-
嵌入式C语言自我修养《数据存储与指针》学习笔记
目录
程序是什么?程序=数据结构+算法。我们写程序为了什么?为了解决现实中的一些问题,尤其是一些需要大量重复计算的问题。ANSI C标准为我们提供的32个关键字里,除了控制程序结构的一些关键字,绝大部分都与数据类型和存储相关,如表7-1所示。

C99/C11标准新增的关键字,也大都与数据类型和存储相关,如表7-2所示。

一、数据类型和存储
类型,是一组数值及对该组数值进行各种操作的集合。同一种类型的数据,在不同的处理器平台下,存储方式可能不一样。不同类型的数据,在同一个处理器平台下,存储方式和运算规则也可能不一样。
1.大端模式和小端模式
在计算机中,位(bit)是最小的存储单位,在一个DDR SDRAM内存电路中,通常使用一个电容器来表示:充电时高电位表示1,放电时低电位表示0。8个bit组成一字节(Byte),字节是计算机最基本的存储单位,也是最小的寻址单元,计算机通常以字节为单位进行寻址。在一个32位的计算机系统中,通常4字节组成一个字(Word),字是软件开发者常用的存储单位。
我们使用C语言提供的int关键字,可以定义一个整型变量。
int i = 0x12345678编译器根据变量i的类型,在内存中分配4字节大小的存储空间来存储i变量的值0x12345678。一个数据在内存中有2种存储方式:高地址存储高字节数据,低地址存储低字节数据;或者高地址存储低字节数据,而低地址则存储高字节数据。不同字节的数据在内存中的存储顺序被称为字节序。根据字节序的不同,我们一般将存储模式分为大端模式和小端模式。
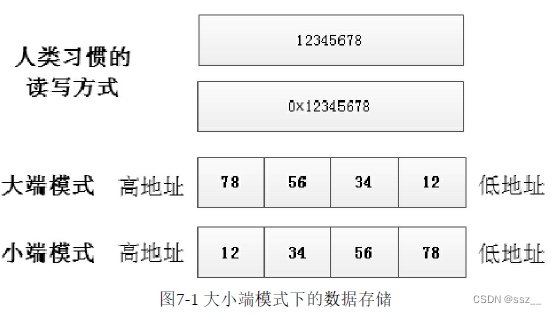
不同架构的处理器,存储模式一般也不同。ARM、X86、DSP一般都采用小端模式,而IBM、Sun、PowerPC架构的处理器一般都采用大端模式。判断大小端示例:
- #include
- int main()
- {
- int a = 0x11223344;
- char b = a;
- if(b = 0x44)
- {
- printf("littel duan\n");
- }
- else
- {
- printf("da duan\n");
- }
- return 0;
- }
在数据存储模式中,除了字节序,还有位序的概念。位序指在一字节的存储中,各个比特位的存储顺序。以十六进制数据0x78=01111000(B)为例,其在内存中可能有2种存储方式。

一般情况下字节序和位序是一一对应的。小端模式下,低端地址存储低字节数据,在一字节中,bit0地址也用来存储这个字节的bit0位。大端模式则相反,bit0用来存储一字节的高比特位。
为什么不同架构的处理器在存储模式上会有大小端之分呢?
一般来讲,小端模式低地址存储低字节数据,比较符合人类的思维习惯;而大端模式则更适合计算机的处理习惯:不需要考虑地址和数据的对应关系,以字节为单位,把数据从左到右,按照由低到高的地址顺序直接读写即可。大端模式一般用在网络字节序、各种编解码中。
2.有符号数和无符号数
C语言为了能表示负数,引入了有符号数和无符号数的概念,在声明数据类型时分别使用关键字signed和unsigned修饰。我们定义的变量如果没有使用signed或unsigned显式修饰,默认是signed型的有符号数。
一个字符型的有符号数,最高的位bit7是符号位:0表示正数,1表示负数,其余的比特位用来表示大小。而一个字符型的无符号数,所有的比特位都用来表示数的大小。因此有符号数和无符号数能表示的数值范围是不一样的,对于一个字符型数据而言,有符号数能表示的数值范围为[-128,127],而无符号数的数值范围为[0,255]。我们使用printf()函数打印数据时,可以使用%d和%u格式符分别格式化打印有符号数和无符号数。


二、数据对齐
1.为什么要数据对齐
一个程序在编译过程中,编译器在给我们定义的变量分配存储空间时,并不是随机分配的,它会根据不同数据类型的对齐原则给变量分配合适的地址和大小。所谓数据对齐原则,就是C语言中各种基本数据类型要按照自然边界对齐:一个char型的变量按1字节对齐,一个short型的整型变量按sizeof(short)字节对齐,一个int型的整型变量要按sizeof(int)字节对齐。每种数据类型的对齐字节数一般也被称为对齐模数。不同数据类型的对齐模数如图7-3所示。

示例代码:
- #include
- int main(void)
- {
- char a = 1;
- short b = 2;
- int c = 3;
- printf("&a = %p\n",&a);
- printf("&b = %p\n",&b);
- printf("&c = %p\n",&c);
- return 0;
- }
程序运行结果:
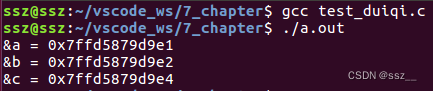
通过打印结果可以看到,不同类型的变量在内存中的地址对齐是不一样的,每种变量都按照各自的对齐模数对齐。
每个变量在内存中为什么非要地址对齐呢?
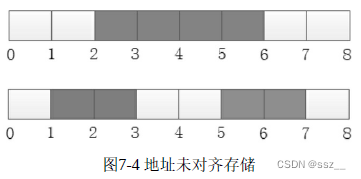
这主要是由CPU硬件决定的。不同处理器平台对存储空间的管理不同,为了简化CPU电路设计,有些CPU在设计时简化了地址访问,只支持边界对齐的地址访问,因此编译器也会根据处理器平台的不同,选择合适的地址对齐方式,以保证CPU能正常访问这些存储空间。在图7-4中,我们定义了一个int型变量,如果编译器把它分配到了内存中2字节对齐的地址空间上,那么它的存储地址就没有自然对齐,CPU在读写这个数据时,本来一个指令周期就可以搞定的事情,现在可能就需要花2个指令周期了。先从零地址开始,读取4字节,保留高2字节的数据;再从偏移为4的地址开始,读取4字节,保留低2字节的数据;最后将两部分数据合并,就是我们实际要读取的int型变量的值了。
2.结构体对齐
C语言的基本数据类型不仅要按照自然边界对齐,复合数据类型(如结构体、联合体等)也要按照各自的对齐原则对齐。以结构体为例,当我们定义一个结构体变量时,编译器会按照下面的原则在内存中给这个变量分配合适的存储空间。
● 结构体内各成员按照各自数据类型的对齐模数对齐。
● 结构体整体对齐方式:按照最大成员的size或其size的整数倍对齐。示例如下:
- #include
- struct student
- {
- char sex;
- int num;
- short age;
- };
- int main(void)
- {
- struct student stu;
- printf("&stu.sex = %p\n",&stu.sex);
- printf("&stu.num = %p\n",&stu.num);
- printf("&stu.age = %p\n",&stu.age);
- printf("struct size: %d\n",sizeof(struct student));
- return 0;
- }
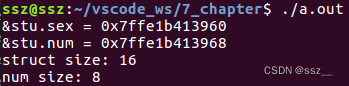
运行结果如下:

结构体成员调整位置结果如下:

因为结构体内各个成员都要按照自身数据类型的对齐模数对齐,所以在结构体内部难免会有“空洞”产生,导致结构体的大小也不一样。结构体之所以要对齐,根本原因就是为了加快CPU访问内存的速度,在具体实现上,一般都采用每种数据类型的默认对齐模数sizeof(type)对齐。
不同的编译器有时候可能会采取不同的对齐标准,以GCC为例,GCC默认的最大对齐模数为4(我的gcc是8,好像是因为x64位,为了提高系统运行性能),当一种数据类型的大小超过4字节时会仍然按照4字节对齐,这是GCC和VC++6.0、Visual Studio、arm-linux-gcc等编译器不一样的地方。
代码示例如下:
- //#pragma pack (4)
- #include
- struct student
- {
- char sex;
- double num;
- };
- int main(void)
- {
- struct student stu;
- printf("&stu.sex = %p\n",&stu.sex);
- printf("&stu.num = %p\n",&stu.num);
- printf("struct size: %d\n",sizeof(struct student));
- printf("num size: %d\n",sizeof(stu.num));
- return 0;
- }
运行结果如下:
加上第一行代码#pragma pack (4),运行结果如下:

如果在结构体里内嵌其他结构体,那么结构体作为其中一个成员也要按照自身类型的对齐模数对齐。结构体自身的对齐模数是该结构体中最大成员的size,或者其size的整数倍。
3.联合体对齐
除了结构体,联合体也有自己的对齐原则。
● 联合体的整体大小:最大成员对齐模数或对齐模数的整数倍。
● 联合体的对齐原则:按照最大成员的对齐模数对齐。示例如下:
- //#pragma pack (4)
- #include
- union u
- {
- char sex;
- double num;
- int age;
- char a[11];
- };
- int main(void)
- {
- union u stu;
- printf("&stu.sex = %p\n", &stu.sex);
- printf("&stu.num = %p\n", &stu.num);
- printf("&stu.age = %p\n", &stu.age);
- printf("&stu.a = %p\n", stu.a);
- printf("union size: %d\n", sizeof(union u));
- return 0;
- }
运行结果如下:
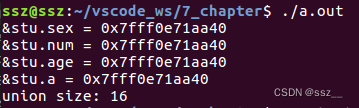
当开头加上#pragma pack (4) ,设置最大对齐模数为4时,运行结果如下:

三、数据的可移植性
什么是数据的可移植性呢?我们可以先从一个简单的程序开始,从一个sizeof关键字开始我们的思考。
- #include
- int main(void)
- {
- printf("%d\n",sizeof(int));
- return 0;
- }

我们可以使用sizeof关键字去查看int类型的数据在内存中的大小,在不同的编译环境下编译上面的程序并运行,你会发现运行结果可能不一样。在Turbo C环境下编译运行,int型数据大小可能是2字节;使用VC++6.0或GCC编译,运行结果可能是4字节;如果使用64位编译器在64位处理器上编译运行,运行结果则可能是8字节。在一个跨平台的程序中,有时候我们会需要一个固定大小的存储空间,或者一个固定长度的数据类型。如果使用int型来表示,那么当程序在不同的编译环境下运行时,int型数据的大小就可能发生改变,也就是说int型数据不具备可移植性。
那么如何解决这个问题呢?我们可以使用C语言提供的typedef关键字来定义一些固定大小的数据类型。

我们可以将使用typedef关键字定义的数据类型封装在一个头文件data_type.h中,在实际编程中,当你需要使用一个32位固定大小的无符号数据时,先#include这个data_type.h头文件,然后就可以直接使用u32来定义变量了。当程序在另一个平台上运行,unsigned int的大小变成了2字节时,也没关系,我们可以修改data_type.h,将u32使用unsigned long重新定义一遍即可。
- //data_type.h
- //typedef unsigned int u32;
- typedef unsigned long u32;
- //main.c
- #include
- #include "data_type.h"
- int main(void)
- {
- u32 s;
- printf("size:%d\n",sizeof(s));
- return 0;
- }
long的运行结果是8,int的运行结果是4。
通过修改data_type.h对u32类型重新定义后,u32的长度还是32位,你的程序代码中所有使用u32的地方就不需要修改了,u32这个数据类型因此就具备了可移植性,可以在多个平台上运行。
在C99标准定义的标准库中,新增加了stdint.h和intypes.h头文件,用来支持可移植的数据类型。stdint.h头文件主要用来定义可移植的数据类型,我们在编程中可以直接使用。- #include
- #include
- int main(void)
- {
- __int16_t s;
- int16_t s1;
- printf("size: %d\n",sizeof(s));
- printf("size: %d\n",sizeof(s1));
- return 0;
- }
运行结果如下:

现在的操作系统一般都支持多种CPU架构、多种处理器平台。操作系统为了实现跨平台运行,一般都会考虑数据的可移植性,如大小端存储模式、数据对齐、字长等。我们在编程时,可以把程序中与系统、平台相关的部分隔离封装在一个单独的头文件或配置文件中,整个程序的可移植部分和不可移植部分也就变得泾渭分明,更加方便后续的管理、维护和升级。
四、 Linux内核中的size_t类型
Linux内核中定义了很多变量,使用了各种不同的数据类型,总的来说,可以分为3类。
● C语言基本数据类型:int、char、short。
● 长度确定的数据类型:long。
● 特定内核对象的数据类型:pid_t、size_t。我们以内核中经常使用的size_t数据类型为例,带大家体验一下使用可移植数据的好处。数据类型size_t一般使用#define宏定义,后面使用一个_t的后缀表示Linux内核中在某些地方特定使用的数据类型。
size_t数据类型一般用在表示长度、大小等无关正负的场合,如数组索引、数据复制长度、大小等。在Linux内核源码中可以随处看到它的身影。

不仅在内核中,C标准库中定义的各种库函数也大量使用这种数据类型。

使用size_t不仅仅是考虑到数据类型的可移植性,size_t的另一个优点是其大小并非是固定的,而是用来表征针对某平台的最大长度。当我们使用无符号型的size_t用来表示一个地址或者数据复制的长度时,根本不用担心它表示的数值范围够不够用。
五、typedef的使用
typedef是C语言的一个关键字,用来为某个类型起别名。大家在阅读代码的过程中,会经常见到typedef与结构体、联合体、枚举、函数指针声明结合使用。
1. typedef的基本用法
以结构体类型的声明和使用为例,C语言提供了struct关键字来定义一个结构体类型。
- struct student
- {
- char name[20];
- int age;
- float score;
- };
- struct student stu = {"wit", 20, 99};
在C语言中定义一个结构体变量,我们通常的写法如下。
struct 结构类型 变量名;
前面必须有一个struct关键字做前缀,编译器才会理解你要定义的对象是一个结构体变量。而在C++语言中,则不需要这么做,可以直接使用。
结构类型 变量名;
- struct student
- {
- char name[20];
- int age;
- float score;
- };
- int main(void)
- {
- student stu = {"wit", 20, 99};
- return 0;
- }
我们使用typedef关键字,可以给student声明一个别名student_t和一个结构体指针类型student_ptr,然后可以直接使用student_t类型去定义一个结构体变量,不用再写struct,这样会显得代码更加简捷。
示例代码如下:
- #include
- typedef struct student
- {
- char name[20];
- int age;
- float score;
- }student_t, *student_ptr;
- int main(void)
- {
- student_t stu = {"wit", 20, 99};
- student_t *p1 = &stu;
- student_ptr p2 = &stu;
- printf("name: %s\n",p1->name);
- printf("name: %s\n",p2->name);
- return 0;
- }
运行结果如下:

typedef除了与结构体结合使用,还可以与数组结合使用。定义一个数组,通常使用int array[10];即可。我们也可以使用typedef先声明一个数组类型,然后使用这个类型去定义一个数组。

在上面的程序中,我们声明了一个数组类型array_t,然后使用该类型定义一个数组array,这个array效果其实就相当于int array[10]。typedef还可以与指针结合使用。在下面的demo程序中,PCHAR的类型是char*,我们使用PCHAR类型去定义一个变量str,其实就是一个char*类型的指针。

typedef还可以和函数指针结合使用。定义一个函数指针,我们通常采用下面的形式。
int (*func)(int a, int b)我们同样可以使用typedef声明一个函数指针类型:func_t。
- typedef int (*func_t)(int a, int b)
- func_t fp; //定义一个函数指针变量
代码示例如下:
- #include
- typedef int (*func_t)(int a, int b);
- int sum(int a, int b)
- {
- return a + b;
- }
- int main(void)
- {
- func_t fp = sum;
- printf("%d\n",fp(1,2));
- return 0;
- }
运行结果为:3
为了增加程序的可读性,我们经常在代码中看到下面的声明形式。
- typedef int (func_t)(int a, int b);
- func_t *fp = sum;
函数都是有类型的,我们使用typedef为函数类型声明一个新名称func_t。这样声明的好处是,即使你没有看到func_t的定义,也能够清楚地知道fp是一个函数指针。
在实际编程中,typedef还可以与枚举结合使用。枚举与typedef的结合使用方法和结构体类似:可以使用typedef为枚举类型color声明一个新名称color_t,然后使用这个类型就可以直接定义一个枚举变量。

2.使用typedef的优势
不同的项目,有不同的代码风格,也有不同的代码“癖好”。代码看得多了,你就会发现:有的代码里宏用得多,有的代码里typedef用得多。
1.可以让代码更加清晰简捷

如上面的程序代码所示,使用typedef,我们可以在定义一个结构体、联合、枚举变量时,省去关键字struct,让代码更加简捷。
2.增加代码的可移植性
3.比宏定义更好用
4.让复杂的指针声明更加简捷
3. typedef的作用域
和宏的全局性相比,typedef作为一个存储类关键字,是有作用域的。使用typedef声明的类型和普通变量一样,都遵循作用域规则,包括代码块作用域、文件作用域等。

宏定义在预处理阶段就已经替换完毕,是全局性的,只要保证引用它的地方在定义之后就可以了。而使用typedef声明的类型则和普通变量一样,都遵循作用域规则。上面代码的运行结果如下。

六.常量和变量
1.变量的本质
在C语言中,不同类型的数据有不同的存储方式,在内存中所占的大小不同,地址对齐方式也不相同。我们可以使用不同的数据类型来定义变量,不同类型的变量在内存中的存储方式和大小也不相同。

例如我们定义一个int型变量i,编译器会根据变量i的类型,在内存中分配4字节的存储空间;而对于定义的变量j,编译器也会根据变量j的类型,在内存中分配1字节的存储空间。从汇编语言的角度来看,汇编语言是没有数据类型的概念的,当我们使用DCB、DCD伪指令去为一个数据对象分配存储空间时,要考虑的主要是存储地址、存储大小和存储内容这3个基本要素,它和我们高级语言中的变量名、变量类型和变量值是一一对应的。变量与存储的对应关系如图7-5所示。

当我们想通过变量名去读写内存时,必须要遵循C语言标准定义的语法规则,而不是随便引用,否则就会出现问题。在C语言中,一块可以存储数据的内存区域,一般被称为对象,而操作这片内存的表达式,即引用对象的表达式,我们称之为左值。左值可以改变对象,一般放在赋值语句的左边,如a=1;这条赋值语句,表达式a就是一个左值,放在了赋值运算符的左边。我们可以通过变量名a去修改这片内存,即通过左值去改变对象。与左值相对应的是右值,即非左值表达式,一般放在赋值运算符=的右边。
我们常见的左值有变量、e[n]、e.name、p->name、*e等这些常见的表达式。需要注意的是,并不是所有的表达式都可以作为左值,如数组名、函数、枚举常量、函数调用等都不能作为左值,也不能通过它们去修改对象。如下面的程序代码。

如果你想通过上面的语句为数组赋值,你会发现编译器报编译错误,因为数组名不是左值,不能放到赋值运算符的左边。

有些引用对象的表达式既可以作为左值,也可以作为右值,如变量。一个变量作为左值时,通常表示对象的地址,我们对变量名的引用其实就是对该地址区域进行各种操作。一个变量名作为右值时,通常表示对象的内容,我们此时对变量的引用就相当于取该地址区域上的内容。

在a=1;语句中,表达式a是一个左值,代表的是一个地址,这条语句的作用就是将数据1写到变量名a表征的这片内存中,这片内存又称为对象,即我们可以通过左值来改变的对象。在b=a;这条语句中,a是右值,代表的是对象的内容,即表达式a表征的这片内存地址上的内容,直接赋值给左值b。
不同类型的变量有不同的存储方式、作用域和生命周期。在定义一个变量时,我们可以使用char、int、float、double等关键字来指定变量的类型,再加上short和long这两个整型限定符,基本上就确定了这个变量在内存中的存储空间的大小。有时候我们还可以使用一些变量修饰限定符来改变变量的存储方式,常用的修饰符有auto、register、static、extern、const、volatile、restrict、typedef等。这些修饰限定符往往会决定变量的存储位置、作用域或生命周期,所以一般也被称为存储类关键字。static关键字修饰一个局部变量,可以改变变量的存储方式,将变量的存储从栈中转移到数据段中,但不能改变变量的作用域,因为变量的作用域是由{}决定的。不同类型的变量在内存中的存储对应关系如图7-6所示。

全局变量一般存储在数据段中,使用extern关键字可以将一个全局变量的作用域扩展到另一个文件中,也可以使用static关键字将其作用域限定在本文件中。一个变量如果使用register修饰,意在告诉编译器这个变量将会被频繁地使用,如果有可能,可以将这个变量存储在CPU的寄存器中,以提高其读写效率。至于编译器会不会这样做,就要视具体情况而定了。在一个函数内定义的变量,如果没有使用其他存储类修饰符修饰,默认就是auto类型,即自动变量。自动变量存储于当前函数的栈帧内,函数中的每一个局部变量只有在函数运行时才会给其分配存储空间,在函数执行结束退出时自动释放,其生命周期只存在于函数运行期间,这也是我们称这些局部变量为自动变量的根本原因。对自动变量的读写操作不能像全局变量那样通过变量名引用,一般由栈指针SP和帧指针FP共同管理和维护。在一个函数内部定义的自动变量如果没有初始化,那么它的值将是随机的,这是因为在函数运行期间分配的存储单元地址是随机的,存储单元的数据也是随机的。如果我们没有注意到这些细节,未初始化而直接使用,就可能导致程序出现意想不到的错误。
我们在程序中,定义变量的目的,就是方便对存储在内存中的数据进行读写,不是直接通过地址,而是通过变量名来访问内存。编译器根据我们定义的变量类型,会在内存中分配合适大小的存储空间和地址对齐。变量名的本质,其实就是一段内存存储空间的别名,通过变量名可以直接对这段内存进行读写。
2.常量存储
对于C程序中定义的每一个变量,编译器都会根据变量的类型在内存中为它分配合适大小的存储空间:可以分配在数据段中,也可以分配在栈中。在一个C程序中,除了变量,还有很多常量和常量表达式,它们在内存中是如何存储的呢?
- #include
- #define HELLO "world!\n"
- char *p = "hello ubuntu!\n";
- int main(void)
- {
- char c_val = 'A';
- printf("hello %s",HELLO);
- printf("%s",p);
- printf("c_val = %c\n",c_val);
- return 0;
- }
在上面的程序中,我们使用宏HELLO定义了一个字符串,使用指针变量p指向一个常量字符串。除此之外,在printf() 函数中还有很多打印格式的字符串,编译器在编译程序时会把它们单独放在一个叫作.rodata的只读数据段中,我们可以使用objdump命令查看它们。
-
相关阅读:
CUDA编程一、基本概念和cuda向量加法
Weblogic 反序列化命令执行漏洞(CVE-2018-2628)漏洞复现【vulhub靶场】
java设计模式之观察者设计模式的前世今生
30行python代码实现“代码雨”
农民工的下一个出路在哪里?
搜维尔科技:【案例分享】Xsens用于工业制造艺术创新设计平台
js如何定义二位数组然后转josn数据,ajax上传给php,php通过json_decode解析
火山引擎ByteHouse:4000字总结,Serverless在OLAP领域应用的五点思考
谷粒商城-消息队列
PX4代码解析(6)
- 原文地址:https://blog.csdn.net/ssz__/article/details/134022756
