-
ViT模型中的tokens和patches概念辨析
概念辨析
在ViT模型中,“tokens”(令牌)和"patches"(图像块)是两个相关但不同的概念。
-
令牌(Tokens):在ViT中,令牌是指将输入图像分割成固定大小的图块,并将每个图块映射为一个向量表示。这些向量表示即为令牌。每个令牌代表图像中的一个局部区域,可以看作是图像的抽象表示。通过将图像分割成令牌序列,并将其输入到Transformer模型中,ViT能够利用自注意力机制来建模图像中的全局关系。
-
图像块(Patches):图像块是指将输入图像分割成固定大小的小块。在ViT中,图像块被用作生成令牌的基本单位。每个图像块由一组像素组成,并通过线性变换映射为令牌的向量表示。图像块的目的是将图像分割为可处理的小块,以便进行后续的编码和处理。
因此,图像首先被分割为图像块(patches),然后每个图像块被映射为一个令牌(tokens)。令牌是对图像块的抽象表示,用于输入到Transformer模型中进行全局关系的建模。
对于标准的Transformer模块,要求输入的是token(向量)序列,即二维矩阵[num_token, token_dim],如下图,token0-9对应的都是向量。
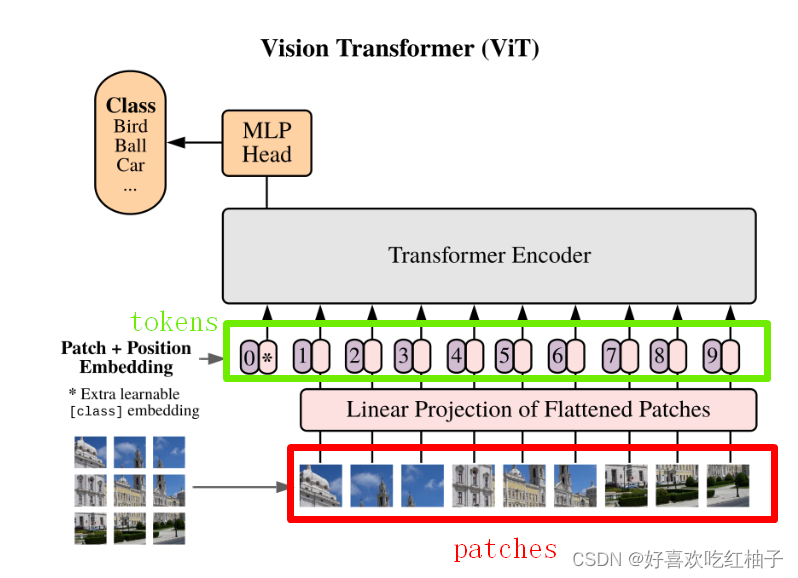
输入步骤
- 首先将一张图片按给定大小分成一堆Patches。以ViT-B/16为例,将输入图片大小(224x224)按照16x16大小的Patch进行划分,划分后会得到 ( 224 / 16 ) 2 = 196 ( 224 / 16 ) ^2=196 (224/16)2=196个Patches。
- 通过线性映射将每个Patch映射到一维向量中,以ViT-B/16为例,每个Patche数据shape为[16, 16, 3]通过映射得到一个长度为768的向量(直接称为token)
总结起来,图像块是图像的原始分割块,而令牌是对图像块的向量表示,用于输入ViT模型进行处理。
-
-
相关阅读:
华为机试真题 Java 实现【最大平分数组】【2022.11 Q4新题】
SkiaSharp 之 WPF 自绘 粒子花园(案例版)
Sass系统学习
万字长文学会对接 AI 模型:Semantic Kernel 和 Kernel Memory,工良出品,超简单的教程
淘宝/天猫获得淘宝商品详情 API 返回值说明
2023年三大网络安全威胁不容忽视
jQuery Validation Engine验证模拟的下拉列表非select
opencv入门
【C++杂货铺】会杂耍的二叉搜索树——AVLTree
计算机二级WPS 选择题(模拟和解析十二)
- 原文地址:https://blog.csdn.net/weixin_45662399/article/details/134252015