regression/positive/'中的正样本数据并都存入self.box_list
③__getitem__方法计算并返回图片和相对坐标差
以下是custom_bbox_regression_dataset.py脚本代码
- # -*- coding: utf-8 -*-
- """
- @date: 2020/4/3 下午8:07
- @file: custom_bbox_regression_dataset.py
- @author: zj
- @description:
- """
- import os
- import cv2
- import numpy as np
- import torch
- import torchvision.transforms as transforms
- from torch.utils.data import Dataset
- from torch.utils.data import DataLoader
- import utils.util as util
- class BBoxRegressionDataset(Dataset):
- def __init__(self, root_dir, transform=None):
- super(BBoxRegressionDataset, self).__init__()
- self.transform = transform
- samples = util.parse_car_csv(root_dir)
- jpeg_list = list()
- # 保存{'image_id': ?, 'positive': ?, 'bndbox': ?}
- box_list = list()
- for i in range(len(samples)):
- sample_name = samples[i]
- jpeg_path = os.path.join(root_dir, 'JPEGImages', sample_name + '.jpg')
- bndbox_path = os.path.join(root_dir, 'bndboxs', sample_name + '.csv')
- positive_path = os.path.join(root_dir, 'positive', sample_name + '.csv')
- jpeg_list.append(cv2.imread(jpeg_path))
- bndboxes = np.loadtxt(bndbox_path, dtype=int, delimiter=' ')
- positives = np.loadtxt(positive_path, dtype=int, delimiter=' ')
- if len(positives.shape) == 1:
- bndbox = self.get_bndbox(bndboxes, positives)
- box_list.append({'image_id': i, 'positive': positives, 'bndbox': bndbox})
- else:
- for positive in positives:
- bndbox = self.get_bndbox(bndboxes, positive)
- box_list.append({'image_id': i, 'positive': positive, 'bndbox': bndbox})
- self.jpeg_list = jpeg_list
- self.box_list = box_list
- def __getitem__(self, index: int):
- assert index < self.__len__(), '数据集大小为%d,当前输入下标为%d' % (self.__len__(), index)
- box_dict = self.box_list[index]
- image_id = box_dict['image_id']
- positive = box_dict['positive']
- bndbox = box_dict['bndbox']
- # 获取预测图像
- jpeg_img = self.jpeg_list[image_id]
- xmin, ymin, xmax, ymax = positive
- image = jpeg_img[ymin:ymax, xmin:xmax]
- if self.transform:
- image = self.transform(image)
- # 计算P/G的x/y/w/h
- target = dict()
- p_w = xmax - xmin
- p_h = ymax - ymin
- p_x = xmin + p_w / 2
- p_y = ymin + p_h / 2
- xmin, ymin, xmax, ymax = bndbox
- g_w = xmax - xmin
- g_h = ymax - ymin
- g_x = xmin + g_w / 2
- g_y = ymin + g_h / 2
- # 计算t
- t_x = (g_x - p_x) / p_w
- t_y = (g_y - p_y) / p_h
- t_w = np.log(g_w / p_w)
- t_h = np.log(g_h / p_h)
- return image, np.array((t_x, t_y, t_w, t_h))
- def __len__(self):
- return len(self.box_list)
- def get_bndbox(self, bndboxes, positive):
- """
- 返回和positive的IoU最大的标注边界框
- :param bndboxes: 大小为[N, 4]或者[4]
- :param positive: 大小为[4]
- :return: [4]
- """
- if len(bndboxes.shape) == 1:
- # 只有一个标注边界框,直接返回即可
- return bndboxes
- else:
- scores = util.iou(positive, bndboxes)
- return bndboxes[np.argmax(scores)]
- def test():
- """
- 创建数据集类实例
- """
- transform = transforms.Compose([
- transforms.ToPILImage(),
- transforms.Resize((227, 227)),
- transforms.RandomHorizontalFlip(),
- transforms.ToTensor(),
- transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
- ])
- data_root_dir = '../../data/bbox_regression'
- data_set = BBoxRegressionDataset(data_root_dir, transform=transform)
- print(data_set.__len__())
- image, target = data_set.__getitem__(10)
- print(image.shape)
- print(target)
- print(target.dtype)
- def test2():
- """
- 测试DataLoader使用
- """
- transform = transforms.Compose([
- transforms.ToPILImage(),
- transforms.Resize((227, 227)),
- transforms.RandomHorizontalFlip(),
- transforms.ToTensor(),
- transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
- ])
- data_root_dir = '../../data/bbox_regression'
- data_set = BBoxRegressionDataset(data_root_dir, transform=transform)
- data_loader = DataLoader(data_set, batch_size=128, shuffle=True, num_workers=8)
- items = next(data_loader.__iter__())
- datas, targets = items
- print(datas.shape)
- print(targets.shape)
- print(targets.dtype)
- if __name__ == '__main__':
- test()
- # test2()
训练边界框回归
执行bbox_regression.py脚本
①调用custom_bbox_regression_dataset.py脚本,得到训练数据data_loader
②使用AlexNet网络模型,修改分类器对象classifier的输出为2类(1类是car,一类是背景),加载权重best_linear_svm_alexnet_car.pth,并设置参数冻结,然后再添加一个线性层作为全连接层,定义损失函数为均方误差损失函数,优化函数为SGD,学习率更新器为StepLR,然后开始训练,保存模型到'models/bbox_regression_%d.pth'
以下是bbox_regression.py脚本代码
- # -*- coding: utf-8 -*-
- """
- @date: 2020/4/3 下午6:55
- @file: bbox_regression.py
- @author: zj
- @description: 边界框回归训练
- """
- import os
- import copy
- import time
- import torch
- import torch.nn as nn
- import torch.optim as optim
- from torch.utils.data import DataLoader
- import torchvision.transforms as transforms
- from torchvision.models import AlexNet
- from utils.data.custom_bbox_regression_dataset import BBoxRegressionDataset
- import utils.util as util
- def load_data(data_root_dir):
- transform = transforms.Compose([
- transforms.ToPILImage(),
- transforms.Resize((227, 227)),
- transforms.RandomHorizontalFlip(),
- transforms.ToTensor(),
- transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
- ])
- data_set = BBoxRegressionDataset(data_root_dir, transform=transform)
- data_loader = DataLoader(data_set, batch_size=128, shuffle=True, num_workers=8)
- return data_loader
- def train_model(data_loader, feature_model, model, criterion, optimizer, lr_scheduler, num_epochs=25, device=None):
- since = time.time()
- model.train() # Set model to training mode
- loss_list = list()
- for epoch in range(num_epochs):
- print('Epoch {}/{}'.format(epoch, num_epochs - 1))
- print('-' * 10)
- running_loss = 0.0
- # Iterate over data.
- for inputs, targets in data_loader:
- inputs = inputs.to(device)
- targets = targets.float().to(device)
- features = feature_model.features(inputs)
- features = torch.flatten(features, 1)
- # zero the parameter gradients
- optimizer.zero_grad()
- # forward
- outputs = model(features)
- loss = criterion(outputs, targets)
- loss.backward()
- optimizer.step()
- # statistics
- running_loss += loss.item() * inputs.size(0)
- lr_scheduler.step()
- epoch_loss = running_loss / data_loader.dataset.__len__()
- loss_list.append(epoch_loss)
- print('{} Loss: {:.4f}'.format(epoch, epoch_loss))
- # 每训练一轮就保存
- util.save_model(model, './models/bbox_regression_%d.pth' % epoch)
- print()
- time_elapsed = time.time() - since
- print('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))
- return loss_list
- def get_model(device=None):
- # 加载CNN模型
- model = AlexNet(num_classes=2)
- model.load_state_dict(torch.load('./models/best_linear_svm_alexnet_car.pth'))
- model.eval()
- # 取消梯度追踪
- for param in model.parameters():
- param.requires_grad = False
- if device:
- model = model.to(device)
- return model
- if __name__ == '__main__':
- data_loader = load_data('./data/bbox_regression')
- device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
- feature_model = get_model(device)
- # AlexNet最后一个池化层计算得到256*6*6输出
- in_features = 256 * 6 * 6
- out_features = 4
- model = nn.Linear(in_features, out_features)
- model.to(device)
- criterion = nn.MSELoss()
- optimizer = optim.Adam(model.parameters(), lr=1e-4, weight_decay=1e-4)
- lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)
- loss_list = train_model(data_loader, feature_model, model, criterion, optimizer, lr_scheduler, device=device,
- num_epochs=12)
- util.plot_loss(loss_list)
汽车car目标检测器实现
读取图片,先检测图片中是否有汽车,然后使用非极大值抑制(NMS)算法消除冗余边界框,最后输出目标检测结果,如下图

工程下载
-
相关阅读:
ADB 命令大全
[读论文]深度孵化 Deep Incubation: Training Large Models by Divide-and-Conquering
Vue中的计算属性和侦听器有什么区别?
Java后端__校园兼职项目重构版
几道面试题记录20231023
备战金九银十,Java 研发面试题整理 PDF,走到哪刷
ESP32网络开发实例-Web服务器发送事件
SpringBoot激活profiles的几种方式
深度学习 精选笔记(4)线性神经网络-交叉熵回归与Softmax 回归
Netty服务端启动的整体流程-基于源码4.1.96Final分析
- 原文地址:https://blog.csdn.net/Victor_Li_/article/details/134274482