-
如何在CPU上进行高效大语言模型推理
大语言模型(LLMs)已经在广泛的任务中展示出了令人瞩目的表现和巨大的发展潜力。然而,由于这些模型的参数量异常庞大,使得它们的部署变得相当具有挑战性,这不仅需要有足够大的内存空间,还需要有高速的内存传输带宽。在这篇文章中,我们提出了一种高效的方法,可以使得大语言模型的部署变得更为高效。我们支持自动化的仅限权重的 INT4 量化流程,并为此设计了一个特殊的、经过高度优化的大语言模型运行时环境,从而加速了在 CPU 上进行大语言模型推理的过程。我们的方法在多个流行的大语言模型,包括 Llama2、Llama 和 GPT-NeoX 上都展示出了广泛的适用性,并且在 CPU 上实现了极高的推理效率。相关代码已经开源,可在以下链接获取:https://github.com/intel/intel-extension-for-transformers。01
引言
大语言模型(LLMs)已经在多个领域展示出了它们卓越的性能和巨大的潜力,这一点在许多研究工作中都得到了证实。然而,要想真正发挥出这些模型的强大能力,我们需要克服一个巨大的挑战:这些模型需要巨量的参数,这不仅对内存空间提出了极高的要求,还需要有足够高的内存传输速度。
量化是一种可以减少神经网络中权重和激活函数数值精确度的技术,目的是为了降低模型推断时的计算成本。目前最常用的量化方法是 INT8 量化(Vanhoucke et al. [2011]、Han et al. [2015]、Jacob et al. [2018]),因为它在保持较高推理性能的同时,也能维持模型的准确度在一个合理的范围内。然而,激活函数中的异常值问题一直存在,这限制了 INT8 量化的更广泛应用。虽然已经有一些研究试图解决这个问题,但问题依旧存在。另一方面,FP8 是一种新出现的数据类型,虽然它引起了广泛关注,但由于硬件支持的缺乏,实际应用还不多。另外,目前越来越多的人选择只对权重进行低精度(比如 4 位)量化,而保持激活函数的高精度(比如 16 位浮点数),这样既降低了计算成本,又保证了模型的准确性。
在 4 位仅权重量化这一领域,有许多卓越的研究成果,比如 Dettmers 和他的团队、Cheng 和他的团队、Lin 和他的团队、Kim 和他的团队、Wu 和他的团队、Cheng 和他的团队等,他们的工作充分证明了这种技术在大语言模型推理方面的有效性。同时,开源社区也正在积极采纳这种低比特权重量化技术,并提供了一些基于 CPP 且基于ggml 库的实现,例如 llama.cpp 和 starcoder.cpp。这些实现主要针对 CUDA 进行了优化,可能在 CPU 上无法正常运行。因此,如何使大语言模型在 CPU 上的推理变得更加高效,成为一个亟需解决的问题。
在这篇文章里,我们介绍了一种在 CPU 上高效执行大语言模型(LLM)推断的方法。这包括了一个自动的 INT4 量化流程和一个高效的 LLM 运行环境。我们借助了Intel Neural Compressor,一个支持 INT4 量化的工具,例如 GPTQ、AWQ、TEQ 和 SignRound,来自动创建 INT4 模型。我们还参考了 ggml 库的设计,为 CPU 开发了一个支持所有主流指令集的张量库,比如 AVX2、AVX512、AVX512_VNNI 和 AMX(Advanced Matrix Extensions)。我们的测试结果显示,在使用单个 4 代 Intel® Xeon® 可扩展处理器的情况下,6B 到 20B 参数的 LLM 推断的平均延迟在 20ms 到 80ms 之间,而且准确性仅比 FP32 基线低 1%。我们的主要贡献包括:
提出了一种自动的 INT4 量化流程,并能生成准确性损失不到 1% 的高质量 INT4 模型。
设计了一个支持通用和最新深度学习加速指令集的 CPU 张量库,并利用它开发了一个高效的 LLM 推断运行环境。
我们的推断解决方案应用于覆盖 3B 到 20B 参数的流行 LLM 模型,并展示了每个令牌 20ms 到 80ms 的生成延迟,远远快于人类平均阅读速度(大约每个令牌 200ms)。
本文接下来的部分安排如下:第 2 节介绍了包括 INT4 量化和推断在内的方法;第 3 节概述了实验设置,展示了准确性和性能结果,并讨论了性能调优;第 4 节给出了总结和未来工作的方向。
02
实践方法
在本节中,我们要介绍一种包含两个主要部件的方法:自动的 INT4 量化流程和一个高效的 LLM 运行环境,如图 1 所展示的。接下来的几节将为您详细解释这两部分。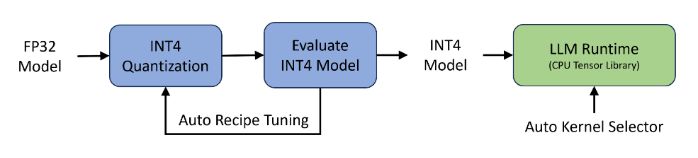 图 1: 左边是自动 INT4 量化流程的部分,右边是为高效 LLM 推理设计的简化运行环境。
图 1: 左边是自动 INT4 量化流程的部分,右边是为高效 LLM 推理设计的简化运行环境。2.1 自动 INT4 量化流程
自动的 INT4 量化流程是基于 Intel Neural Compressor,这是一个流行的用于深度学习框架的量化工具,进行开发的。这个工具已经支持了一系列主流的 INT4 量化方法,例如 GPTQ、SignRound、AWQ、TEQ 和 RTN (最近舍入)。我们的自动量化流程允许在不同的量化方法、不同的粒度(按通道或按组)和不同的组大小(从 32 到 1024)上进行调整。每种方法都会生成一个 INT4 模型,并在流程中对其进行评估。一旦 INT4 模型达到了准确性的目标,它就会被送到 LLM 运行环境中进行性能评估。
2.2 高效的 LLM 运行环境
LLM 运行环境的目标是在 CPU 上高效地推理 LLM。图 2 描述了 LLM 运行环境中的关键组件,其中绿色部分(CPU 张量库和 LLM 优化)专门用于 LLM 推理,蓝色部分(内存管理、线程调度、算子优化和融合)是通用运行环境所需的。CPU 张量库和 LLM 优化的详细信息将在下文中进一步阐述,而通用组件则因篇幅限制在此省略。值得一提的是,这个设计非常灵活,已经包含了硬件抽象层(目前仅支持 CPU),为将来可能的扩展留出了空间,虽然如何支持其他硬件类型并不在本文的讨论范围之内。图 2: LLM 运行环境中的关键组件。为 CPU 设计的张量库我们基于cutlass 的模板设计灵感,打造了一款专为 CPU 设计的张量库,用于处理线性代数的子程序。这个库特别支持 x86 CPU 上的 INT4 核心操作,详细信息可参见表 1(点击链接查看)。值得一提的是,AMX 技术在最新的 Intel Xeon 可扩展处理器上得到了支持,而 VNNI 技术则在 Intel 和 AMD 的 CPU 上都能使用。
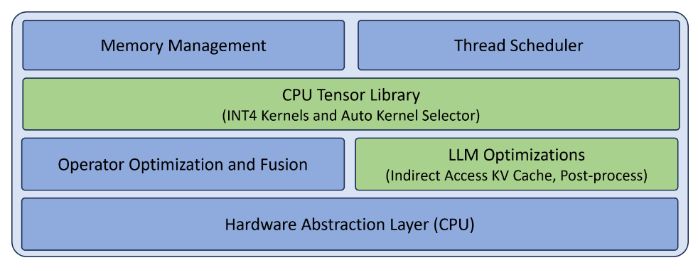 表 1:由 CPU 张量库提供支持的操作类型一览表,包括输入/输出的数据类型,计算过程中的数据类型,以及使用的指令集架构(ISA)。这个库还支持输入数据的动态量化,并可以根据批量大小或者输入通道进行分组,同时在权重量化方面也支持对称和非对称两种方案。
表 1:由 CPU 张量库提供支持的操作类型一览表,包括输入/输出的数据类型,计算过程中的数据类型,以及使用的指令集架构(ISA)。这个库还支持输入数据的动态量化,并可以根据批量大小或者输入通道进行分组,同时在权重量化方面也支持对称和非对称两种方案。对大语言模型(LLM)的优化
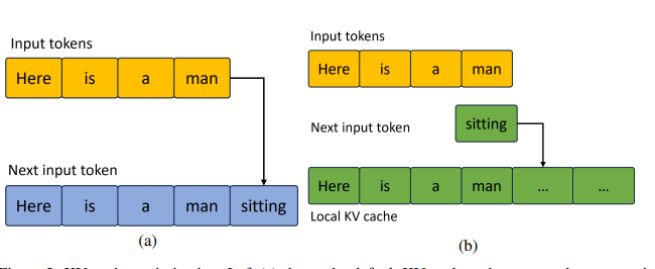
最近开发的大语言模型(LLM)通常都是基于 Transformer 架构的仅解码器模型,可以参考 Vaswani 等人在 2017 年的工作(点击链接查看原文)。在这些模型中,由于下一个词的生成特性,KV 缓存的性能变得尤为关键。我们在图 3(点击链接查看)中详细展示了这方面的优化工作。图 3:KV 缓存的优化展示。左图 (a) 展示了传统的 KV 缓存方式,每生成一个新词,就需要为所有词重新分配内存(这个例子中一共有 5 个词);右图 (b) 则展示了我们优化后的 KV 缓存,通过预先分配好 KV 内存,并且每次只更新新生成的词,从而提高了效率。
03
结果展示
3.1 实验布局
为了全面展示效果,我们精选了一系列极受欢迎的大语言模型(LLMs),这些模型涵盖了各种架构,参数规模从 7B 到 20B 不等。我们选用了lm-evaluation-harness 提供的开放数据集,评估了 FP32 和 INT4 两种模型的准确率,其中包括了来自不同研究的数据集,如 Paperno 等人 2016 年提出的 lambada,Zellers 等人 2019 年的 hellaswag,Sakaguchi 等人 2021 年的 winogrande,以及 Bisk 等人 2020 年的 piqa,当然还有 wikitext 数据集。为了检验性能,我们在第四代 Intel® Xeon® 可扩展处理器上测量了生成下一个 token 所需的时间,这些处理器可在像 AWS 这样的公共云服务上找到。
3.2 准确率评估
我们在上述数据集上进行了准确率评估,并在表格2 中展示了平均准确率结果。从表格中可以看出,INT4 模型的准确率与 FP32 模型相差无几,相对于 FP32 基准,其准确率损失在 1% 之内。
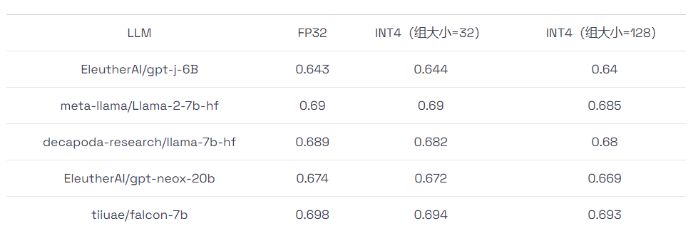 表 2:INT4 和 FP32 模型准确率对比。INT4 模型有两种设置,组大小分别为 32 和 128。
表 2:INT4 和 FP32 模型准确率对比。INT4 模型有两种设置,组大小分别为 32 和 128。3.3 性能评估
我们利用 LLM 运行时和广受欢迎的 ggml 开源实现,对生成下一个词的速度进行了测试。表格3 显示了在输入和输出词各为 32 个的情况下的处理时间。需要注意的是,在测试过程中,基于 ggml 的方法只支持将 32 个词作为一个处理组。
 表 3:使用 LLM 运行时和基于 ggml 的方法进行的 INT4 性能测试。在组大小为 128 的情况下,LLM 运行时的性能最多可以比基于 ggml 的方法高出 1.6 倍,在组大小为 32 的情况下可以高出 1.3 倍。
表 3:使用 LLM 运行时和基于 ggml 的方法进行的 INT4 性能测试。在组大小为 128 的情况下,LLM 运行时的性能最多可以比基于 ggml 的方法高出 1.6 倍,在组大小为 32 的情况下可以高出 1.3 倍。3.4 思考与讨论
虽然我们证明了 LLM 运行时相对于基于 ggml 的方法有明显的性能优势,但仍有提升空间,比如通过调整 LLM 运行时的线程调度和 CPU 张量库的阻塞策略来进一步优化性能。
04
总结与展望
我们提出了一种端到端的 INT4 LLM 推理方案,包括自动的 INT4 模型量化和高效的 LLM 运行时。我们在多个流行的 LLM 模型上验证了这一方案的通用性,并在 CPU 上展示了其相较于开源解决方案的性能优势。展望未来,我们计划对 CPU 张量库进行进一步的优化,并扩展 Hugging Face transformer API 以支持 INT4 LLM 推理,为开源社区贡献我们的力量。此外,鉴于 CPU 的普及,我们还计划将这一方案应用到个人电脑上,以满足不断增长的人工智能内容生成需求,并推动个人电脑上的生成式 AI 发展。
-
相关阅读:
ragflow 大模型RAG知识库使用案例
RabbitMQ
MySQL笔记-07 常用函数
零基础自学javase黑马课程第六天
UE4 小知识【不断更新中】
Linux编程:定时器setitimer
pytorch_神经网络构建3
减轻压力保护脊椎,上学路上更轻松,Deuter多特护脊减负双肩背包体验
自学Python 66 Tkinter开发基础
华为数通方向HCIP-DataCom H12-821题库(单选题:261-280)
- 原文地址:https://blog.csdn.net/specssss/article/details/134252343