-
二十、泛型(1)
本章概要
- 基本概念
- 与 C++ 的比较
- 简单泛型
- 一个元组类库
- 一个堆栈类
- RandomList
基本概念
普通的类和方法只能使用特定的类型:基本数据类型或类类型。如果编写的代码需要应用于多种类型,这种严苛的限制对代码的束缚就会很大。
多态是一种面向对象思想的泛化机制。你可以将方法的参数类型设为基类,这样的方法就可以接受任何派生类作为参数,包括暂时还不存在的类。这样的方法更通用,应用范围更广。在类内部也是如此,在任何使用特定类型的地方,基类意味着更大的灵活性。除了
final类(或只提供私有构造函数的类)任何类型都可被扩展,所以大部分时候这种灵活性是自带的。拘泥于单一的继承体系太过局限,因为只有继承体系中的对象才能适用基类作为参数的方法中。如果方法以接口而不是类作为参数,限制就宽松多了,只要实现了接口就可以。这给予调用方一种选项,通过调整现有的类来实现接口,满足方法参数要求。接口可以突破继承体系的限制。
即便是接口也还是有诸多限制。一旦指定了接口,它就要求你的代码必须使用特定的接口。而我们希望编写更通用的代码,能够适用“非特定的类型”,而不是一个具体的接口或类。
这就是泛型的概念,是 Java 5 的重大变化之一。泛型实现了_参数化类型_,这样你编写的组件(通常是集合)可以适用于多种类型。“泛型”这个术语的含义是“适用于很多类型”。编程语言中泛型出现的初衷是通过解耦类或方法与所使用的类型之间的约束,使得类或方法具备最宽泛的表达力。随后你会发现 Java 中泛型的实现并没有那么“泛”,你可能会质疑“泛型”这个词是否合适用来描述这一功能。
如果你从未接触过参数化类型机制,你会发现泛型对 Java 语言确实是个很有益的补充。在你实例化一个类型参数时,编译器会负责转型并确保类型的正确性。这是一大进步。
然而,如果你了解其他语言(例如 C++ )的参数化机制,你会发现,Java 泛型并不能满足所有的预期。使用别人创建好的泛型相对容易,但是创建自己的泛型时,就会遇到很多意料之外的麻烦。
这并不是说 Java 泛型毫无用处。在很多情况下,它可以使代码更直接更优雅。不过,如果你见识过那种实现了更纯粹的泛型的编程语言,那么,Java 可能会令你失望。本章会介绍 Java 泛型的优点与局限。我会解释 Java 的泛型是如何发展成现在这样的,希望能够帮助你更有效地使用这个特性。
与 C++ 的比较
Java 的设计者曾说过,这门语言的灵感主要来自 C++ 。尽管如此,学习 Java 时基本不用参考 C++ 。
但是,Java 中的泛型需要与 C++ 进行对比,理由有两个:首先,理解 C++ 模板(泛型的主要灵感来源,包括基本语法)的某些特性,有助于理解泛型的基础理念。同时,非常重要的一点是,你可以了解 Java 泛型的局限是什么,以及为什么会有这些局限。最终的目标是明确 Java 泛型的边界,让你成为一个程序高手。只有知道了某个技术不能做什么,你才能更好地做到所能做的(部分原因是,不必浪费时间在死胡同里)。
第二个原因是,在 Java 社区中,大家普遍对 C++ 模板有一种误解,而这种误解可能会令你在理解泛型的意图时产生偏差。
因此,本章中会介绍少量 C++ 模板的例子,仅当它们确实可以加深理解时才会引入。
简单泛型
促成泛型出现的最主要的动机之一是为了创建_集合类_,参见 集合 章节。集合用于存放要使用到的对象。数组也是如此,不过集合比数组更加灵活,功能更丰富。几乎所有程序在运行过程中都会涉及到一组对象,因此集合是可复用性最高的类库之一。
我们先看一个只能持有单个对象的类。这个类可以明确指定其持有的对象的类型:
class Automobile { } public class Holder1 { private Automobile a; public Holder1(Automobile a) { this.a = a; } Automobile get() { return a; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
这个类的可复用性不高,它无法持有其他类型的对象。我们可不希望为碰到的每个类型都编写一个新的类。
在 Java 5 之前,我们可以让这个类直接持有
Object类型的对象:// generics/ObjectHolder.java public class ObjectHolder { private Object a; public ObjectHolder(Object a) { this.a = a; } public void set(Object a) { this.a = a; } public Object get() { return a; } public static void main(String[] args) { ObjectHolder h2 = new ObjectHolder(new Automobile()); Automobile a = (Automobile)h2.get(); h2.set("Not an Automobile"); String s = (String)h2.get(); h2.set(1); // 自动装箱为 Integer Integer x = (Integer)h2.get(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
现在,
ObjectHolder可以持有任何类型的对象,在上面的示例中,一个ObjectHolder先后持有了三种不同类型的对象。一个集合中存储多种不同类型的对象的情况很少见,通常而言,我们只会用集合存储同一种类型的对象。泛型的主要目的之一就是用来约定集合要存储什么类型的对象,并且通过编译器确保规约得以满足。
因此,与其使用
Object,我们更希望先指定一个类型占位符,稍后再决定具体使用什么类型。要达到这个目的,需要使用_类型参数_,用尖括号括住,放在类名后面。然后在使用这个类时,再用实际的类型替换此类型参数。在下面的例子中,T就是类型参数:public class ObjectHolder { private Object a; public ObjectHolder(Object a) { this.a = a; } public void set(Object a) { this.a = a; } public Object get() { return a; } public static void main(String[] args) { ObjectHolder h2 = new ObjectHolder(new Automobile()); Automobile a = (Automobile) h2.get(); h2.set("Not an Automobile"); String s = (String) h2.get(); h2.set(1); // 自动装箱为 Integer Integer x = (Integer) h2.get(); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
创建
GenericHolder对象时,必须指明要持有的对象的类型,将其置于尖括号内,就像main()中那样使用。然后,你就只能在GenericHolder中存储该类型(或其子类,因为多态与泛型不冲突)的对象了。当你调用get()取值时,直接就是正确的类型。这就是 Java 泛型的核心概念:你只需告诉编译器要使用什么类型,剩下的细节交给它来处理。
你可能注意到
h3的定义非常繁复。在=左边有GenericHolder, 右边又重复了一次。在 Java 5 中,这种写法被解释成“必要的”,但在 Java 7 中设计者修正了这个问题(新的简写语法随后成为备受欢迎的特性)。以下是简写的例子:GenericHolder.java
public class GenericHolder<T> { private T a; public GenericHolder() { } public void set(T a) { this.a = a; } public T get() { return a; } public static void main(String[] args) { GenericHolder<Automobile> h3 = new GenericHolder<Automobile>(); h3.set(new Automobile()); // type checked Automobile a = h3.get(); // No cast needed //- h3.set("Not an Automobile"); // Error //- h3.set(1); // Error } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
Diamond.java
class Bob { } public class Diamond<T> { public static void main(String[] args) { GenericHolder<Bob> h3 = new GenericHolder<>(); h3.set(new Bob()); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
注意,在
h3的定义处,=右边的尖括号是空的(称为“钻石语法”),而不是重复左边的类型信息。在本书剩余部分都会使用这种语法。一般来说,你可以认为泛型和其他类型差不多,只不过它们碰巧有类型参数罢了。在使用泛型时,你只需要指定它们的名称和类型参数列表即可。
一个元组类库
有时一个方法需要能返回多个对象。而 return 语句只能返回单个对象,解决方法就是创建一个对象,用它打包想要返回的多个对象。当然,可以在每次需要的时候,专门创建一个类来完成这样的工作。但是有了泛型,我们就可以一劳永逸。同时,还获得了编译时的类型安全。
这个概念称为_元组_,它是将一组对象直接打包存储于单一对象中。可以从该对象读取其中的元素,但不允许向其中存储新对象(这个概念也称为 数据传输对象 或 信使 )。
通常,元组可以具有任意长度,元组中的对象可以是不同类型的。不过,我们希望能够为每个对象指明类型,并且从元组中读取出来时,能够得到正确的类型。要处理不同长度的问题,我们需要创建多个不同的元组。下面是一个可以存储两个对象的元组:
public class Tuple2<A, B> { public final A a1; public final B a2; public Tuple2(A a, B b) { a1 = a; a2 = b; } public String rep() { return a1 + ", " + a2; } @Override public String toString() { return "(" + rep() + ")"; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
构造函数传入要存储的对象。这个元组隐式地保持了其中元素的次序。
初次阅读上面的代码时,你可能认为这违反了 Java 编程的封装原则。
a1和a2应该声明为 private,然后提供getFirst()和getSecond()取值方法才对呀?考虑下这样做能提供的“安全性”是什么:元组的使用程序可以读取a1和a2然后对它们执行任何操作,但无法对a1和a2重新赋值。例子中的final可以实现同样的效果,并且更为简洁明了。另一种设计思路是允许元组的用户给
a1和a2重新赋值。然而,采用上例中的形式无疑更加安全,如果用户想存储不同的元素,就会强制他们创建新的Tuple2对象。我们可以利用继承机制实现长度更长的元组。添加更多的类型参数就行了:
Tuple3.java
public class Tuple3<A, B, C> extends Tuple2<A, B> { public final C a3; public Tuple3(A a, B b, C c) { super(a, b); a3 = c; } @Override public String rep() { return super.rep() + ", " + a3; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
Tuple4.java
public class Tuple4<A, B, C, D> extends Tuple3<A, B, C> { public final D a4; public Tuple4(A a, B b, C c, D d) { super(a, b, c); a4 = d; } @Override public String rep() { return super.rep() + ", " + a4; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
Tuple5.java
public class Tuple5<A, B, C, D, E> extends Tuple4<A, B, C, D> { public final E a5; public Tuple5(A a, B b, C c, D d, E e) { super(a, b, c, d); a5 = e; } @Override public String rep() { return super.rep() + ", " + a5; } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
演示需要,再定义两个类:
Amphibian.java
// generics/Amphibian.java public class Amphibian {}- 1
- 2
Vehicle.java
public class Vehicle { }- 1
- 2
使用元组时,你只需要定义一个长度适合的元组,将其作为返回值即可。注意下面例子中方法的返回类型:
public class TupleTest { static Tuple2<String, Integer> f() { // 47 自动装箱为 Integer return new Tuple2<>("hi", 47); } static Tuple3<Amphibian, String, Integer> g() { return new Tuple3<>(new Amphibian(), "hi", 47); } static Tuple4<Vehicle, Amphibian, String, Integer> h() { return new Tuple4<>(new Vehicle(), new Amphibian(), "hi", 47); } static Tuple5<Vehicle, Amphibian, String, Integer, Double> k() { return new Tuple5<>(new Vehicle(), new Amphibian(), "hi", 47, 11.1); } public static void main(String[] args) { Tuple2<String, Integer> ttsi = f(); System.out.println(ttsi); // ttsi.a1 = "there"; // 编译错误,因为 final 不能重新赋值 System.out.println(g()); System.out.println(h()); System.out.println(k()); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
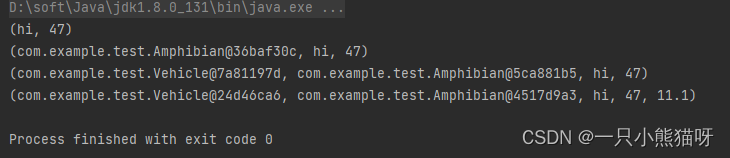
有了泛型,你可以很容易地创建元组,令其返回一组任意类型的对象。
通过
ttsi.a1 = "there"语句的报错,我们可以看出,final 声明确实可以确保 public 字段在对象被构造出来之后就不能重新赋值了。在上面的程序中,
new表达式有些啰嗦。本章稍后会介绍,如何利用 泛型方法 简化它们。一个堆栈类
接下来我们看一个稍微复杂一点的例子:堆栈。在 集合 一章中,我们用
LinkedList实现了onjava.Stack类。在那个例子中,LinkedList本身已经具备了创建堆栈所需的方法。Stack是通过两个泛型类Stack和LinkedList的组合来创建。我们可以看出,泛型只不过是一种类型罢了(稍后我们会看到一些例外的情况)。这次我们不用
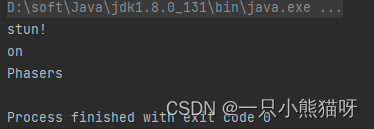
LinkedList来实现自己的内部链式存储机制。// 用链式结构实现的堆栈 public class LinkedStack<T> { private static class Node<U> { U item; Node<U> next; Node() { item = null; next = null; } Node(U item, Node<U> next) { this.item = item; this.next = next; } boolean end() { return item == null && next == null; } } private Node<T> top = new Node<>(); // 栈顶 public void push(T item) { top = new Node<>(item, top); } public T pop() { T result = top.item; if (!top.end()) { top = top.next; } return result; } public static void main(String[] args) { LinkedStack<String> lss = new LinkedStack<>(); for (String s : "Phasers on stun!".split(" ")) { lss.push(s); } String s; while ((s = lss.pop()) != null) { System.out.println(s); } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
输出结果:
内部类
Node也是一个泛型,它拥有自己的类型参数。这个例子使用了一个 末端标识 (end sentinel) 来判断栈何时为空。这个末端标识是在构造
LinkedStack时创建的。然后,每次调用push()就会创建一个Node对象,并将其链接到前一个Node对象。当你调用pop()方法时,总是返回top.item,然后丢弃当前top所指向的Node,并将top指向下一个Node,除非到达末端标识,这时就不能再移动top了。如果已经到达末端,程序还继续调用pop()方法,它只能得到null,说明栈已经空了。RandomList
作为容器的另一个例子,假设我们需要一个持有特定类型对象的列表,每次调用它的
select()方法时都随机返回一个元素。如果希望这种列表可以适用于各种类型,就需要使用泛型:import java.util.*; import java.util.stream.*; public class RandomList<T> extends ArrayList<T> { private Random rand = new Random(47); public T select() { return get(rand.nextInt(size())); } public static void main(String[] args) { RandomList<String> rs = new RandomList<>(); Arrays.stream("The quick brown fox jumped over the lazy brown dog".split(" ")).forEach(rs::add); IntStream.range(0, 11).forEach(i -> System.out.print(rs.select() + " ")); } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
输出结果:

RandomList继承了ArrayList的所有方法。本例中只添加了select()这个方法。 - 基本概念
-
相关阅读:
JS逆向系列之某瓜数据解密
docker 记录下go用alpine作为基础镜像出现 no found的问题
文件包含漏洞培训
通过U盘重装Win10教程图解
数组(1)
GAM注意力机制
八股文第十三天
如何用 GPT-4 帮你写游戏(以24点游戏举例)
k8s之配置资源管理
LeetCode第53题:最大子数组和【python 5种算法】
- 原文地址:https://blog.csdn.net/GXL_1012/article/details/134209327
