-
十大排序算法C++实现
分类
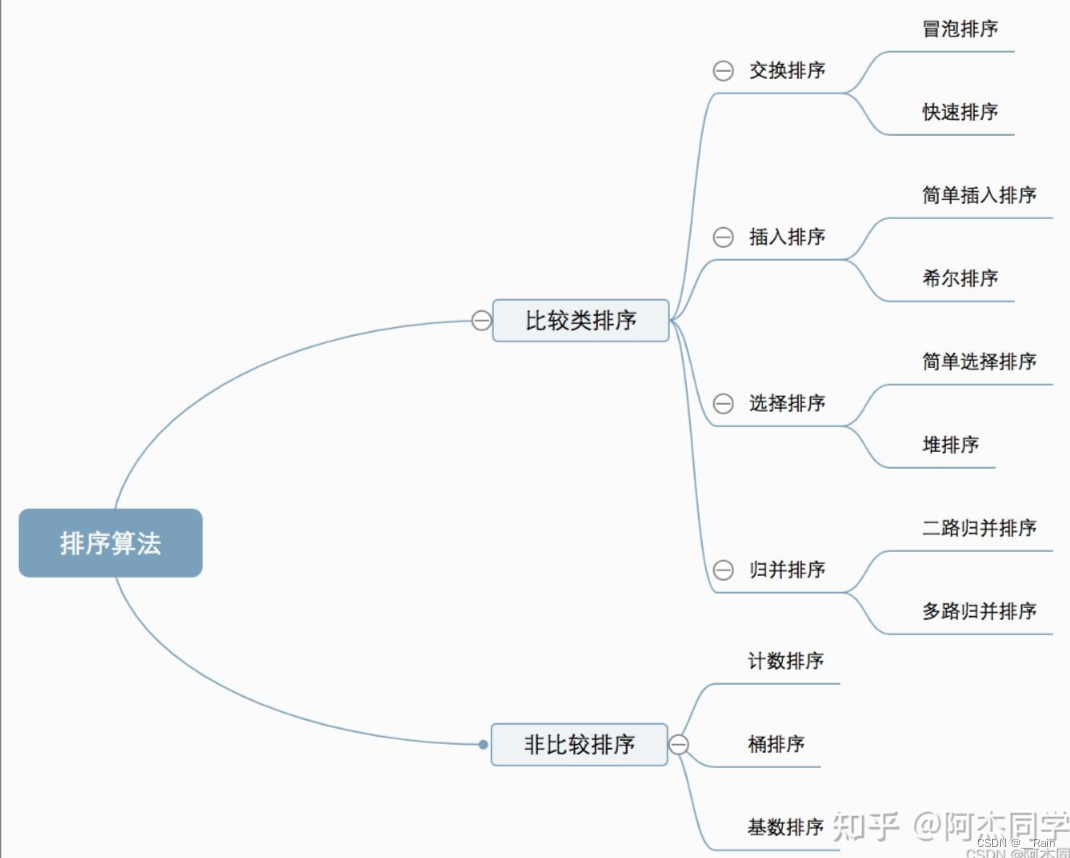
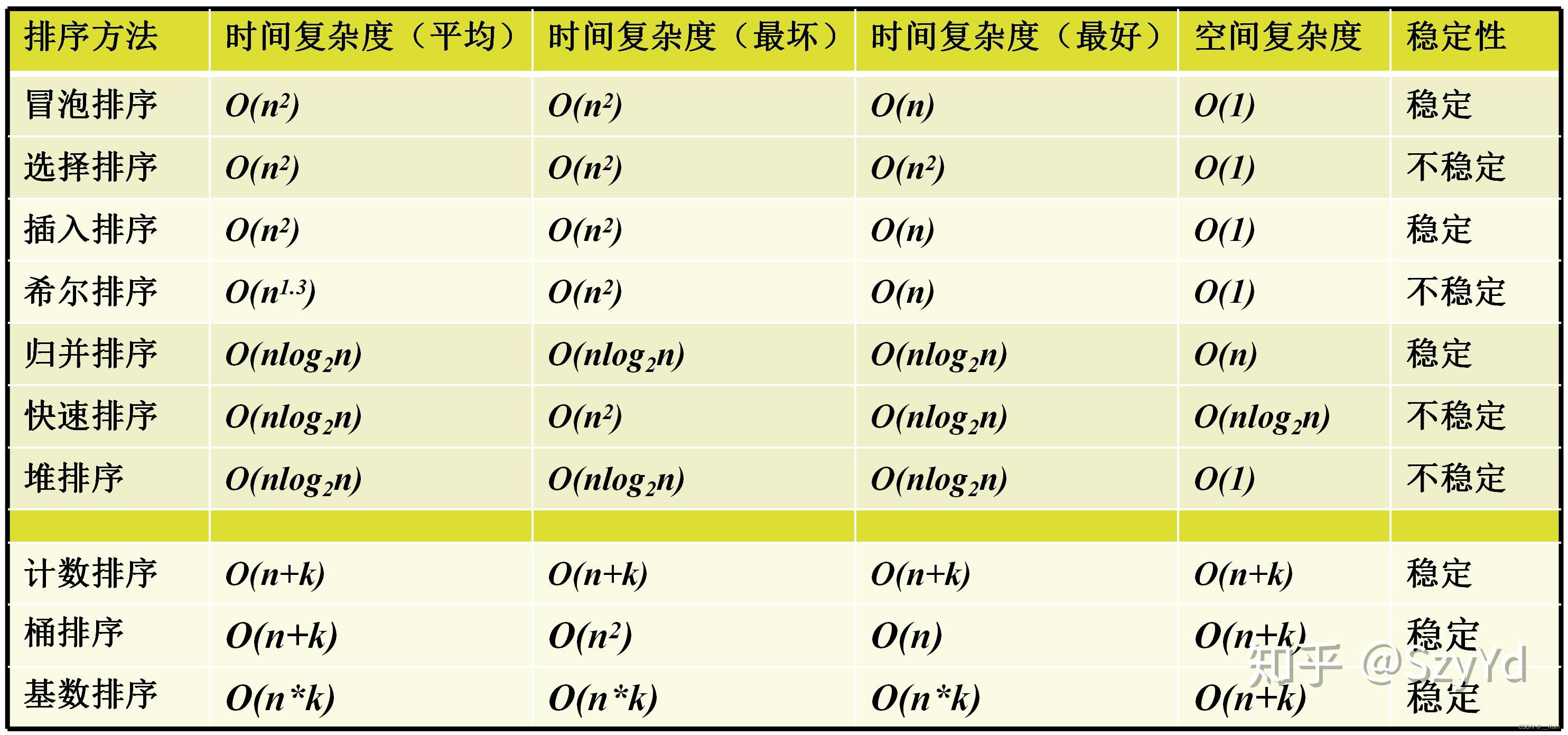
复杂度
排序稳定性定义:
假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,A1=A2,且A1在A2之前,而在排序后的序列中,A1仍在A2之前,则称这种排序算法是稳定的;否则称为不稳定的。
原理
C++代码实现
#include#include #include #include template<class T> void swap(T &a, T &b) { T tmp = a;a = b;b = tmp; } template<class T> void print(std::vector<T> &v) { for(auto x : v) std::cout << x << " "; std::cout << std::endl; } // 1.冒泡排序 // 算法描述:比较相邻的元素,如果第一个比第二个大,就交换它们两个; // 对每一对相邻元素作同样的工作,从第一对到最后一对,这样在最后的元素应该会是最大的数 // 针对所有的元素重复以上的步骤,除了最后一个; // 重复步骤 1~3,直到排序完成 void BubbleSort(std::vector<int> &v, int n) { bool flag; for(int i = 0; i < n - 1; ++i) { flag = true; for(int j = 1; j < n - i; ++j) { if(v[j] < v[j-1]) { swap(v[j], v[j-1]); flag = false; } } if(flag) break; } print(v); } // 2.插入排序 // 算法描述:把区间分为左边已排序和右边未排序,初始已排序区间只有一个元素,就是数组第一个 // 每轮针对未排序区间的第一个元素,在已排序区间里找到合适的位置插入并保证数据一直有序 void InsertSort(std::vector<int> &v, int n) { for(int i = 1; i < n; ++i) { for(int j = i; j > 0 && v[j] < v[j-1]; --j) { swap(v[j], v[j-1]); } } } // 3.选择排序 // 算法描述:把区间分为左边已排序和右边未排序, 初始已排序区间没有元素 // 每轮从未排序区间中找到最小值,然后置换到已排序区间的末尾 void SelectSort(std::vector<int> &v, int n) { int Min_pos; for(int i = 0; i < n - 1; ++i) { Min_pos = i; for(int j = i; j < n; ++j) { if(v[Min_pos] > v[j]) Min_pos = j; } swap(v[i], v[Min_pos]); } print(v); } // 4. 堆排序 O(nlogn) // 算法描述:利用堆这种数据结构所涉设计的一种排序算法。堆积是一个近似完全二叉树的结构 // 并同时满足堆积的性质:即子节点的键值或索引总是小于(或者大于)它的父节点。 // 堆排序可以用到上一次排序的结果,所以不像其他一般的排序方法一样,每次都要进行 n-1 此的比较 void Heapify(std::vector<int> &v, int n, int i) { // 维护堆的性质 while(1) { // 循环代替递归,调整节点i位置 int Max_pos = i; // 判断节点 i 是否满足大顶堆的性质 if(i * 2 + 1 < n && v[Max_pos] < v[i * 2 + 1]) Max_pos = i * 2 + 1; if(i * 2 + 2 < n && v[Max_pos] < v[i * 2 + 2]) Max_pos = i * 2 + 2; if(Max_pos == i) break; // 节点 i 满足性质 swap(v[i], v[Max_pos]); // 将Max值上浮,i节点下沉,大顶堆 i = Max_pos; // 继续调整 } } void HeapSort(std::vector<int> &v, int n) { // 1. 建堆 复杂度O(n) ,从完全二叉树的末端的父节点开始维护堆的性质 for(int i = (n - 1) / 2; i >= 0; --i) { Heapify(v, n, i); } std::cout << v[0] << std::endl; // 2. 进行堆排序, 将完全二叉树末端的元素与堆顶元素交换,然后删除完全二叉树末端的节点 // 不断重复上述操作,直至堆中只有一个元素 // 排序过程中,就是从数组末端,不断放入当前堆顶的元素 // 因此使用大顶堆排序出来就是升序 while(n > 1) { swap(v[0], v[n-1]); --n; Heapify(v, n, 0); // 对0号节点进行下沉调整,维护小顶堆性质 } print(v); } // 5. 希尔排序 也称递减增量排序 // 算法描述:通过不断缩小增量进行插入排序,算法的最后一步就是普通的插入排序 // 就是取越来越小的步长进行插入排序,这样在最后步长为 1 的时候,只需要调整很少的几次就可以完成 // 对插入排序的改进 可以让一个元素可以一次性地朝最终位置前进一大步 void ShellSort(std::vector <int> &v, int n) { for(int len = n / 2; len >= 1; len /= 2) { for(int i = len; i < n; ++i) { for(int j = i; j - len >= 0 && v[j - len] > v[j]; j -= len) { swap(v[j - len], v[j]); } } } print(v); } // 6. 计数排序 // 算法描述:先确定数据范围range,然后统计每个数字的个数,然后依次输出即可得到有序序列 // 适用范围:数据范围比较集中且为整数序列 void CountSort(std::vector<int> &v, int n) { // 1.计算元素范围 int Max = v[0], Min = v[0]; for(auto x : v) { if(x < Min) Min = x; if(x > Max) Max = x; } // 2.统计元素个数 int range = Max - Min + 1; std::vector <int> c(range, 0); // 统计数组 for(auto x : v) c[x - Min]++; // 映射一下 // 如果不考虑排序稳定性, 在这就可以直接从小到大按个数输出了 // 保证其稳定性需要继续操作 // 3.求统计数组前缀和,此时的 c[x]-1 就等于元素x在排序完的序列中的最大位置 for(int i = 1; i < range; ++i) c[i] += c[i-1]; // 4.倒序遍历原始数据,从统计数组中找到正确位置并输出 std::vector <int> tmp_v(v); for(int i = n - 1; i >= 0; --i) { int x = tmp_v[i] - Min; // 得到映射值 v[c[x] - 1] = tmp_v[i]; // 在 c[x]-1 的位置上填上 tmp_v[i] --c[x]; // 下个tmp_v[i]要在第c[x]-1个位置左边填上 } print(v); } // 7. 桶排序 // 当数列取值范围过大,或者不是整数的时候,就无法用计数排序了 // 类似于计数排序需要创建统计数组,桶排序需要创建若干个桶 // 算法描述:分治的思想 template<class T> void MergeSort(std::vector <T> &v, int l, int r); // 提前声明归并排序类模板 void BucketSort(std::vector <double> &v, int n) { // 1.确定数列的范围 double Max = v[0], Min = v[0]; for(auto x : v) { if(x < Min) Min = x; if(x > Max) Max = x; } // 2.初始化桶 int bknum = n; // 一般创建的桶数量等于原始数列的元素数量 std::vector<std::vector<double> > bk_list(bknum); // 除了最后一个桶只包含数列最大值,其余的桶均分最大值和最小值的差值. 按照比例确定 // 桶的区间范围 = (最大值-最小值) / (桶的数量 - 1) // 3.把元素都放入桶中 double bk_range = (Max - Min) / (bknum - 1); for(auto x : v) { // num = (x-Min) 除以区间跨度 int num = (int)((x - Min) / bk_range); bk_list[num].emplace_back(x); } // 4. 对桶内部排序 可以采用归并排序,也可以采用快速排序之类的 for(int i = 0; i < bknum; ++i) { MergeSort(bk_list[i], 0, bk_list[i].size() - 1); } int j = 0; for(auto &x : bk_list) { for(auto &d : x) { v[j++] = d; } } print(v); } // 8. 基数排序 // 针对手机号,英文单词等复杂元素的排序 // 算法描述:把排序工作拆分成多个阶段,每一个阶段只根据一个字符进行计数排序,一共排序k轮 (k是元素长度) // 基数排序相当于通过循环进行了多次计数排序 void RadixSort(std::vector <std::string> &v, int n) { int Max = 0; for(auto s : v) if(s.size() > Max) Max = s.size(); std::vector <std::string> tmp_v(n); // 如果要对序列进行排序,k 应该从个位开始枚举 for(int k = Max - 1; k >= 0; --k) { // 进行计数排序 std::vector <int> c(128, 0); // 统计所有字符串的第k位 for(int i = 0; i < n; ++i) { int x = '0'; // 先假设需要补 0 if(k < v[i].size()) x = v[i][k]; // 判断一下字符是否有 k 位 c[x]++; } for(int i = 1; i < c.size(); ++i) c[i] += c[i-1]; // 倒序找到正确位置并输出,保证稳定性 for(int i = n - 1; i >= 0; --i) { int x = '0'; if(k < v[i].size()) x = v[i][k]; tmp_v[c[x] - 1] = v[i]; c[x]--; } v.swap(tmp_v); } print(v); } // 9.快排 O(nlogn),最坏 O(n^2) // 算法描述: 选定Pivot中心轴,在原来的元素里根据这个枢纽分 // 将小于Pviot的元素放到Pivot的左边, 将大于Pviot的元素放到Pivot的右边 // 递归处理左右子序列 void QuickSort(std::vector<int> &v, int l, int r) { if(l >= r) return; int first = l, last = r, pivot = v[l]; while(first < last) { while(first < last && v[last] >= pivot) --last;//将小于piv的放到左边 v[first] = v[last]; while(first < last && v[first] <= pivot) ++first;//将大于piv的放到右边 v[last] = v[first]; } v[first] = pivot; // 更新pivot QuickSort(v, l, first); QuickSort(v, first + 1, r); } // 10.归并排序 O(nlogn) 稳定的排序算法,它不是原地排序算法 // 算法描述:将两个游标 i 和 j,分别指向 v[l, mid] 和 v[mid+1, r] 的第一个元素。比较这两个元素 // 如果 v[i] - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
-
相关阅读:
vue下载Excel文件
机器学习(三十四):可视化决策树的四个方法
网络安全实战,如何利用Python监测漏洞
abc262-D(dp)
动态规划:最长公共子序列
ArrayList源码解析
使用自己的数据集测试Unbiased Mean Teacher for Cross-domain Object Detection
『Halcon与C#混合编程』007_SetPart、GetImageSize、图像原比例显示
[PAT练级笔记] 03 Basic Level 1004
IPIDEA的使用方式
- 原文地址:https://blog.csdn.net/cosx_/article/details/134249617
