-
【计算机网络】网络层IP协议
1. IP协议介绍
IP协议(Internet Protocol)是一种最常用的网络层协议,用于在网络传输过程中的路由选择,确定一条合适的传输路径。
网络是一个复杂的网状结构,由一个个节点交织组成,每一个节点可以是一台主机,也可以是一个路由器。不同网络之间通过路由器进行跳转。数据从传输层拷贝到网络层后,由网络层IP协议添加IP报头,成为IP报文,再发送到网络中。对于TCP/IP协议,可以说,TCP是提供传输策略的,而IP是“办事”的,负责实际传输的路径选择。

网络的简易结构
- IP协议工作在网络层,提供一种能力,跨网络将数据从主机A送到主机B,因此网络层IP协议解决的是主机到主机的通信问题。
- 网络环境错综复杂,IP协议有能力完成跨网络收发数据的任务,但并不能保证百分百完成。因此,由传输层TCP提供策略,建立各种机制如:超时重传、确认应答,保证网络传输的可靠性。传输层与应用程序进行数据交互,发送时将应用层数据进行一定的可靠性处理后再发送到网络层,接收时将网络层数据进行可靠性处理后再发送给应用层,因此传输层解决的是进程到进程的通信问题。

主机A向主机B发送数据的网络传输过程
2. IP报头
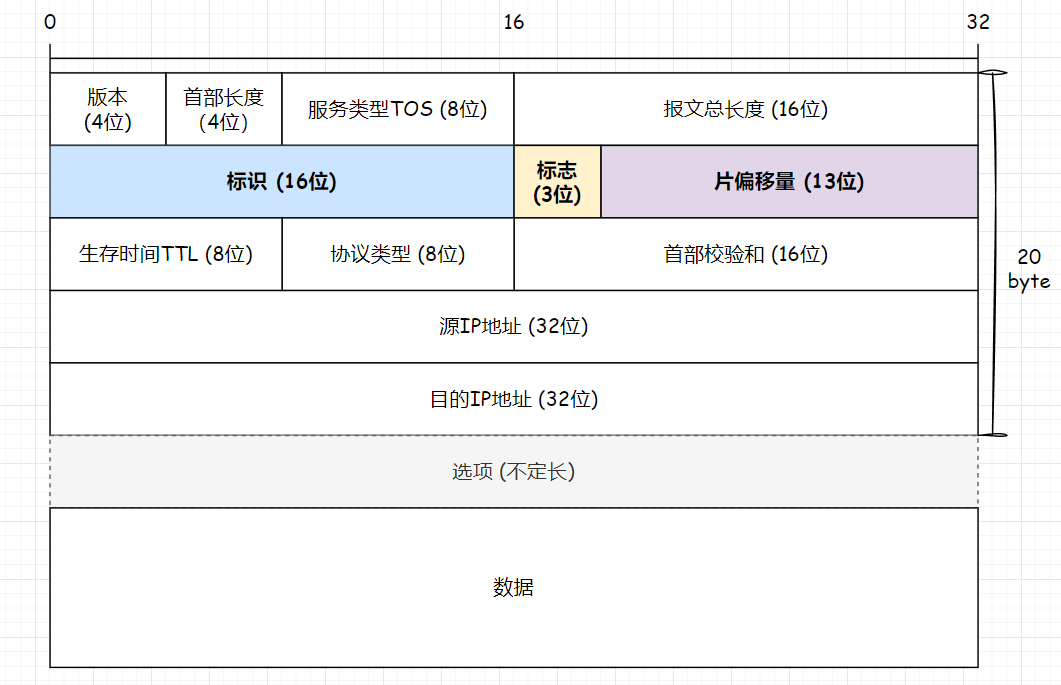
Header:
- 版本:指定IP协议版本,IPv4为4,IPv6为6,
- 首部长度:单位是4字节,范围是20~60字节。首部20字节定长,选项字段不定长。
- 服务类型 (Type Of Service):3位优先权字段(已弃用),4位TOS选项,1位保留置0。4种服务类型包括:最小延时、最大吞吐量、最高可靠性、最低成本,四者相互冲突,只能选一种。对于FTP协议,最大吞吐量比较重要。对于直播、视频这些应用程序,最小延时比较重要。
- 报文总长度:IP报文整体长度,最大值为65536字节。
- 标识:一个IP报文的编号,标识某个主机发送的唯一的IP报文。在IP报文的分片与组装中起重要作用。
- 标志和片偏移量:都在IP报文的分片与组装中起作用,后面相详谈。
- 生存时间 (Time To Live):IP数据包在网络中的最大生存时间(最大路由跳数),一般设为64。每经过一个路由,TTL就会减1,直到减为0则将该IP数据包丢弃,避免IP数据包在传输过程中发生路由循环。
- 协议类型:指明上层协议类型。TCP是6,UDP是17。
- 首部校验和:发送方计算,接收方验证,保证接收方收到的数据的正确性,鉴别头部是否损坏。
- 源IP地址和目的IP地址:“从哪来,到哪去”。标识了发送方的IP地址和接收方的IP地址。
Problem1:IP如何分离报头和有效载荷?
IP报头自描述了首部长度和报文总长度,根据这两个长度描述字段进行拆分即可。
Problem2:IP报文的有效载荷如何向上交付(分用)
IP之上的传输层有不同类型的协议,根据首部的8位协议类型,确定传给上层的哪一个协议模块。
3. IP的分片和组装
传输层的下层——数据链路层规定:一个数据帧的有效载荷长度不能超过MTU (Maximum Transmisson Unit, 最大传输单元),不同环境下的MTU不同,一般MTU为1500字节。这意味着,IP报文的大小不能超过MTU,为此,IP协议规定,对于超过MTU的IP报文,发送端对数据分片后再逐个发送,接收端收到多个分片后再组装还原。
这就好比快递公司规定单个包裹的重量不能超过2kg,而你要寄一个10kg的电竞椅给远方的好友,那你就需要将椅子拆成多个零件,打成5个包裹寄给他,这是“分片”。对方收到这些包裹后,再将零件统一组成起来,得到最终的椅子,这是“组装”。那么,你“分片”的时候,肯定不能胡乱拆,对方收到零件时也不能胡乱“组装”,双方必须达成某种策略的共识,比如你拆完后告知对方如何组装。
IP协议的分片,本质就是将一个大报文分成多个小报文,组装就是将多个小报文组装成一个大报文。
🔎IP协议的分片和组装的策略用到了IP首部的三个字段:
16位标识:标定一个唯一的IP报文,多个分片在分开前属于同一个IP数据包,因此标识编号相同。
3位标志:第一位保留;第二位是禁止分片标志,一个IP报文的禁止分片标志位置为1时,若该报文长度大于MTU,则在IP模块直接丢弃。第三位是更多分片标志,如果分片了,此位置1表示当前分片后面还有更多分片,置0表示当前分片是最后一个分片,类似于一个结束标志。
13位片偏移:如果分片了,片偏移表示当前分片在原始IP报文中相对于初始位置的偏移量,0表示第一个分片。片偏移的单位是8字节。
发送端的IP分片过程:

⭕注意:每个IP分片的大小必须是8的整数倍,保证片偏移量为整数(图中数字不是8的整数倍,只是为了方便演示)
接收端的IP组装过程:
接收端收到各种IP报文,需通过IP报头的更多分片标志和片偏移,确定该IP报文是否是分片。会有以下四种情况:
- 更多分片0,片偏移0:非分片,该报文是独立报文。
- 更多分片1,片偏移0:该报文是分片,且是某个原始IP报文的第一个分片。
- 更多分片1,片偏移>0:该报文是分片,且是某个原始IP报文的中间分片。
- 更多分片0,片偏移>0:该报文是分片,且是某个原始IP报文的最后一个分片。
第一种情况表示该报文不是分片,后三种情况是分片报文的不同位置情况。

-
如何确保接收端能够收齐一个原始IP报文的全部分片?
💭值得注意的是,一个原始IP报文的多个分片,大概率不是同时到达接收端的,因此,当接收端收到来自某台主机的IP报文,检测其为分片报文(四种情况的后三种),就会开辟一个专属于该报文标识的缓冲区,等待其它分片到来。后续检测到有同主机相同标识的分片报文,就会进入该缓冲区组装。
⭕分片可能会在传输过程中丢包,导致接收端收到的分片是残缺的。根据分片的四种情况,头尾分片是能够确定的,中间也能根据片偏移确定,因此接收端具有分辨分片是否丢失的能力。接收端检测到分片有残缺部分,无法组装成完整报文,就不会向上交付,一直维护在网络层。接收端TCP一直无法收到数据,就不会向发送端应答,时间久了,发送端便会触发超时重传,IP后续可能会重新收到来自发送端的分片。只有IP组装成完整报文,才会向上交付,这次数据接收才算完成。综上所述:
- IP协议并不能保证分片收齐,而是由TCP保证的。
- 分片与组装是IP协议的模块,TCP并不关心,所以,当IP分片某一块残缺时,TCP重传整个报文,而不是残缺的一部分。
-
如何保证接收端组装的报文一定是正确的?
IP报头的16位首部校验和保证IP报头的正确性,有效载荷数据正确性由上层协议保证,如:TCP报头的16位校验和,保证了整个TCP报文的正确性。
-
IP分片的弊端
网络中,过多的分片可能会提高丢包率,增加网络负担,加长网络延时,因此,正确的做法是尽量避免分片的发生。IP会发生分片,归根到底是因为上层发送的数据过大,超过了下层MTU的限制,而IP协议只是个“跑腿”的,别人给他多少数据他都得传,因此,避免分片应该由上层传输层实现。TCP为了避免数据在底层分片,每次发送的数据不能过大,因此引入了MSS (Maximum Segment Size),表示TCP单个报文的数据部分最大长度。 之所以TCP的滑动窗口内要分成多个报文发出,就是因为有MSS在控制单个报文的大小。MSS的值取决于底层的MTU,在不同环境下不同,一般为1460。TCP三次握手建立连接阶段会进行MSS协商(在首部选项中携带MSS长度字段),取双方MSS最小值作为传输所用的MSS。
4. IP地址
网段划分
💭互联网实际上是由一个个的网段组成的,网段中包含主机或更小范围的网段。
- 每个主机的IP地址由两部分构成:网络号 + 主机号。其中,网络号指的是主机所处网段的唯一标识,主机号指同一网段内区分不同主机的编号。同一网段中的主机,网络号相同,主机号不同,不同网段中的主机,网络号一定不同,但主机号可以相同。这样一来,IP地址就有了标识网络中唯一主机的能力。
- 不同网段之间,由路由器连接,路由器相对于每个网段的出入口,数据的发送和接收都要通过路由器。

同一网段中不同主机的IP由路由器管理,路由器会自动为网段中每一台连入的新主机分配IP地址,避免了手动管理IP的麻烦,这种技术称为DHCP。每一台路由器都有DHCP功能,因此也可将路由器看作一台DHCP服务器。
🔎IP地址通过网络号+主机号的形式,能够区分网络中唯一一台主机。那么,如何合理地进行网段划分呢?
历史上刚开始采用的是A, B, C, D, E五类网段划分,每一类网络中的IP范围不同,IP地址的网络号和主机号位数分布也不同。但这种划分策略因为其固定的地址划分,可能会导致地址浪费、缺乏灵活性。因此,当今互联网采用了子网掩码的方式划分网段。
子网掩码(Subnet Mask)用于灵活地区分IP地址的网络号和主机号。子网掩码是一个32位的整数,其比特位表现为:前半部分全1,后半部分全0。IP地址与子网掩码按位与,得到网络号。
🌰例如:
IP地址:192.168.0.7
子网掩码:255.255.255.0
网络号 = IP & mask = 192.168.0.0
不同子网可以根据自身情况选择子网掩码,确保主机号位数的合理分配,避免地址浪费,这种方案大大优于使用五类网段的固定划分形式。
每一台主机都配套一个IP地址+子网掩码的组合,可以区分该主机的网络号和主机号。IP地址和子网掩码还有一种更简洁的表示方法,例如140.252.20.68/24,表示IP地址为140.252.20.68,子网掩码的高24位是1,也就是255.255.255.0。
特殊的IP地址
- IP地址的主机号全0,代表这个子网的网络号。
- IP地址的主机号全1,代表这个局域网的广播地址,用于给同一个链路的所有主机发送数据包。
- 127.*的IP地址用于本机环回(loop back)测试,通常是127.0.0.1。
子网、局域网、网段的区别
通常在不追求严格的语境下,三者可以混用。具体的:
-
局域网是数据链路层的概念,通常是指一个二层可达的网络,即发送数据不需要经过路由器向外转发。
-
子网是网络层的概念,一个IP地址划分的结果,是一个相对概念,子网可以连接着上层更大范围的公网,也可以连接更小范围的子网。子网与子网之间的通信需要路由。
-
网段和子网(Subnet)通常是同一个概念,只不过网段一般范围大于子网,用于描述更大范围的子网。
IP地址的数量限制
IP(IPv4)地址只有4字节32位,能组成232个(约等于43亿)不同的IP地址。这是互联网开始发展时的规定,而随着互联网蓬勃发展,主机设备的增多,IP地址已经远远不够用了。此时有三种技术能够解决:
- 动态ip地址分配: 路由器动态地为子网中的主机分配ip地址,连接时分配,断连时就回收,供其它在线设备使用,提高了ip地址的利用率。因此同一个MAC地址的设备,每次连入网络的IP地址不一定相同。
- IPv6: IP地址以128位整数表示,即有2128个不同的ip地址,管够。但是如今IPv6尚未普及。
- NAT(Net Address Translation):地址转换技术,目前主流的解决IP地址枯竭的技术,后面详谈。
5. 公网IP和私有IP
互联网的网段划分按照不同国家不同地区划分,层层划分,细分到某块小地区,必定存在IP地址位数不够的问题,例如:划分到我国某市的IP地址为12.34.192.00/18,此时仅有214(约等于1.6w)个不同的主机号,这对一个城市量级的网络来说是远远不够的。
因此,网段划分到一定的小区域时,公网IP不足以分配时,就需要建立局域网了。如果一个子网中的IP地址只用于内部通信,而不与外网直接通信,那么子网内部的IP地址理论上只要保证内部唯一就可以,这就是私有IP。但是RFC 1918规定了用于组建局域网的私有IP地址前缀:
- 10.:前8位是网络号,后16位是主机号,共16777216个地址;
- 172.16.*~172.31.:前12位是网络号,后4位是主机号,共1047576个地址;
- 192.168.*:共65535个地址
💡公网IP十分有限,不是每个组织或机构都可以分配到的,因此我们引进了私有IP解决问题。通常各地的运营商掌握着公网IP资源,我们家里的路由器入网,需要当地运营商的工作人员上门操作,本质上就是将家用路由器连入运营商的子网。可以理解为,一个地区的运营商管理着当地所有家庭、公司等组织的路由器,形成一个子网,内部要访问外网必须经过运营商路由器。运营商路由器也可能是层层递进的,只有最顶层的运营商路由器,才有公网IP,访问外网的能力。因此,运营商在我们日常网络通信中,扮演重要角色。

一个路由器可以配置LAN和WAN两个地址:
-
LAN (Local Area Network):路由器的子网IP
-
WAN (Wide Area Network):路由器在外层网络中的IP地址
- 对于运营商管理的路由器,LAN地址一般都是一样的(通常是192.168.0.1)。不同路由器管理的子网中,各主机之间的IP地址是唯一的,而不同子网之间主机的IP可以相同。
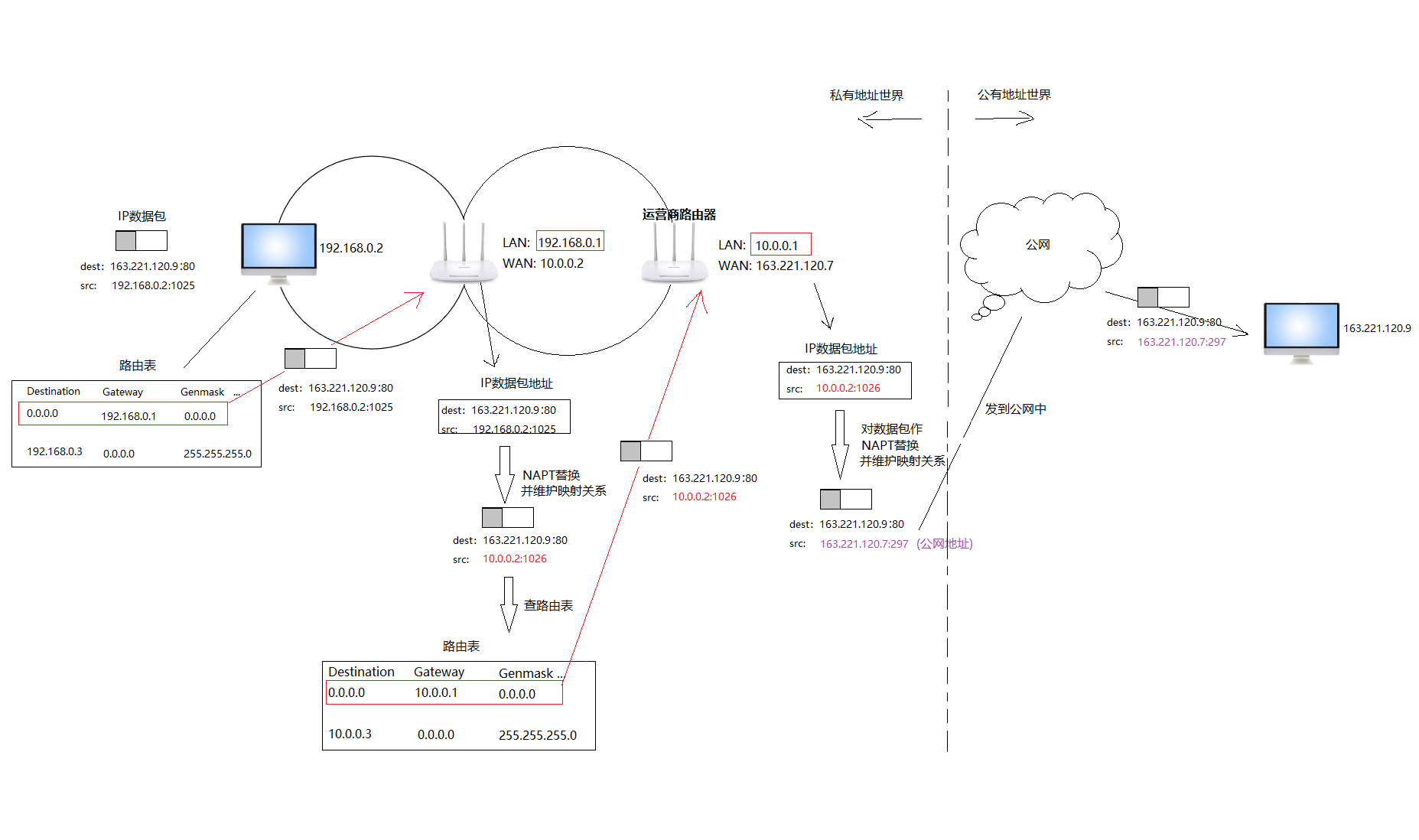
- 顶层运营商路由器的WAN地址就是一个公网IP,一个子网内的主机要想访问外网,就必须经过路由到运营商路由器,再由运营商路由器将网络数据包转发到公网中。
- 子网内的主机访问外网服务器,路由时,每层路由器会将IP首部的IP地址替换为WAN地址,最终到运营商路由器时,就会形成一个具有公网IP的数据包。这种技术就称为NAT技术(地址转换,Net Address Translation)。
6. NAT技术
子网内的主机要想与外网通信,必须将私有地址转换为公网地址,NAT技术提供了这种转换的能力。如果通信过程一直使用的是私有地址,因为私有地址在公网中无效,多个子网中可能相同,所以从子网能向外网发送数据,而外网却无法根据IP地址向确定的子网发回响应。
- NAT地址转换过程如下:

子网向外发送数据包时,经由NAT路由器,转换IP首部的源地址为路由器的WAN地址,这么做是为了未来对端服务器能够知道将响应发回给谁。而NAT路由器内部需要自动维护一张表,记录转换前后的地址映射关系。
外网服务器向子网发回数据包,根据历史的源地址作为目标地址,发送到目标主机(实际上这个目标是一个NAT路由器)。路由器收到后,查表将目标IP替换回原来的IP,再向目标IP发送数据。
NAT路由器的子网中有多台主机,如果这些主机向外发送数据时,都将目标IP替换为同一个WAN地址,那么路由器收到外部数据时,如何确定应该给哪台主机转发数据呢?这时候NAPT (Network Address and Port Translation)来解决这个问题了,使用IP+port来建立这个关联关系。
NAPT将局域网内的一个网络进程看作是通信的单位(不再是一台主机),采用IP+port的形式确定同一局域网内唯一的一个网络进程。NAPT的工作原理如下:子网内部设备的某个进程请求访问外部网络时,路由器会为其分配一个临时的端口号,并将请求内部的IP地址(IP首部)和端口号(TCP首部)分别替换为路由器WAN地址和临时端口号。
- 路由器NAPT分配的端口号是唯一的,不同IP数据包的临时端口号不同
- 路由器NAPT表中维护的映射关系是:目标地址+原始源地址 与 目标地址+替换后的源地址,替换后的源地址用于向外发送数据。
- 当收到外部数据时,根据外部数据包的目标地址与表中替换后的源地址比对,找到原始的源地址,确定要发给哪一个内部的目标。
- 转换表的映射关系是动态开辟的,通信结束时,对应的映射关系就会销毁。例如在TCP的情况下,建立连接时,就会生成对应表项; 在断开连接后,就会删除这个表项。

🔎为什么表项中要存储目标地址?
本质是为了拒收非法的外部数据,子网只允许接收自己曾请求的外部节点的数据。对于其它未知的外部节点,通过表项中历史目标地址的比对,可以将其排除,拒收其发送的数据包,这样可以有效避免外部对子网的数据攻击。
NAT的缺陷:
由于NAT依赖这个转换表,因此会有一些缺陷:
- 转换表的创建、维护和销毁都需要成本;
- 无法从外部服务器向NAT内网发送数据;
- 通信过程中一旦NAT设备异常,即使存在热备,所有的TCP连接也都会断开。
7. 路由Route
🚚路由就是在复杂的网络结构中,找到一条通向目标主机的路径,逐步逼向终点的过程。
路由是跨网络传输的过程,需要经过多个路由器。数据包到达每一个路由器,都会进行“问路”的动作,获知下一跳要到哪里。每个路由器中会维护一张路由表,表中包含与该路由器属于同一层级子网的设备IP地址,如果“问路”时在表中找不到目标IP地址,表示数据包的目标不在本地网络范围内,就会将数据交付给当前子网的出口路由器(默认路由)。以此反复,直到达到目标IP地址。
注意:数据链路实现某一子网区间内的通信,IP协议实现直至最终目标的通信
事实上,除了路由器,一般主机也会维护路由表,主要用于保存默认路由的信息(又称缺省路由),访问外网时直接将数据送往默认路由。
Linux中,
route命令(选项-n表示以数字显示)可以查询当前主机的路由表信息。
Destination: 目标网络或主机的IP地址,这里第一行的0.0.0.0是缺省路由。
Gateway: 下一跳路由器的IP地址。
Genmask: 子网掩码。
Flags:Flags中的U标志表示此条目有效(可以禁用某些条目),G标志表示此条目的下一跳地址是某个路由器的地址,没有G标志的条目表示目的网络地址是与本机接口直接相连的网络,不必经路由器转发。
Iface:发送接口,一般是指哪一个网卡。
关于Destination:
同一局域网内,可能会连接不同的主机,也可能会存在不同的子网。因此,Destination可能是主机IP,也可能是目标网络IP。
跨网络,路由表Destination存储的是子网IP,目标IP与Genmask进行与运算,可以得到网络号,与子网IP进行比对,若相同则下一跳进入该子网;不跨网络路由表Destination存储的就是主机IP了。
一个主机可能有多张网卡,连接不同的网络,目标IP和子网掩码配合使用可以确定IP数据包送往哪个网络。
关于Gateway:
gateway,网关,是指下一跳路由器的IP。同一局域网的设备,因为直连同一网络,所以传输数据无需经过路由器,Gateway设为0.0.0.0。若传输目标不在本地网络,就要使用缺省路由发送到外部网络,因此缺省路由的Gateway设置为该路由器的IP。一个数据包从某台主机发出,查路由表,发现目标地址不在本地网络,就使用缺省路由,其Gateway告知下一跳路由器的IP地址。
转发示例1:如果要发送的数据包的目标地址是10.0.8.0
查找到第二行的Destination为10.0.8.0,表示数据包在当前主机的子网内,不必经路由器转发,直接通过eth0接口向目标主机发送即可(局域网通信是数据链路层的概念)
转发示例2:如果要发送的数据包的目标地址是122.10.1.2
在路由表中查无匹配的Destination,则使用默认路由,第一行的Gateway表明默认路由的IP地址为10.0.8.1。从eth0接口向10.0.8.1发送数据包,并由默认路由根据它的路由表决定下一跳去哪。
附:一个内网主机向互联网发送数据的单向过程(包括路由表查找、NAPT地址替换、私有IP和公有IP)
ENDING…
-
相关阅读:
Maven依赖仲裁
二维数组与指针(杰哥强化版)
杰夫 · 迪恩:《深度学习的黄金十年:计算系统与应用》
【Leetcode】剑指Offer 30:包含min函数的栈
sh、bash 和 dash 几种 shell 的区别是什么?
“中式汉堡”塔斯汀圈粉受众的秘诀是什么?
docker笔记
用函数的递归来解决几道有趣的题
数据库实验三——数据更新操作中经典题、难题以及易错题合集(含数据导入导出操作详细教程)
vue生成动态表单
- 原文地址:https://blog.csdn.net/C0631xjn_/article/details/134240776