-
大数据毕业设计选题推荐-智慧小区大数据平台-Hadoop-Spark-Hive
✨作者主页:IT研究室✨
个人简介:曾从事计算机专业培训教学,擅长Java、Python、微信小程序、Golang、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。
☑文末获取源码☑
精彩专栏推荐⬇⬇⬇
Java项目
Python项目
安卓项目
微信小程序项目一、前言
随着信息技术的快速发展,智慧小区已成为城市管理的重要组成部分。智慧小区通过集成物联网、大数据、云计算等先进技术,为小区居民提供更便捷、更智能的服务,同时也为物业管理部门提供更便捷、更准确的管理手段。在这个背景下,研究智慧小区大数据平台具有重要意义。
首先,智慧小区的建设需要大数据技术的支持。传统的物业管理和服务模式已无法满足现代城市居民的需求,而智慧小区通过大数据分析可以实现对小区设备、安全、环境等各方面的实时监控和预测,为小区居民提供更好的服务,同时也为物业管理部门提供更好的管理手段。
其次,智慧小区的建设需要实现数据的共享和整合。小区各个部门和系统之间的信息孤岛现象严重,无法实现数据共享和整合,这不仅影响了各部门之间的协作效率,也影响了智慧小区的建设效果。而智慧小区大数据平台可以实现数据的共享和整合,提高各部门之间的协作效率,推动智慧小区的建设进程。虽然智慧小区的建设已经取得了一定的成果,但是现有解决方案还存在一些问题。首先,数据采集和整合的难度较大。由于小区各个部门和系统之间的数据格式和标准不统一,导致数据采集和整合的难度较大,影响了数据的质量和可靠性。其次,数据处理和分析的能力不足。现有系统主要侧重于数据的存储和管理,而对数据的处理和分析能力不足,无法充分发挥数据的价值。再次,系统之间的信息交互和共享能力较弱。由于系统之间的信息交互和共享能力较弱,导致各部门之间的协作效率低下,影响了智慧小区的建设效果。
本课题旨在研究智慧小区大数据平台的关键技术,包括数据采集、整合、处理、分析等方面,解决现有解决方案存在的问题,实现数据的共享和整合,提高各部门之间的协作效率,推动智慧小区的建设进程。同时,本课题还将探讨智慧小区大数据平台的应用场景和发展趋势,为未来智慧小区的建设提供参考和借鉴。
本课题的研究成果具有重要的实践意义和理论价值。首先,本课题的研究成果可以为智慧小区的建设提供技术支持和指导,提高小区的服务质量和居住体验。其次,本课题的研究成果可以为物业管理部门提供管理手段和决策支持,提高管理效率和水平。再次,本课题的研究成果可以为大数据技术的应用和发展提供新的思路和方法,推动大数据技术的创新和发展。
二、开发环境
- 大数据技术:Hadoop、Spark、Hive
- 开发技术:Python、Django框架、Vue、Echarts、机器学习
- 软件工具:Pycharm、DataGrip、Anaconda、VM虚拟机
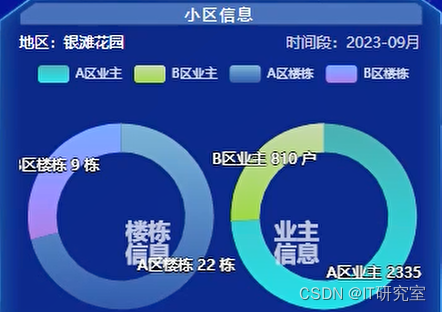
三、系统界面展示
- 智慧小区大数据平台界面展示:

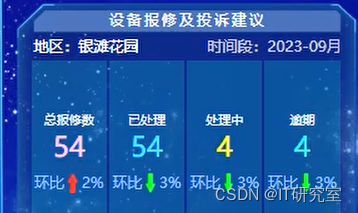
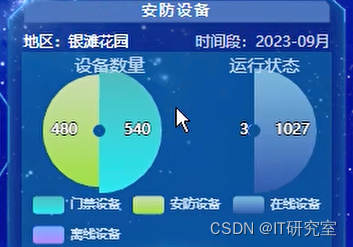
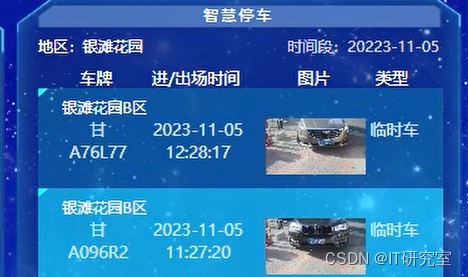
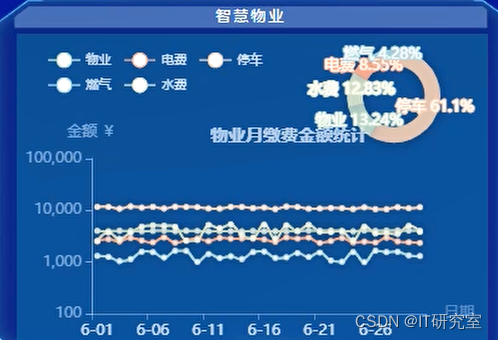
四、代码参考
- 智慧小区大数据平台项目实战代码参考:
class WangyiSpiderMiddleware: # Not all methods need to be defined. If a method is not defined, # scrapy acts as if the spider middleware does not modify the # passed objects. @classmethod def from_crawler(cls, crawler): # This method is used by Scrapy to create your spiders. s = cls() crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) return s def process_spider_input(self, response, spider): # Called for each response that goes through the spider # middleware and into the spider. # Should return None or raise an exception. return None def process_spider_output(self, response, result, spider): # Called with the results returned from the Spider, after # it has processed the response. # Must return an iterable of Request, or item objects. for i in result: yield i def process_spider_exception(self, response, exception, spider): # Called when a spider or process_spider_input() method # (from other spider middleware) raises an exception. # Should return either None or an iterable of Request or item objects. pass def process_start_requests(self, start_requests, spider): # Called with the start requests of the spider, and works # similarly to the process_spider_output() method, except # that it doesn’t have a response associated. # Must return only requests (not items). for r in start_requests: yield r def spider_opened(self, spider): spider.logger.info('Spider opened: %s' % spider.name) class WangyiDownloaderMiddleware: # Not all methods need to be defined. If a method is not defined, # scrapy acts as if the downloader middleware does not modify the # passed objects. @classmethod def from_crawler(cls, crawler): # This method is used by Scrapy to create your spiders. s = cls() crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) return s def process_request(self, request, spider): # Called for each request that goes through the downloader # middleware. # Must either: # - return None: continue processing this request # - or return a Response object # - or return a Request object # - or raise IgnoreRequest: process_exception() methods of # installed downloader middleware will be called return None def process_response(self, request, response, spider): # Called with the response returned from the downloader. # Must either; # - return a Response object # - return a Request object # - or raise IgnoreRequest return response def process_exception(self, request, exception, spider): # Called when a download handler or a process_request() # (from other downloader middleware) raises an exception. # Must either: # - return None: continue processing this exception # - return a Response object: stops process_exception() chain # - return a Request object: stops process_exception() chain pass def spider_opened(self, spider): spider.logger.info('Spider opened: %s' % spider.name)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
class MyspiderPipeline: def __init__(self): self.file = open('itcast.json','w') def process_item(self, item, spider): #item对象强转字典,该操作只能再scrapy中使用 item = dict(item) #将字典序列化 json_data = json.dumps(item,ensure_ascii=False ) + ',\n' #将数据写入文件 self.file.write(json_data) # 默认使用完管道之后需要将数据返回给引擎 return item def __del__(self): self.file.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
五、论文参考
- 计算机毕业设计选题推荐-智慧小区大数据平台论文参考:
六、系统视频
智慧小区大数据平台项目视频:
大数据毕业设计选题推荐-智慧小区大数据平台-Hadoop
结语
大数据毕业设计选题推荐-智慧小区大数据平台-Hadoop-Spark-Hive
大家可以帮忙点赞、收藏、关注、评论啦~
源码获取:私信我 -
相关阅读:
VisualSP Enterprise - September 2023 Crack
JavaScript对象:我们真的需要模拟类吗?
go-zero微服务实战系列(五、缓存代码怎么写)
kube-prometheus-stack监控k8s1.24+ docker缺少图像
springcloud学习笔记:通过openFeign实现微服务接口远程调用
编码注入
STM32——OLED菜单
zookeeper核心源码分析
vue3 Cesium 离线地图
大数据从入门到精通(超详细版)之Hive的DDL操作
- 原文地址:https://blog.csdn.net/2301_79456892/article/details/134235145
