-
RabbitMQ
目录
一、简介
官网地址:RabbitMQ: easy to use, flexible messaging and streaming — RabbitMQ
 https://www.rabbitmq.com/
https://www.rabbitmq.com/- MQ为Message Queue,消息队列是应用程序和应用程序之间的通信方法。
- RabbitMQ是一个开源的,在AMQP基础上完整的,可复用的企业消息系统。
- 支持主流的操作系统:Linux、Windows、MacOX等。
- 多种开发语言支持:Java、Python、Ruby、。NET、PHP、C/C++、node.js等。
二、什么是MQ
消息队列(Message Queue,简称MQ),从字面意思上看,本质是个队列,FIFO先入先出,只不过队列中存放的内容是message而已。
其主要用途:不同进程Process/线程Thread之间通信。目前市场上主流的MQ有三款:
- RabbitMQ
- RocketMQ
- Kafka
在互联网架构中,MQ 是一种非常常见的上下游“逻辑解耦+物理解耦”的消息通信服务,用于上下游传递消息。使用了 MQ 之后,消息发送上游只需要依赖 MQ,不用依赖其他服务。
三、为什么需要MQ
常见的MQ消息中间件有很多,例如
ActiveMQ、RabbitMQ、Kafka、RocketMQ等等。那么为什么我们要使用它呢?因为它能很好的帮我们解决一些复杂特殊的场景:1、高并发的流量削峰
假设某订单系统每秒最多能处理一万次订单,也就是最多承受的10000qps,这个处理能力应付正常时段的下单时绰绰有余,正常时段我们下单一秒后就能返回结果。但是在高峰期,如果有两万次下单操作系统是处理不了的,只能限制订单超过一万后不允许用户下单。使用消息队列做缓冲,我们可以取消这个限制,把一秒内下的订单分散成一段时间来处理,这时有些用户可能在下单十几秒后才能收到下单成功的操作,但是比不能下单的体验要好。
2、应用解耦
以电商应用为例,应用中有订单系统、库存系统、物流系统、支付系统。用户创建订单后,如果耦合调用库存系统、物流系统、支付系统,任何一个子系统出了故障,都会造成下单操作异常。当转变成基于消息队列的方式后,系统间调用的问题会减少很多,比如物流系统因为发生故障,需要几分钟来修复。在这几分钟的时间里,物流系统要处理的内存被缓存在消息队列中,用户的下单操作可以正常完成。当物流系统恢复后,继续处理订单信息即可,中单用户感受不到物流系统的故障,提升系统的可用性。
3、异步处理
有些服务间调用是异步的,例如 A 调用 B,B 需要花费很长时间执行,但是 A 需要知道 B 什么时候可以执行完,以前一般有两种方式,A 过一段时间去调用 B 的查询 api 查询。或者 A 提供一个 callback api, B 执行完之后调用 api 通知 A 服务。这两种方式都不是很优雅,使用消息队列,可以很方便解决这个问题,A 调用 B 服务后,只需要监听 B 处理完成的消息,当 B 处理完成后,会发送一条消息给 MQ,MQ 会将此消息转发给 A 服务。这样 A 服务既不用循环调用 B 的查询 api,也不用提供 callback api。同样B 服务也不用做这些操作。A 服务还能及时的得到异步处理成功的消息。
4、分布式事务
以订单服务为例,传统的方式为单体应用,支付、修改订单状态、创建物流订单三个步骤集成在一个服务中,因此这三个步骤可以放在一个jdbc事务中,要么全成功,要么全失败。而在微服务的环境下,会将三个步骤拆分成三个服务,例如:支付服务,订单服务,物流服务。三者各司其职,相互之间进行服务间调用,但这会带来分布式事务的问题,因为三个步骤操作的不是同一个数据库,导致无法使用jdbc事务管理以达到一致性。而 MQ 能够很好的帮我们解决分布式事务的问题,有一个比较容易理解的方案,就是二次提交。基于MQ的特点,MQ作为二次提交的中间节点,负责存储请求数据,在失败的情况可以进行多次尝试,或者基于MQ中的队列数据进行回滚操作,是一个既能保证性能,又能保证业务一致性的方案。
5、数据分发
MQ 具有发布订阅机制,不仅仅是简单的上游和下游一对一的关系,还有支持一对多或者广播的模式,并且都可以根据规则选择分发的对象。这样一份上游数据,众多下游系统中,可以根据规则选择是否接收这些数据,能达到很高的拓展性。
四、看待MQ的角度
虽然市面上的MQ数量众多、种类繁杂,但MQ其本质上就是用来暂时存放消息的一种中间件,其实从三个角度去关注MQ即可抓住MQ的核心:
- 消息可靠性
- 消息模型
- 吞吐量
1、消息可靠性
消息可靠性,即消息会不会丢失?围绕防止消息丢失做了哪些工作?
2、消息模型
消息模型,即支持以什么样的模式去消费消息?点对点?广播?发布订阅?其消息模型丰富度如何?
3、吞吐量
MQ作为用来减轻系统压力的中间件,其自身势必会经常面对很大的流量,吞吐量如何自然是要考虑的。
五、Rabbit介绍
RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件)。RabbitMQ服务器是用Erlang语言编写的,而集群和故障转移是构建在开放电信平台框架上的。所有主要的编程语言均有与代理接口通讯的客户端库。
5.1、概念
RabbitMQ是一套开源(MPL)的消息队列服务软件,是由 LShift 提供的一个 Advanced Message Queuing Protocol (AMQP) 的开源实现,由以高性能、健壮以及可伸缩性出名的Erlang写成。
支持的操作系统:
- Linux
- WindowsNT-11
- Windows server2003到2016
- macOS
- Solaris
- FreeBSD
- TRU64
- VxWorks
支持的编程语言:
- Python
- Java
- Ruby
- PHP
- C#
- JavaScript
- Go
- Elixir
- Objective-C
- Swift
5.2、开发语言
Erlang——面向并发的编程语言
Erlang是一种通用的面向并发的编程语言,它由瑞典电信设备提供商爱立信所辖的CS-Lab开发,目的是创造一种可以应对大规模并发活动的编程语言和运行环境。Erlang问世于1987年,经过十年的发展,于1998年发布开源版本。Erlang是运行于虚拟机的解释性语言,但是也包含有乌普萨拉大学高性能Erlang计划(HiPE)开发的本地代码编译器,自R11B-4版本开始,Erlang也开始支持脚本式解释器。在编程范型上,Erlang属于多重范型编程语言,涵盖函数式、并发式及分布式。顺序执行的Erlang是一个及早求值,单次赋值和动态类型的函数式编程语言。
Erlang是一个结构化,动态类型编程语言,内建并行计算支持。最初是由爱立信专门为通信应用设计的,比如控制交换机或者变换协议等,因此非常适 合于构建分布式,实时软并行计算系统。使用Erlang编写出的应用运行时通常由成千上万个轻量级进程组成,并通过消息传递相互通讯。进程间上下文切换对于Erlang来说仅仅 只是一两个环节,比起C程序的线程切换要高效得多得多了。
使用Erlang来编写分布式应用要简单的多,因为它的分布式机制是透明的:对于程序来说并不知道自己是在分布式运行。Erlang运行时环境是一个虚拟机,有点像Java虚拟机,这样代码一经编译,同样可以随处运行。它的运行时系统甚至允许代码在不被中断 的情况下更新。另外如果需要更高效的话,字节代码也可以编译成本地代码运行。
5.3、AMQP协议
5.3.1简介
AMQP,即Advanced Message Queuing Protocol,一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件不同产品,不同的开发语言等条件的限制。Erlang中的实现有RabbitMQ等。
AMQP所覆盖的内容包含了网络协议以及服务端服务
- 一套被称作”高级消息队列协议模型(AMQ Model)“的消息能力定义。该模型涵盖了Broker服务中用于路由和存储消息的组件,以及把这些组件连在一起的规则。
- 一个网络层协议AMQP。能够让客户端程序与实现了AMQ Model的服务端进行通信。
AMQP像是一个把东西连在一起的语言,而不是一个系统。其设计目标是:让服务端可通过协议编程。
AMQP协议是一个二进制协议,具有一些现代特性:多通道(multi-channel),可协商(negotiated),异步、安全、便携、语言中立、高效的。其协议主要分成两层:
- 功能层(Functional Layer):定义了一系列的命令
- 传输层(Transport Layer):携带了从应用 → 服务端的方法,用于处理多路复用、分帧、编码、心跳、data-representation、错误处理。
这样分层之后,可以把传输层替换为其它传输协议,而不需要修改功能层。同样,也可以使用同样的传输层,基于此实现不同的上层协议。可能RabbitMQ也是因为类似的原因,能够比较容易的支持MQTT、STOMP等协议的吧。
5.3.2基本概念
- Server:接收客户端的连接,实现AMQP实体服务。
- Connection:连接,应用程序与Server的网络连接,TCP连接。
- Channel:信道,消息读写等操作在信道中进行。客户端可以建立多个信道,每个信道代表一个会话任务。
- Message:消息,应用程序和服务器之间传送的数据,消息可以非常简单,也可以很复杂。由Properties和Body组成。Properties为外包装,可以对消息进行修饰,比如消息的优先级、延迟等高级特性;Body就是消息体内容。
- Virtual Host:虚拟主机,用于逻辑隔离。一个虚拟主机里面可以有若干个Exchange和Queue,同一个虚拟主机里面不能有相同名称的Exchange或Queue。
- Exchange:交换器,接收消息,按照路由规则将消息路由到一个或者多个队列。如果路由不到,或者返回给生产者,或者直接丢弃。RabbitMQ常用的交换器常用类型有direct、topic、fanout、headers四种,后面详细介绍。
- Binding:绑定,交换器和消息队列之间的虚拟连接,绑定中可以包含一个或者多个RoutingKey。
- RoutingKey:路由键,生产者将消息发送给交换器的时候,会发送一个RoutingKey,用来指定路由规则,这样交换器就知道把消息发送到哪个队列。路由键通常为一个“.”分割的字符串,例如“com.rabbitmq”。
- Queue:消息队列,用来保存消息,供消费者消费。
5.3.3、AMQ Model
主要包含了三个主要组件
- exchange(交换器):从Publisher程序中收取消息,并把这些消息根据一些规则路由到消息队列(Message Queue)中
- message queue(消息队列):存储消息。直到消息被安全的投递给了消费者。
- binging定义了message queue 和exchange之间的关系,提供了消息路由的规则。
5.3.4、AMQ Model架构
可以把AMQP的架构理解为一个邮件服务:
- 一个AMQP消息类似于一封邮件信息
- 消息队列类似于一个邮箱(Mailbox)
- 消费者类似一个邮件客户端,能够拉取和删除邮件。
- 交换器类似一个MTA(邮件服务器)。检查邮件,基于邮件里的路由信息、路由表,来决定如何把邮件发送到一个或多个邮箱里。
- Routing Key类似于邮件中的 To,
Cc:,Bcc:的地址。不包含服务端信息。 - 每一个交换器实例,类似于各个MTA进程。用于处理不同子域名的邮件,或者特定类型的邮件。
- Binding类似于MTA中的路由表。
在AMQP里,生产者直接把消息发到服务端,服务端再把这些消息路由到邮箱中。消费者直接从邮箱里取消息。但在AMQP之前的很多中间件中,发布者是把消息直接发到对应的邮箱里(类似于存储发布队列),或者直接发到邮件列表里(类似topic订阅)。
这里的主要区别在于,用户可以控制消息队列和交换器的绑定规则,而不是依赖中间件自身的代码。这样就可以做很多有趣的事情。比如定义一个这样的规则:把所有包含这样和这样Header的消息,都复制一份到这个消息队列中。“
5.4、生命周期
5.4.1、消息的生命周期
- 消息由生产者产生。生产者把内容放到消息里,并设置一些属性以及消息的路由。然后生产者把消息发给服务端。
- 服务端收到消息,交换器(大部分情况)把消息路由到若干个该服务器上的消息队列中。如果这个消息找不到路由,则会丢弃或者退回给生产者(生产者可自行决定)。
- 一条消息可以存在于许多消息队列中。 服务器可以通过复制消息,引用计数等方式来实现。这不会影响互操作性。 但是,将一条消息路由到多个消息队列时,每个消息队列上的消息都是相同的。 没有可以区分各种副本的唯一标识符。
- 消息到达消息队列。消息队列会立即尝试通过AMQP将其传递给消费者。 如果做不到,消息队列将消息存储(按生产者的要求存储在内存中或磁盘上),并等待消费者准备就绪。 如果没有消费者,则消息队列可以通过AMQP将消息返回给生产者(同样,如果生产者要求这样做)。
- 当消息队列可以将消息传递给消费者时,它将消息从其内部缓冲区中删除。 可以立即删除,也可以在使用者确认其已成功处理消息之后删除(ack)。 由消费者选择“确认”消息的方式和时间。消费者也可以拒绝消息(否定确认)。
- 生产者发消息与消费者确认,被分组成一个事务。当一个应用同时扮演多个角色时:发消息,发ack,commit或者回滚事务。消息从服务端投递给消费者这个过程不是事务的。消费者对消息进行确认就够了。
在这个过程中,生产者只能把所有消息发到一个单点(交换器),而不能直接把消息发到某个消息队列(message-queue)中。
5.4.2、交换器(exchange)的生命周期
每个AMQP服务端都会自己创建一些交换器,这些不能被销毁。AMQP程序也可以创建其自己的交换器。AMQP并不使用create这个方法,而是使用declare方法来表示:如果不存在,则创建,存在了则继续。程序可以创建交换器用于私有使用,并在任务完成后销毁它们。虽然AMQP提供了销毁交换器的方法,但一般来讲程序不需要销户它。
5.4.3、队列(queue)的生命周期
队列分两种
- 持久化消息队列:由很多消费者共享。当消费者都退出后,队列依然存在,并会继续收集消息。
- 临时消息队列:临时消息队列对于消费者是私有和绑定的。当消费者断开连接,则消息队列被删除。
5.5、绑定(Bindings)
绑定是交换器和消息队列之间的关系,告诉交换器如何路有消息。
- //绑定命令的伪代码
- Queue.Bind <queue> To <exchange> WHERE <condition>
使用案例
构造一个共享队列
- Queue.Declare queue=app.svc01 // 声明一个叫做 app.svc01 的队列
- // Comsumer
- Basic.Consume queue=app.svc01 // 消费者消费该队列
- // Producer
- Basic.Publish routing-key=app.svc01 // 生产者发布消息。routingKey为队列名称
构造一个私有回复队列
一般来讲,回复队列是私有的、临时的、由服务端命名、只有一个消费者。(没有直接使用AMQP协议中的例子,而是使用了RabbitMQ的例子)
- Queue.Declare queue=rpc_queue // 调用的队列
- // Server
- Basic.Consume queue=rpc_queue
- // Client
- Queue.Declare queue=<empty> exclusive=TRUE
- S:Queue.Declare-Ok queue=amq.gen-X... // AMQP服务端告诉队列名称
- Basic.Publish queue=rpc_queue reply_to=amq_gen-X... // 客户端向服务端发送请求
- // Server
- handleMessage()
- // 服务端处理好消息后,向消息列的reply-to字段中的队列发送响应
- Basic.Publish exchange=<empty> routing-key={message.replay_to}
构造一个发布-订阅队列
在传统的中间件中,术语subscription含糊不清。至少包含两个概念:匹配消息的条件集,和一个临时队列用于存放匹配的消息。AMQP把这两部分拆成:binding和message queue。在AMQP中,并没有一个实体叫做subscription。
AMQP的发布订阅模型为:
- 给一个消费者保留消息(一些场景下是多个消费者)
- 从多个源收集消息,比如匹配Topic、消息的字段、或者内容等方式
订阅队列与命名队列或回复队列之间的关键区别在于,订阅队列名称与路由目的无关,并且路由是根据抽象的匹配条件完成的,而不是路由键字段的一对一匹配。
- // Consumer
- Queue.Declare queue=<empty> exclusive=TRUE
- // 这里是使用服务端下发的队列名称,并设置为独占。
- // 也可以使用约定的队列名称。这样就相当于把发布-订阅模型与共享队列组合使用了
- S:Queue.Declare-Ok queue=tmp.2
- Queue.Bind queue=tmp.2 TO exchange=amq.topic WHERE routing-key=*.orange.*
- Basic.Consume queue=tmp.2
- // Producer
- Basic.Publish exchange=amq.topic routing-key=quick.orange.rabbit
5.6、AMQP命令架构
中间件复杂度很高,所以设计协议时的挑战是要驯服其复杂性。AMQP采用方法是基于类来建立传统API模型。类中包含方法,并定义了方法明确应该做什么。
AMQP中有两种不同的方式进行对话:
- 同步请求-响应。一个节点发送请求,另一个阶段发送响应。适用于性能不重要的方法。发送同步请求时,该节点直到收到回复后,才能发送下一个请求
- 异步通知。一个节点发送数据,但是不期待回复。一般用于性能很重要的地方。异步请求会尽可能快的发送消息,不等待确认。只在需要的时候在更上层(比如消费者层)实现限流等功能。AMQP中可以没有确认,要么成功,要么就会收到关闭Channel或者连接的异常。如果需要明确的追踪成功或者失败,那么应该使用事务。
5.6.1、AMQP中的类
5.6.1.1、Connection类
AMQP是一个长连接协议。Connection被设计为长期使用的,可以携带多个Channel。Connection的生命周期是:
- 客户端打开到服务端的TCP/IP连接,发送协议头。这是客户端发送的数据里,唯一不能被解析为方法的数据。
- 服务端返回其协议版本、属性(比如支持的安全机制列表)。 the Start method
- 客户端选择安全机制 Start-Ok
- 服务端开始认证过程, 它使用SASL的质询-响应模型(challenge-response model)。它向客户端发送一个质询 Secure
- 客户端向服务端发送一个认证响应Secure-Ok。比如,如果使用 plain 认证机制,则响应会包含登录名和密码
- 客户端重复质询Secure或转到协商步骤,发送一系列参数,如最大帧大小 Tune
- 客户端接受,或者调低这些参数 Tune-Ok
- 客户端正式打开连接,并选择一个Vhost Open
- 服务端确认VHost有效 Open-Ok
- 客户端可以按照预期使用连接
- 当一个节点打算结束连接 Close
- 另一个节点需要结束握手 Open-Ok
- 服务端和客户端关闭Socket连接。
如果在发送或者收到 Open 或者 Open-Ok 之前,某一个节点发现了一个错误,则必须直接关闭Socket,且不发送任何数据。
5.6.1.2、Channel类
AMQP是一个多通道协议。Channel提供了一种方式,在比较重的TCP/IP连接上建立多个轻量级的连接。这会让协议对防火墙更加友好,因为端口使用是可预知的。它也意味着很容易支持流量调整和其他QoS特性。
Channels相互是独立的,可以同步执行不同的功能。可用带宽会在当前活动之间共享。
这里期望也鼓励多线程客户端程序应该使用每个线程一个channel 的模型。不过,一个客户端在一个或多个AMQP服务端上打开多个连接也是可以的。
Channel的生命周期为:
- 客户端打开一个新通道 Open
- 服务端确认新通道准备就绪 Open-Ok
- 客户端和服务端按预期来使用通道.
- 一个节点关闭了通道 Close
- 另一个节点对通道关闭进行握手 Close-Ok
5.6.1.3、Exchange类
Exchange类能够让应用操作服务端的交换器。这个类能够让程序自己设置路由,而不是通过某些配置。不过大部分程序并不需要这个级别的复杂度,过去的中间件也不只支持这个语义。
Exchange的生命周期为:
- 客户端让服务端确保该 exchange 存在 Declare。客户端可以细化为:“如果交换器不存在则进行创建” 或 “如果交换器不存在,警告我,不需要创建”
- 客户端向 Exchange 发消息
- 客户端也可以选择删掉 Exchange Delete
5.6.1.4、Queue类
该类用于让程序管理服务端上的消息队列。几乎所有的消费者应用都是基本步骤,至少要验证使用的消息队列是否存在。
一个持久化消息队列的生命周期非常简单
- 客户端断言这个消息队列存在 Declare(设置 passive 参数)
- 服务端确认消息队列存在 Declare-Ok
- 客户端消息队列中读消息
一个临时消息队列的生命周期会更有趣些:
- 客户端创建消息队列 Declare (不提供队列名称,服务器会分配一个名称)。服务端确认 Declare-Ok
- 客户端在消息队列上启动一个消费者
- 客户端取消消费,可以是显示取消,也可以是通过关闭通道或者连接连接隐式取消的
- 当最后一个消费者从消息队列中消失的时候,在过了礼貌性超时后,服务端会删除消息队列
AMQP实现了Topic订阅的分发模型。这可以让订阅在合作的订阅者间进行负载均衡。涉及到额外的绑定阶段的生命周期:
- 客户端创建一个队列Declare,服务端确认 Declare-Ok
- 客户端绑定消息队列到一个topic exchange上Bind,服务端确认Bind-Ok
- 客户端像之前一样使用消息队列。
5.6.1.5、Basic类
Basic实现本规范中描述的消息功能。支持如下语义:
- 从客户端→服务端发消息。异步Publish
- 开始或者停止消费Consume,Cancel
- 从服务端到客户端发消息。异步Deliver,Return
- 确认消息Ack,Reject
- 同步的从消息队列中读取消息Get
5.6.1.6、事务类
AMQP支持两种类型的事务:
- 自动事务。每个发布的消息和应答都处理为独立事务.
- 服务端本地事务:服务器会缓存发布的消息和应答,并会根据需要由client来提交它们.
Transaction 类(“tx”) 使应用程序可访问第二种类型,即服务器事务。这个类的语义是:
- 应用程序要求服务端事务,在需要的每个channel里Select
- 应用程序做一些工作Publish,Ack
- 应用程序提交或回滚工作Commit,Roll-back
- 应用程序正常工作,循环往复。
事务包含发布消息和ack,不包含分发。所以,回滚并不能重入队列或者重新分发任何消息。客户端有权在事务中确认这些消息。
5.7、功能说明
AMQP的功能描述,一定程度上也是RabbitMQ的功能描述,不过RabbitMQ基于AMQP做了一些扩展
5.7.1、消息和内容
消息会携带一些属性,以及具体内容(二进制数据)
消息是可被持久化的。持久化消息是可以安全的存在硬盘上的,即使发生了验证的网络错误、服务端崩溃溢出等情况,也可以确保被投递。
消息可以有优先级。同一个队列中,高优先级的消息会比低优先级的消息先被发送。当消息需要被丢弃时(比如服务端内存不足等),将会优先丢弃低优先级消息
服务端一定不能修改消息的内容。但服务端可能会在消息头上添加一些属性,但一定不会移除或者修改已经存在的属性。
5.7.2、虚拟主机(VHost)
虚拟主机是服务端的一个数据分区。在多租户使用是,可以方便进行管理。
虚拟主机有自己的命名空间、交换器、消息队列等等。所有连接,只可能和一个虚拟主机建立。
5.7.3、交换器(Exchange)
交换器是一个虚拟主机内的消息路由Agent。用于处理消息的路由信息(一般是Routing-Key),然后将其发送到消息队列或者内部服务中。交换器可能是持久化的、临时的、自动删除的。交换器把消息路由到消息队列时可以是并行的。这会创建一个消息的多个实例。
RabbitMQ常用的交换器类型有direct、topic、fanout、headers四种:
- Direct Exchange:见文知意,直连交换机意思是此交换机需要绑定一个队列,要求该消息与一个特定的路由键完全匹配。简单点说就是一对一的,点对点的发送。
- Fanout Exchange:这种类型的交换机需要将队列绑定到交换机上。一个发送到交换机的消息都会被转发到与该交换机绑定的所有队列上。很像子网广播,每台子网内的主机都获得了一份复制的消息。简单点说就是发布订阅。
- Topic Exchange:直接翻译的话叫做主题交换机,如果从用法上面翻译可能叫通配符交换机会更加贴切。这种交换机是使用通配符去匹配,路由到对应的队列。通配符有两种:"*" 、 "#"。需要注意的是通配符前面必须要加上"."符号。
- *符号:有且只匹配一个词。比如 a.*可以匹配到"a.b"、"a.c",但是匹配不了"a.b.c"。
- #符号:匹配一个或多个词。比如"rabbit.#"既可以匹配到"rabbit.a.b"、"rabbit.a",也可以匹配到"rabbit.a.b.c"。
- Headers Exchange:这种交换机用的相对没这么多。它跟上面三种有点区别,它的路由不是用routingKey进行 路由匹配,而是在匹配请求头中所带的键值进行路由。创建队列需要设置绑定的头部信息,有两种模式:全部匹配和部分匹配。交换机会根据生产者发送过来的头部信息携带的键值去匹配队列绑定的键值,路由到对应的队列。
六、特性
- 可伸缩性:集群服务
- 消息持久化:从内存持久化消息到硬盘,再从硬盘加载到内存
6.1、高级特性
6.1.1、过期时间
Time To Live,也就是生存时间,是一条消息在队列中的最大存活时间,单位是毫秒,下面看看RabbitMQ过期时间特性:
- RabbitMQ可以对消息和队列设置TTL。
- RabbitMQ支持设置消息的过期时间,在消息发送的时候可以进行指定,每条消息的过期时间可以不同。
- RabbitMQ支持设置队列的过期时间,从消息入队列开始计算,直到超过了队列的超时时间配置,那么消息会变成死信,自动清除。
- 如果两种方式一起使用,则过期时间以两者中较小的那个数值为准。
- 当然也可以不设置TTL,不设置表示消息不会过期;如果设置为0,则表示除非此时可以直接将消息投递到消费者,否则该消息将被立即丢弃。
6.1.2、消息确认
为了保证消息从队列可靠地到达消费者,RabbitMQ提供了消息确认机制。消费者订阅队列的时候,可以指定autoAck参数,当autoAck为true的时候,RabbitMQ采用自动确认模式,RabbitMQ自动把发送出去的消息设置为确认,然后从内存或者硬盘中删除,而不管消费者是否真正消费到了这些消息。当autoAck为false的时候,RabbitMQ会等待消费者回复的确认信号,收到确认信号之后才从内存或者磁盘中删除消息。
消息确认机制是RabbitMQ消息可靠性投递的基础,只要设置autoAck参数为false,消费者就有足够的时间处理消息,不用担心处理消息的过程中消费者进程挂掉后消息丢失的问题。
6.1.3、持久化
消息的可靠性是RabbitMQ的一大特色,那么RabbitMQ是如何保证消息可靠性的呢?答案就是消息持久化。持久化可以防止在异常情况下丢失数据。RabbitMQ的持久化分为三个部分:交换器持久化、队列持久化和消息的持久化。
交换器持久化可以通过在声明队列时将durable参数设置为true。如果交换器不设置持久化,那么在RabbitMQ服务重启之后,相关的交换器元数据会丢失,不过消息不会丢失,只是不能将消息发送到这个交换器了。
队列的持久化能保证其本身的元数据不会因异常情况而丢失,但是不能保证内部所存储的消息不会丢失。要确保消息不会丢失,需要将其设置为持久化。队列的持久化可以通过在声明队列时将durable参数设置为true。
设置了队列和消息的持久化,当RabbitMQ服务重启之后,消息依然存在。如果只设置队列持久化或者消息持久化,重启之后消息都会消失。
当然,也可以将所有的消息都设置为持久化,但是这样做会影响RabbitMQ的性能,因为磁盘的写入速度比内存的写入要慢得多。对于可靠性不是那么高的消息可以不采用持久化处理以提高整体的吞吐量。鱼和熊掌不可兼得,关键在于选择和取舍。在实际中,需要根据实际情况在可靠性和吞吐量之间做一个权衡。
6.1.4、死信队列
当消息在一个队列中变成死信之后,他能被重新发送到另一个交换器中,这个交换器成为死信交换器,与该交换器绑定的队列称为死信队列。消息变成死信有下面几种情况:
- 消息被拒绝。
- 消息过期
- 队列达到最大长度
DLX也是一个正常的交换器,和一般的交换器没有区别,他能在任何的队列上面被指定,实际上就是设置某个队列的属性。当这个队列中有死信的时候,RabbitMQ会自动将这个消息重新发送到设置的交换器上,进而被路由到另一个队列,我们可以监听这个队列中消息做相应的处理。
死信队列有什么用?当发生异常的时候,消息不能够被消费者正常消费,被加入到了死信队列中。后续的程序可以根据死信队列中的内容分析当时发生的异常,进而改善和优化系统。
6.1.5、延迟队列
一般的队列,消息一旦进入队列就会被消费者立即消费。延迟队列就是进入该队列的消息会被消费者延迟消费,延迟队列中存储的对象是的延迟消息,“延迟消息”是指当消息被发送以后,等待特定的时间后,消费者才能拿到这个消息进行消费。
延迟队列用于需要延迟工作的场景。最常见的使用场景:淘宝或者天猫我们都使用过,用户在下单之后通常有30分钟的时间进行支付,如果这30分钟之内没有支付成功,那么订单就会自动取消。除了延迟消费,延迟队列的典型应用场景还有延迟重试。比如消费者从队列里面消费消息失败了,可以延迟一段时间以后进行重试。
6.1.6、特性分析
这里才是内容的重点,不仅需要知道Rabbit的特性,还需要知道支持这些特性的原因:
- 消息路由(支持):RabbitMQ可以通过不同的交换器支持不同种类的消息路由;
- 消息有序(不支持):当消费消息时,如果消费失败,消息会被放回队列,然后重新消费,这样会导致消息无序;
- 消息时序(非常好):通过延时队列,可以指定消息的延时时间,过期时间TTL等;
- 容错处理(非常好):通过交付重试和死信交换器(DLX)来处理消息处理故障;
- 伸缩(一般):伸缩其实没有非常智能,因为即使伸缩了,master queue还是只有一个,负载还是只有这一个master queue去抗,所以我理解RabbitMQ的伸缩很弱(个人理解)。
- 持久化(不太好):没有消费的消息,可以支持持久化,这个是为了保证机器宕机时消息可以恢复,但是消费过的消息,就会被马上删除,因为RabbitMQ设计时,就不是为了去存储历史数据的。
- 消息回溯(支持):因为消息不支持永久保存,所以自然就不支持回溯。
- 高吞吐(中等):因为所有的请求的执行,最后都是在master queue,它的这个设计,导致单机性能达不到十万级的标准。
七、RabbitMQ的特点
- 遵从AMQP协议
- 丰富的消息模型
- 消息可靠性高但是吞吐量不高
7.1、遵从AMQP
AMQP简单来说就是规定好了MQ的各个抽象组件,RabbitMQ则是一款完全严格按照AMQP来实现的开源MQ,使得很好被开源框架所集成,比如Spring AMQP专门就是用来操作AMQP架构的中间件的,因此RabbitMQ可以被Spring Boot很方便的集成。
7.2、丰富的消息模型
RabbitMQ也是三大MQ里提供的消息模型最丰富的一种MQ。
- 简单模式
- Work queues工作队列模式
- Publish/Subscribe发布和订阅模式
- Routing路由模式
- Topics通配符模式
- RPC远程调用模式
1、简单模式
简单队列,consumer和producer通过队列直连。
2、工作队列模式
工作队列(work queue),让多个消费者去消费同一个消息队列中的消息,支持轮询分发(默认)、公平分发两种分发模式。
3、发布和订阅模式
订阅模式(fanout),也叫广播模式,见名知意,其特点是将消息广播出去。通过交换机将生产者生产的消息分发到多个队列中去,从而支持生产者生产的一个消息被多个消费者消费。
4、路由模式
路由模式(direct),在订阅模式支持一条消息被多个消费者消费的特性上增加了分类投递的特性,通过交换机,支持消息以类别(routing key)的方式投送到不同的消息队列中去。
5、通配符模式
在路由模式以类别进行消息投送的基础上增加了对通配符的支持,这样就可以使用通配符将多个类别聚合成一个主题。
6、RPC模式
远程调用不太算MQ
7.3、消息可靠性高但是吞吐量不高
RabbitMQRabbitMQ 提供了多种机制来确保消息的可靠性,包括持久化、消息确认、发布确认等。这些机制确保消息不会丢失,并且能够在各种情况下处理消息传递失败。但是由于存在这些用于保证消息可靠性的机制,RabbitMQ的吞吐量在三大中间件中是最低的。
八、性能对比
ActiveMQ Kafka RocketMQ RabbitMQ 开发语言 Java Scala Java Erlang 客户端SDK Java,.NET,C++等 Java,Scala等 Java,C++,Go Java,.NET,PHP,Python,JavaScript,Ruby,Go等 吞吐量 万级,同rabbitmq差不多 10万级(17.3w/s),高吞吐,一般配合大数据类的系统来进行实时数据计算、日志采集等场景 10万级(11.6w/s),支持高吞吐 万级(5.95w/s)为保证消息可靠性在吞吐量上做了取舍 topic数量对吞吐量的影响 topic从几十到几百个时候,吞吐量会大幅下降,在同等机器下,Kafka尽量保证topic数量不要过多,如果要支撑大规模的topic,需要增加更多的机器资源 topic可以达到几百/几千的级别,吞吐量会有较小幅度的下降,这是RocketMQ的一大优势,在同等机器下,可以支撑大量的topic 时效性 毫秒级 毫秒级 毫秒级 微秒级,RabbitMQ的一大特点,延迟最低 可用性 高,主从架构 非常高,kafka是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 非常高,分布式架构 高,基于主从架构实现高可用性 消息可靠性 有较低的概率丢失数据 经过参数优化配置可做到0丢失 经过参数优化配置,可以做到0丢失 通过消息确认,持久化等手段保持消息可靠 性能稳定性 队列/分区多时性能不稳定,明显下降。消息堆积时性能稳定 队列较多,消息堆积时性能稳定 消息堆积时,性能不稳定、明显下降 协议和规范 Push model,support,OpenWire,STOMP,AMQP,MQTT,JMS Pull model,support TCP Pull model,support TCP,JMS,OpenMessaging Push model,support,AMQP,XMPP,SMTP,STOMP 定时/延时推送 支持的 不支持 支持的 不支持 有序消息 独立消费者或独立队列可以保证消息有序 保证独立分区内消息的顺序,但是一台Broker宕机后,就会产生消息乱序 保证独立分区内消息的顺序 批量发送 不支持 支持,带有异步生产者 严格确保消息有序,并可以优雅的拓展 不支持 广播消息 支持的 不支持 支持的 支持的 消息过滤 支持的 支持,可以使用KafkaStreams过滤消息 支持基于SQL92的属性过滤器表达式 不支持 消息重发 不支持 支持的 支持的 支持的 消息存储 使用JDBC和高性能日志(例如leveIDB,kahaDB)支持非常快速的持久化 高性能文件存储 高性能和低延迟的文件存储 高性能文件存储 消息回溯 支持的 支持按照偏移量来回溯消息 支持按照时间来回溯消息 不支持 消息优先 支持的 不支持 不支持 支持的 讯息轨道追踪 不支持 不支持 支持的 支持的 配置 默认配置为低级别,用户需要优化配置参数 Kafka使用键值对格式进行配置。这些值可以从文件或以编程方式提供 开箱即用,用户只需要注意一些配置 使用键值对格式进行配置。这些值可以从文件或以编程方式提供 管理和操作工具 支持的 支持,使用终端命令公开核心指标 支持web和终端命令可显示核心指标 支持web和终端命令可显示核心指标 高可用性和故障转移 支持,取决与存储,如果使用kahadb,则需要ZooKeeper服务器 支持,需要ZooKeeper服务器 支持主从模式,无需其他套件 支持主从模式,无需其他套件 成熟度 成熟 成熟日志领域 比较成熟 成熟 特点 功能齐全,被大量开源项目使用 用于大数据领域实时计算、日记采集等topic和消费端都较少的弱业务性场景 各个环节分布扩展设计,主从HA,支持上万个队列多种消费模式,性能很好 由于Erlang语言的并发能力,性能很好 持久化 内存、文件、数据库 文件、磁盘 磁盘文件 内存、文件 事务 支持 支持 支持 支持 负载均衡 支持 支持 支持 支持 九、Rabbitmq部署
9.1、下载rabbitmq安装包
下载地址:Index of rabbitmq-server-local (huaweicloud.com)

查看Rabbitmq对应的Erlang版本
查看版本对应地址:RabbitMQ Erlang Version Requirements — RabbitMQ

9.2、下载Erlang语言
Rabbitmq是用Erlang语言开发的,所以需要提供Erlang环境
下载地址:rabbitmq/erlang - Packages · packagecloud

9.3、下载Socat
下载地址:https://pkgs.org/download/socat
socat支持多协议,用于协议处理,端口转发,rabbitmq依赖于socat,因此在安装rabbitmq前要安装socat。
安装依赖
因为Rabbitmq依赖于Erlang和socat,所以要先安装Erlang和socat在装rabbitmq
安装要点
Erlang与RabbitMQ,安装路径都应不含空格符。
Erlang使用了环境变量HOMEDRIVE与HOMEPATH来访问配置文件.erlang.cookie,应注意这两个环境变量的有效性。需要设定环境变量ERLANG_HOME,并把%ERLANG_HOME%\bin加入到全局路径中。
RabbitMQ使用本地computer name作为服务器的地址,因此需要注意其有效性,或者直接解析为127.0.0.1
可能需要在本地网络防火墙打开相应的端口。
9.4、安装

9.5、启动

关闭防护墙
- systemctl stop firewalld
- setenforce 0
9.6、RabbitMQ WEB管理界面及授权操作
9.6.1、安装web管理界面
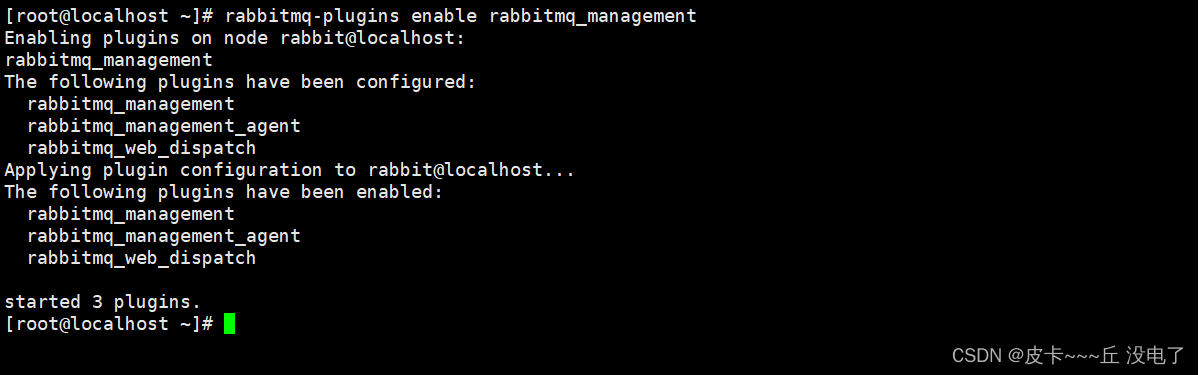
默认情况下,rabbitmq没有安装web端管理软件,需要安装才能生效
- rabbitmq-plugins enable rabbitmq_management
- #打开RabbitMQ web 管理界面插件
9.6.2、浏览器访问
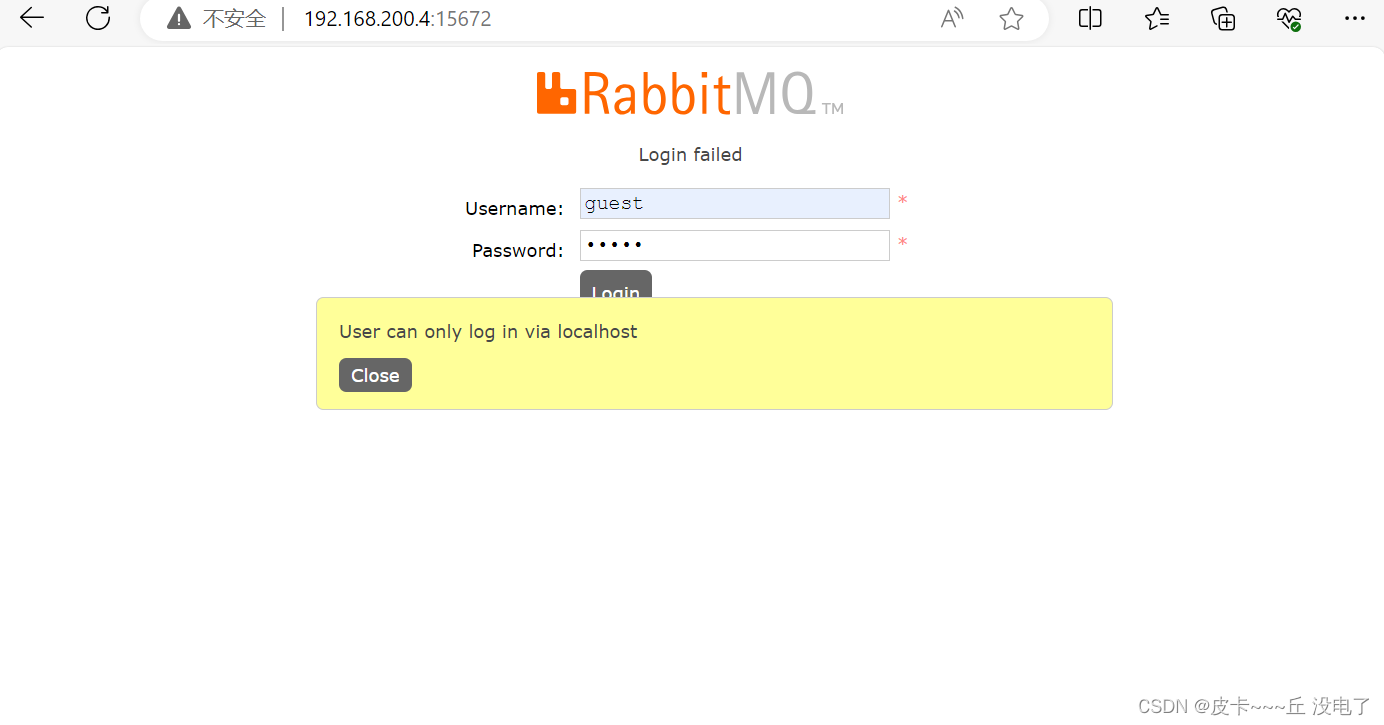
默认用户名和密码为guest/guest;但是rabbitmq从3.3.0开始禁止使用guest权限通过除localhost外的访问。
直接访问会报错提示:用户只能通过localhost登录
也可以通过查看日志

9.6.2.1、允许登录方式
rabbitmq默认的账号guest仅限于本机localhost进行访问,所以需要添加一个远程登录用户
9.6.2.1.1、添加用户
- #添加用户设置账号和密码
- rabbitmqctl add_user admin admin

9.6.2.1.2、设置权限
- #设置用户角色标签
- rabbitmqctl set_user_tags admin administrator

- #为用户添加资源权限(授予访问虚拟机根节点的所有权限)
- rabbitmqctl set_permissions -p / 用户名 "." "." ".*"

9.6.2.1.3、查看用户表
- #查看用户列表
- rabbitmqctl list_users

9.6.3、角色
- 超级管理员(administrator):可以登录控制台(启用management plugin的情况下)、查看所有信息、并对rabbitmq进行管理,对用户,策略进行控制。
- 监控者(monToring):可登录管理控制台(启用management plugin的情况下),可以查看rabbitmq节点的相关信息(进程数、内存使用情况、磁盘使用情况等)。
- 策略制定者(policymaker):可登录管理控制台(启用management plugin的情况下);可对policy进行管理。但无法查看节点的相关信息(即admin用户管理界面右边导航栏中的policies节点信息)。
- 普通管理者(managment):仅可登录管理控制台(启用management plugin的情况下);无法看到节点信息,也无法对策略进行管理。
通过本机ip:15672 进行登录,即可进入WEB管理界面

9.6.4、使用的端口
- 5672:消费者访问的端口
- 15672:web管理端口
- 25672:集群状态通信端口
十、管理命令
10.1、基本命令
- #启动rabbitmq,-detached代表后台守护进程启动
- rabbitmq-server start -detached
- #查看单节点状态
- rabbitmqctl status
- #关闭节点服务
- rabbitmqctl stop
- #关闭应用
- rabbitmqctl stop_app
- #启动应用
- rabbitmqctl start_app
- #查看rabbitmq集群状态
- rabbitmqctl cluster_status
10.2、用户管理命令
- #创建用户(no-administrative)
- rabbitmqctl add_user 用户名 密码
- #修改密码
- rabbitmqctl change_password 用户名 新密码
- #删除用户
- rabbitmqctl delete_user 用户名
- #清除用户密码
- rabbitmqctl clear_password 用户名
- #查看用户清单
- rabbitmqctl list_users
- #指引Rabbitmq broker认证该用户和密码
- rabbitmqctl authenticate_user 用户名 密码
- #设置用户角色(tag可以是零个、一个、或者是多个;并且已经存在的tag也将会移除)
- rabbitmqctl set_user_tags 用户名 角色。。。
10.3、访问控制命令
- #创建虚拟主机的名称
- rabbitmqctl add_vhost 虚拟主机名
- #删除vhost(删除一个vhost将会删除该vhost的所有exchange、queue、binding、用户权限、参数和策略)
- rabbitmqctl delete_vhost 虚拟主机名
- #列出虚拟主机列表(vhostinfoitem,表示要展示的vhost的字段信息,展示的结果将按照vhostinfoitem指定的字段顺序展示;字段包括:name(名称)tracing(是否为此vhost启动追踪);如果没有指定具体的字段项,那么将展示vhost名称)
- rabbitmqctl list_vhost vhostinfoitem
- #设置用户权限;{vhost}表示待授权用户访问的vhost名称,默认为“/”;{user}表示待授权反问待定vhost的用户名称;{conf}表示待授权用户的配置权限,是一个匹配资源名称的正则表达式;{write}表示待授权用户的写权限,是一个匹配资源名称的正则表达式;{read}表示待授权用户的读权限,是一个资源名称的正则表达式。
- rabbitmqctl set_permissions [-p vhost] {user} {conf} {write} {read}
- #设置用户拒绝访问指定的vhost;vhost默认值为“/”
- rabbitmqctl clear_permissions [-p vhost] {username}
- #列出具有指定用户的权限vhost,和在该vhost上的资源可操作权限
- rabbitmqctl list_user_permissions {username}
- #查看vhost列表
- rabbitmqctl list_vhosts
10.4、web页面插件管理
- #开启rabbitmq web页面插件功能
- rabbitmq-plugins enable rabbitmq_management
- #关闭rabbitmq web页面插件功能
- rabbitmq-plugins disable rabbitmq_management
- #查看插件
- rabbitmq-plugins list
10.5、队列管理
- #查看所有队列信息
- rabbitmqctl list_queues
- #清除某个队列里的消息
- rabbitmqctl -p [vhostpath] purge_queue [queue_name]
- #删除队列
- rabbitmqctl -p [vhostpath] delete_queue [queue_name]
10.6、应用管理
- #启动rabbitmq应用
- rabbitmqctl start_app
- #停止rabbitmq应用
- rabbitmqctl stop_app
- #重置应用(该命令需要在停止应用后使用)
- rabbitmqctl reset
-
相关阅读:
一、重写muduo网络库之服务器编程及测试
【编程题 】HJ64 MP3光标位置(详细注释 易懂)
Shell(8)循环
二、【React脚手架】组件化编码(TodoList案例)
【ES6】
liunx docker 安装 nginx:stable-alpine 后报500错误
mysql--重要知识点扫盲
Flutter macOS 教程之 02 手动安装macos_ui 如何添加macos_ui到您的历史项目pubspec.yaml文件 (教程含源码)
python在cmd中运行.exe文件时报错:不是内部或外部命令,也不是可运行的程序或批处理文件。的解决办法
STM8应用笔记2.变量空间的分配
- 原文地址:https://blog.csdn.net/m_j_y0_0/article/details/134260574
