-
前馈神经网络
此文建议看完基础篇再来,废话不多说,进入正题
目录
1.神经元
神经网络的基本组成单元为带有非线性激活函数的神经元,其结构如下图所示:

接下来对需要了解的知识进行一下复习,看标题如果觉得这块熟练的可以直接跳过,之前的博客也讲过很多次这个咯
1.1 活性值
相信看过上一篇博客的同学都知道,净活性值和活性值的区别,这里再提一次。、
第L层神经元的净输入,我们称净活性值,第L层神经元的输出,我们称为活性值。

使用pytorch计算一组输入的活性值。代码如下:
- import torch
- x = torch.rand((2, 5))
- w = torch.rand((5, 1))
- b = torch.rand((1, 1))
- z = torch.matmul(x, w) + b
- print("input x:", x)
- print("weight w:", w, "\nbias b:", b)
- print("output z:", z)
结果如下:

当然也可以用torch.nn.Linear()完成上述的步骤,更为简便代码如下:
- import torch
- x = torch.rand((2, 5))
- model = torch.nn.Linear(5, 1)
- output = model(x)
- print(output)
输出结果如下:

PS:为了方便理解,写一下torch.nn.Linear()的参数含义:
- torch.nn.Linear(in_features, # 输入的神经元个数
- out_features, # 输出神经元个数
- bias=False # 是否包含偏置
- )
这里讲解一下加权求和与仿射变换之间有什么区别和联系:
为什么要讲一下这个呢,因为作业留了,咳咳闹着玩的,因为torch.nn.Linear()是通过仿射变换实现的线性变化。首先讲一下我对定义的理解,手写深度模型大都采取的是加权求和的过程,再通过梯度下降的方法反过来优化参数,而什么是仿射变化呢,最近也在学习数字图像处理,在数字图像处理中提到,仿射变化是一种几何变换,可以在欧几里得空间中对向量进行线性变换,并加上一个平移向量。简单点说,放射变化可以通过原向量与仿射变化矩阵的乘积,形成一个新的向量,宏观可以理解为图像的对称,反转,平移等等操作,那这么两个看起来毫无关联的东西到底有什么区别和联系嘞?
就联系而言,加权求和可以看作是仿射变换的一种特殊形式。因为加权求和在一定意义上也是一种仿射变换。当我们将每个输入数据乘以一个权重系数,然后再相加时,这个过程可以看作是一个线性变换的过程。这个线性变换将每个输入数据映射到一个新的输出值,这些输出值之和就是最终的预测结果。由于这个线性变换中每个输入数据都有相应的权重系数,因此可以看作是一种特殊的仿射变换。总的来说,加权求和和仿射变换都涉及到对输入数据的线性变换,因此加权求和可以看作是仿射变换的一种特殊形式。
那有什么区别呢,通过上面的分析我们发现,最明显的是基础定义不同:加权求和是将多个输入值根据其重要性进行加权叠加,输出为一维数据;而仿射变换是在几何中,一个向量空间进行一次线性变换并接上一个平移,将一个向量空间的点映射到另一个向量空间。其次是操作过程不同:加权求和操作简单,直接将每个输入值乘以相应的权重,然后相加即可;而仿射变换需要先对输入向量进行线性变换,然后再进行平移,实现从原向量空间到目标向量空间的映射。
1.2 激活函数
常用的激活函数分为两类:S型函数和ReLU函数。
1.2.1 Sigmoid函数
Sigmoid 型函数是指一类S型曲线函数,为两端饱和函数。常用的 Sigmoid 型函数有 Logistic 函数和 Tanh 函数,数学表达式如下:
Logistic 函数:
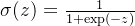
Tanh 函数:

代码实现即可视化如下:
- def logistic(x):
- return 1.0 / (1.0 + torch.exp(-x))
- def tanh(x):
- return (torch.exp(x) - torch.exp(-x)) / (torch.exp(x) + torch.exp(-x))
- z = torch.linspace(-10, 10, 10000)
- plt.figure()
- plt.plot(z.tolist(), logistic(z).tolist(), color="#e4007f", label="Logistic Function")
- plt.plot(z.tolist(), tanh(z).tolist(), color="#f19ec2", linestyle='--', label="Tanh Function")
- ax = plt.gca()
- ax.spines['top'].set_color('none')
- ax.spines['right'].set_color('none')
- # 调整坐标轴位置
- ax.spines['left'].set_position(('data', 0))
- ax.spines['bottom'].set_position(('data', 0))
- plt.legend(loc='lower right', fontsize='large')
- plt.show()
结果如下:
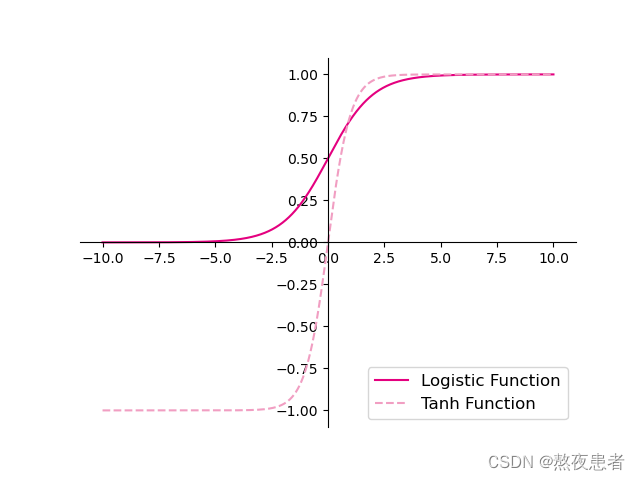
当然,Logistic函数和Tanh函数在pytorch有封装了的库函数,调用方法如下:
- import torch.nn.functional as F
- F.sigmoid(z) # Logistic函数
- F.tanh(z) # Tanh函数
- # 接收的输入可以是任何形状的张量,它可以是一个一维张量(向量)
- # 也可以是一个多维张量(矩阵或者更高维度的数据)
检测一下和我们自己手写的函数结果是否是一样的:
- import torch
- import torch.nn.functional as F
- def logistic(x):
- return 1.0 / (1.0 + torch.exp(-x))
- def tanh(x):
- return (torch.exp(x) - torch.exp(-x)) / (torch.exp(x) + torch.exp(-x))
- z = torch.linspace(-10, 10, 10000)
- print("logistic\n", torch.equal(torch.round(logistic(z), decimals=4), torch.round(F.sigmoid(z), decimals=4)))
- print("tanh\n", torch.equal(torch.round(tanh(z), decimals=4), torch.round(F.tanh(z), decimals=4)))
输出结果如下:

我们发现手写Logistic函数和和库函数F.sigmoid在保留小数后四位的时候,值是一样的,但是手写tanh函数和F.tanh函数不论保留几位都是不一样的这是为什么呢?
这主要是由于实现的误差,通过搜索资料总结了以下三点:
- 精度差异:虽然两者都应实现相同的
tanh函数,但是在浮点数计算中,由于精度限制,它们可能会有微小的差别。这些微小的差别在训练过程中可能会逐渐累积并导致较大的误差。 - 数值稳定性:在实现
tanh函数时,需要注意数值稳定性。例如,如果输入值的绝对值非常接近于1,那么直接计算tanh可能会由于浮点数表示的精度限制而导致数值不稳定。在这种情况下,使用torch.nn.functional.tanh可能会更稳定,因为它可能包含额外的数值稳定策略。 - 批量处理:
torch.nn.functional.tanh是针对批量输入设计的,可以同时处理多个输入。而手写的tanh函数通常针对单个输入进行设计。在批量处理时,这可能会导致一些细微的差异。
总结:手写Logistic函数和tanh函数可以被库函数torch.nn.functional.sigmoid和torch.nn.functional.tanh,但是在使用torch.nn.functional.tanh的时候扛干扰的效率会明显优于tanh手写函数,并且使用库函数可以有效地节省大量的时间。
1.2.2 Relu函数
常见的ReLU函数有ReLU和带泄露的ReLU(Leaky ReLU),数学表达式分别为:
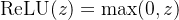
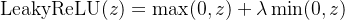 ,其中
,其中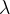 为超参数
为超参数代码如下:
- # ReLU
- def relu(z):
- return torch.maximum(z, torch.tensor(0.))
- #
- #
- # 带泄露的ReLU
- def leaky_relu(z, negative_slope=0.1):
- # 调用pytorch的int()函数将bool类型转成int类型,因此调用pytorch的int()函数来进行显式转换
- a1 = (z > 0).int() * z
- a2 = (z <= 0).int() * (negative_slope * z)
- return a1 + a2
- # 在[-10,10]的范围内生成一系列的输入值,用于绘制relu、leaky_relu的函数曲线
- z = torch.linspace(-10, 10, 10000)
- plt.figure()
- plt.plot(z.tolist(), relu(z).tolist(), color="#e4007f", label="ReLU Function")
- plt.plot(z.tolist(), leaky_relu(z).tolist(), color="#f19ec2", linestyle="--", label="LeakyReLU Function")
- ax = plt.gca()
- ax.spines['top'].set_color('none')
- ax.spines['right'].set_color('none')
- ax.spines['left'].set_position(('data', 0))
- ax.spines['bottom'].set_position(('data', 0))
- plt.legend(loc='upper left', fontsize='large')
- plt.show()
结果如下:

Relu和leaky_relu在pytorch也存在也封装了自己的函数,调用方法如下:
- torch.nn.functional.relu(input, stride=1, padding=0, dilation=1, groups=1)
- # input:输入张量。
- # stride(可选):步长,默认值为1。
- # padding(可选):在输入张量每个维度上的填充大小,默认值为0。
- # dilation(可选):膨胀率,控制元素之间的间距,默认值为1。
- # groups(可选):分组参数,默认值为1。
- torch.nn.functional.leaky_relu(input, negative_slope=0.01, name=None, **kwargs)
- # input 是输入的张量。
- # negative_slope 是 Leaky ReLU 的负斜率,默认值为 0.01。这个参数是在输入为负值时,Leaky ReLU 的梯度与 ReLU 的梯度的比例。
- # name 是这个函数的名称,如果没有指定,那么 PyTorch 会自动生成一个名称。
- # **kwargs 是其他可能的参数。
检测一下和我们自己手写的函数结果是否是一样的:
- # ReLU
- def relu(z):
- return torch.maximum(z, torch.tensor(0.))
- #
- #
- # 带泄露的ReLU
- def leaky_relu(z, negative_slope=0.1):
- # 调用pytorch的int()函数将bool类型转成int类型,因此调用pytorch的int()函数来进行显式转换
- a1 = (z > 0).int() * z
- a2 = (z <= 0).int() * (negative_slope * z)
- return a1 + a2
- # 在[-10,10]的范围内生成一系列的输入值,用于绘制relu、leaky_relu的函数曲线
- z = torch.linspace(-10, 10, 10000)
- print("ReLU", torch.equal(torch.round(relu(z), decimals=4), torch.round(F.relu(z), decimals=4)))
- print("leaky_relu", torch.equal(torch.round(leaky_relu(z), decimals=4), torch.round(F.leaky_relu(z), decimals=4)))
输出结果如下:

我们发现同Sigmoid函数的情况一样,手写Relu函数和和库函数F.relu在保留小数后四位的时候,值是一样的,但是手写leaky_relu函数和F.leaky_relu函数不论保留几位都是不一样的,那这又是为什么呢?
- 数值稳定性问题:手写leaky_relu函数在实现时可能受到浮点数表示误差和舍入错误的影响,导致在训练过程中出现不稳定的数值行为。而PyTorch内置的leaky_relu函数可能采用更稳定的实现方式,确保了数值稳定性。
- 边缘情况处理:手写leaky_relu函数可能在处理边缘情况时出现错误,例如输入值为0或负数的情况。这些错误可能导致训练过程中的误差累积,进而影响模型的准确性和稳定性。而PyTorch内置的leaky_relu函数已经处理好了这些边缘情况,提供了更可靠的性能。
- 批量处理:手写leaky_relu函数可能无法高效地处理批量输入,这会导致计算效率低下,并可能引入额外的计算误差。而PyTorch内置的leaky_relu函数可以很好地处理批量输入,提供高效的计算性能和更精确的结果。
- 可训练性:手写leaky_relu函数可能不具备与PyTorch内置函数相同的可训练性。PyTorch内置的leaky_relu函数可以与反向传播(backpropagation)和优化器(optimizer)无缝集成,能够根据模型训练过程中的梯度信息自动调整leaky_relu函数的参数,从而获得更好的训练效果。而手写版本可能无法实现这些功能。
总结:手写Relu函数和leaky_relu函数可以被库函数torch.nn.functional.relu和torch.nn.functional.leaky_relu,但是在使用torch.nn.functional.leaky_relu的时候扛干扰的效率会明显优于leaky_relu手写函数,并且使用库函数可以有效地节省大量的时间, 同时PyTorch内置的leaky_relu函数可以与反向传播(backpropagation)和优化器(optimizer)无缝集成,能够根据模型训练过程中的梯度信息自动调整leaky_relu函数的参数,从而获得更好的训练效果。
2.基于前馈神经网络的二分类任务
前馈神经网络的网络结构如图4.3所示。每一层获取前一层神经元的活性值,并重复上述计算得到该层的活性值,传入到下一层。整个网络中无反馈,信号从输入层向输出层逐层的单向传播,得到网络最后的输出
 。
。
图4.3: 前馈神经网络结构
以下是本实验需要导入的包,nndl为自己手写包,网页顶端有显示,自行下载观看。
- import numpy as np
- import torch
- import matplotlib.pyplot as plt
- from nndl.dataset import make_moons
- from nndl.op import Op
- from nndl.opitimizer import Optimizer
- from nndl.metric import accuracy
- from nndl.runner import RunnerV2_1
2.1 数据集的构建
建立一个数据集,这里调用的make_moons函数,函数的具体实现在之前博客提到过,有想了解的可以去翻看之前的博客,生成的数据集具体详情如下:Moon1000数据集,其中训练集640条、验证集160条、测试集200条,是从两个带噪音的弯月形状数据分布中采样得到,每个样本包含2个特征.
- n_samples = 1000
- X, y = make_moons(n_samples=n_samples, shuffle=True, noise=0.5)
- num_train = 640
- num_dev = 160
- num_test = 200
- X_train, y_train = X[:num_train], y[:num_train]
- X_dev, y_dev = X[num_train:num_train + num_dev], y[num_train:num_train + num_dev]
- X_test, y_test = X[num_train + num_dev:], y[num_train + num_dev:]
- y_train = y_train.reshape([-1,1])
- y_dev = y_dev.reshape([-1,1])
- y_test = y_test.reshape([-1,1])
运行结果如下:

2.2 模型的构建
为了更高效的构建前馈神经网络,我们先定义每一层的算子,然后再通过算子组合构建整个前馈神经网络。
假设网络的第
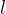 层的输入为第
层的输入为第 层的神经元活性值
层的神经元活性值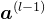 ,经过一个仿射变换,得到该层神经元的净活性值
,经过一个仿射变换,得到该层神经元的净活性值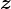 ,再输入到激活函数得到该层神经元的活性值
,再输入到激活函数得到该层神经元的活性值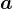 。
。在实践中,为了提高模型的处理效率,通常将
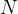 个样本归为一组进行成批地计算。假设网络第层的输入为
个样本归为一组进行成批地计算。假设网络第层的输入为 ,其中每一行为一个样本,则前馈网络中第层的计算公式为
,其中每一行为一个样本,则前馈网络中第层的计算公式为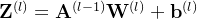
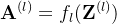
其中
 为个样本第层神经元的净活性值,
为个样本第层神经元的净活性值,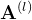 为个样本第层神经元的活性值,
为个样本第层神经元的活性值,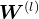 为第层的权重矩阵,
为第层的权重矩阵, 为第层的偏置。
为第层的偏置。为了使后续的模型搭建更加便捷,我们将神经层的计算,都封装成算子,这些算子都继承Op基类。
邱老师按照前馈神经网络的顺序一点一点更新算子,我这里是直接给出包含forward和backword的过程,不分开解释咯~
2.2.1 线性层算子
首先线性层针对的过程是对每层神经元的净活性值的产生,假设对于第L层的神经元,输入为第L-1层的活性值(由激活函数激活后的),对活性值按照权重累加生成第L层神经元的净活性的值,即为线性层。
__init__:为线性层初始化
input_size:输入层神经元数量
out_size:输出层神经元数量
name:给线性层赋一个名字
weight_init:权重的初始化方式 w.shape = [input, output]
bias_init:偏置初始化方式 b.shape=[1,output]
forward:前馈生成净活性值的过程,在这里注意input输入的是一个矩阵,每一行是一个样本
假设N个样本,X.shape=[N, input]
backward: 反向传播更新变量的过程
- class Linear(Op):
- def __init__(self, input_size, output_size, name, weight_init=np.random.standard_normal, bias_init=torch.zeros):
- self.params = {}
- # 初始化权重
- self.params['W'] = weight_init([input_size, output_size])
- self.params['W'] = torch.as_tensor(self.params['W'],dtype=torch.float32)
- # 初始化偏置
- self.params['b'] = bias_init([1, output_size])
- self.inputs = None
- self.grads = {}
- self.name = name
- def forward(self, inputs):
- self.inputs = inputs
- outputs = torch.matmul(self.inputs, self.params['W']) + self.params['b']
- return outputs
- def backward(self, grads):
- """
- 输入:
- - grads:损失函数对当前层输出的导数
- 输出:
- - 损失函数对当前层输入的导数
- """
- self.grads['W'] = torch.matmul(self.inputs.T, grads)
- self.grads['b'] = torch.sum(grads, dim=0)
- # 线性层输入的梯度
- return torch.matmul(grads, self.params['W'].T)
2.2.2 Logistic算子
本次实验采取的Logistic函数作为激活函数,众所周知,Logistic函数有一个很好的性质
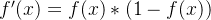 ,因此求Logistic函数的梯度也很简单.
,因此求Logistic函数的梯度也很简单.__init__: 定义三个变量,输入输出值
forward:将净活性值转变为活性值的过程,通过一个激活函数这里采取的是Logistic函数,输入shape = [D, N] ,输出 shape = [D, N],形状不发生改变
backward:反向求Logistic函数的梯度,可以采取Logistic的性质
- class Logistic(Op):
- def __init__(self):
- self.inputs = None
- self.outputs = None
- self.params = None
- def forward(self, inputs):
- """
- 输入:
- - inputs: shape=[N,D]
- 输出:
- - outputs:shape=[N,D]
- """
- outputs = 1.0 / (1.0 + torch.exp(-inputs))
- self.outputs = outputs
- return outputs
- def backward(self, grads):
- # 计算Logistic激活函数对输入的导数
- outputs_grad_inputs = torch.multiply(self.outputs, (1.0 - self.outputs))
- return torch.multiply(grads, outputs_grad_inputs)
2.2.3 层的串行组合
在定义了神经层的线性层算子和激活函数算子之后,我们可以不断交叉重复使用它们来构建一个多层的神经网络。
下面我们实现一个两层的用于二分类任务的前馈神经网络,选用Logistic作为激活函数,可以利用上面实现的线性层和激活函数算子来组装。
- class Model_MLP_L2(Op):
- def __init__(self, input_size, hidden_size, output_size):
- """
- 输入:
- - input_size:输入维度
- - hidden_size:隐藏层神经元数量
- - output_size:输出维度
- """
- self.fc1 = Linear(input_size, hidden_size, name="fc1")
- self.act_fn1 = Logistic()
- self.fc2 = Linear(hidden_size, output_size, name="fc2")
- self.act_fn2 = Logistic()
- self.layers = [self.fc1, self.act_fn1, self.fc2, self.act_fn2]
- def __call__(self, X):
- return self.forward(X)
- def forward(self, X):
- """
- 输入:
- - X:shape=[N,input_size], N是样本数量
- 输出:
- - a2:预测值,shape=[N,output_size]
- """
- z1 = self.fc1(X)
- a1 = self.act_fn1(z1)
- z2 = self.fc2(a1)
- a2 = self.act_fn2(z2)
- return a2
- # 反向计算
- def backward(self, loss_grad_a2):
- loss_grad_z2 = self.act_fn2.backward(loss_grad_a2)
- loss_grad_a1 = self.fc2.backward(loss_grad_z2)
- loss_grad_z1 = self.act_fn1.backward(loss_grad_a1)
- loss_grad_inputs = self.fc1.backward(loss_grad_z1)
测试一下~,具体操作为:令其输入层维度为5,隐藏层维度为10,输出层维度为1,并随机生成一条长度为5的数据输入两层神经网络,观察输出结果,代码如下:
- model = Model_MLP_L2(input_size=5, hidden_size=10, output_size=1)
- # 随机生成1条长度为5的数据
- X = torch.rand(5)
- result = model.forward(X)
- print ("result: ", result)
测试结果如下:

__init__:初始化模块,这里是设计两层二分类的神经网络所以只需要有一个隐藏层,设置两个线性层,两个激活函数即可。
forward:模型根据输入跑出最后结果的过程
backward:根据损失函数,调用各个层反向更新函数的过程
2.3 损失函数
二分类采取交叉熵损失函数,具体见之前的博客。
2.4 模型优化
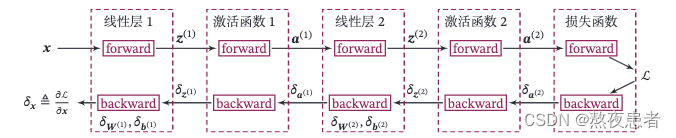
梯度下降法进行优化,神经网络通过链式法则进行反向传播来计算梯度。本模块只讲述backward的编写原理,详细代码2.2已全部展示,不明确的可以看2.2.
2.4.1 BP算法
邱老师在《神经网络与深度学习》明确指出了
一、使用误差反向传播算法的前馈神经网络训练过程可以分为以下三步:
1. 前馈计算每一层的净活性值
 和激活值
和激活值 ,直到最后一层;
,直到最后一层;2. 反向传播计算每一层的误差项
 ;
;3. 计算每一层参数的梯度,并更新参数。
二、在上面实现算子的基础上,来实现误差反向传播算法。在上面的三个步骤中:
1. 第1步是前向计算,可以利用算子的forward()方法来实现;
2. 第2步是反向计算梯度,可以利用算子的backward()方法来实现;
3. 第3步中的计算参数梯度也放到backward()中实现,更新参数放到另外的优化器中专门进行。
2.4.2 交叉熵损失函数
这里个人觉得邱老师讲得不太好理解于是自己准备写一下
(1)二分类
在二分的情况下,模型最后需要预测的结果只有两种情况,对于每个类别我们的预测得到的概率为
 和
和 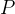 ,此时表达式为:
,此时表达式为:
其中:
- y——表示样本的label,正类为1,负类为0
- p——表示样本预测为正的概率(2)多分类
多分类的情况实际上就是对二分类的扩展:

其中:
-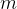 ——类别的数量;
——类别的数量;
-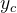 ——指示变量(0或1),如果该类别和样本的类别相同就是1,否则是0;
——指示变量(0或1),如果该类别和样本的类别相同就是1,否则是0;
-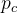 ——对于观测样本属于类别
——对于观测样本属于类别 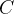 的预测概率。
的预测概率。这里对二分类进行讨论,因为多分类的情况下倒数较为麻烦,这里先不进行讨论,求导如下:

这就明确很多了~
代码如下:
- # 实现交叉熵损失函数
- class BinaryCrossEntropyLoss(Op):
- def __init__(self, model):
- self.predicts = None
- self.labels = None
- self.num = None
- self.model = model
- def __call__(self, predicts, labels):
- return self.forward(predicts, labels)
- def forward(self, predicts, labels):
- """
- 输入:
- - predicts:预测值,shape=[N, 1],N为样本数量
- - labels:真实标签,shape=[N, 1]
- 输出:
- - 损失值:shape=[1]
- """
- self.predicts = predicts
- self.labels = labels
- self.num = self.predicts.shape[0]
- loss = -1. / self.num * (torch.matmul(self.labels.t(), torch.log(self.predicts))
- + torch.matmul((1 - self.labels.t()), torch.log(1 - self.predicts)))
- # loss = paddle.squeeze(loss, axis=1)
- loss = loss.squeeze(1)
- return loss
- def backward(self):
- # 计算损失函数对模型预测的导数
- loss_grad_predicts = -1.0 * (self.labels / self.predicts -
- (1 - self.labels) / (1 - self.predicts)) / self.num
- # 梯度反向传播
- self.model.backward(loss_grad_predicts)
2.4.3 Logisitc函数
backward函数如下:
- def backward(self, grads):
- # 计算Logistic激活函数对输入的导数
- outputs_grad_inputs = torch.multiply(self.outputs, (1.0 - self.outputs))
- return torch.multiply(grads, outputs_grad_inputs)
outputs_grad_inputs:可以理解为返回激活函数的梯度
2.4.4 线性层
- def backward(self, grads):
- """
- 输入:
- - grads:损失函数对当前层输出的导数
- 输出:
- - 损失函数对当前层输入的导数
- """
- self.grads['W'] = torch.matmul(self.inputs.T, grads)
- self.grads['b'] = torch.sum(grads, dim=0)
- # 线性层输入的梯度
- return torch.matmul(grads, self.params['W'].T)
可用以下三个式子来做解释,grads['W']是W的梯度,所以就是上一层的活性值,grads['b']是b的梯度,结果为1,所以b的梯度为传入的grads值,返回的为对输入数据的求导即权重矩阵

2.2.5 整个网络
- def backward(self, loss_grad_a2):
- loss_grad_z2 = self.act_fn2.backward(loss_grad_a2)
- loss_grad_a1 = self.fc2.backward(loss_grad_z2)
- loss_grad_z1 = self.act_fn1.backward(loss_grad_a1)
- loss_grad_inputs = self.fc1.backward(loss_grad_z1)
这个很好理解就是分别调用激活函数梯度计算,然后线性层梯度计算,再激活函数梯度计算,再线性层梯度计算,按照反向传播的过程调用即可。
2.2.6 优化器
- class BatchGD(Optimizer):
- def __init__(self, init_lr, model):
- super(BatchGD, self).__init__(init_lr=init_lr, model=model)
- def step(self):
- # 参数更新
- for layer in self.model.layers: # 遍历所有层
- if isinstance(layer.params, dict):
- for key in layer.params.keys():
- layer.params[key] = layer.params[key] - self.init_lr * layer.grads[key]
优化器,但是我还是更喜欢叫这个为学习器,与梯度下降不同的是这个需要从后到前遍历所有层,对每层参数分别做更新。
__init__:为简单的初始化,这里不做解释
step:参数更新,Model_MLP_L2类中我们把所有层封存在了layers中,所以第一个for循环是在遍历所有的层,通过if判断寻找线性层进行参数更新(Logistic类中此参数置为None,对应的类型如下

无类型所以可以挑选出来线性层和Logistic层),通过遍历层中的关键字分别为W,b对参数进行更行,init_lr为学习率。
2.5 完善Runner类
- import os
- import torch
- class RunnerV2_1(object):
- def __init__(self, model, optimizer, metric, loss_fn, **kwargs):
- self.model = model
- self.optimizer = optimizer
- self.loss_fn = loss_fn
- self.metric = metric
- # 记录训练过程中的评估指标变化情况
- self.train_scores = []
- self.dev_scores = []
- # 记录训练过程中的评价指标变化情况
- self.train_loss = []
- self.dev_loss = []
- def train(self, train_set, dev_set, **kwargs):
- # train_set 训练数据 dev_set 验证集合
- # 传入训练轮数,如果没有传入值则默认为0
- num_epochs = kwargs.get("num_epochs", 0)
- # 传入log打印频率,如果没有传入值则默认为100
- log_epochs = kwargs.get("log_epochs", 100)
- # 传入模型保存路径
- save_dir = kwargs.get("save_dir", None)
- # 记录全局最优指标
- best_score = 0
- # 进行num_epochs轮训练
- for epoch in range(num_epochs):
- X, y = train_set
- # 获取模型预测 Model_MLP_L2.forward
- logits = self.model(X)
- # 计算交叉熵损失 BinaryCrossEntropyLoss.forward(predicts, lebels)
- trn_loss = self.loss_fn(logits, y)
- # 记录误差
- self.train_loss.append(trn_loss.item())
- # 计算评估指标
- trn_score = self.metric(logits, y).item()
- self.train_scores.append(trn_score)
- # BinaryCrossEntropyLoss.backward
- self.loss_fn.backward()
- # 参数更新 BatchGD.step
- self.optimizer.step()
- dev_score, dev_loss = self.evaluate(dev_set)
- # 如果当前指标为最优指标,保存该模型
- if dev_score > best_score:
- print(f"[Evaluate] best accuracy performence has been updated: {best_score:.5f} --> {dev_score:.5f}")
- best_score = dev_score
- if save_dir:
- self.save_model(save_dir)
- if log_epochs and epoch % log_epochs == 0:
- print(f"[Train] epoch: {epoch}/{num_epochs}, loss: {trn_loss.item()}")
- def evaluate(self, data_set):
- X, y = data_set
- # 计算模型输出
- logits = self.model(X)
- # 计算损失函数
- loss = self.loss_fn(logits, y).item()
- self.dev_loss.append(loss)
- # 计算评估指标
- score = self.metric(logits, y).item()
- self.dev_scores.append(score)
- return score, loss
- def predict(self, X):
- return self.model(X)
- def save_model(self, save_dir):
- # 对模型每层参数分别进行保存,保存文件名称与该层名称相同
- for layer in self.model.layers: # 遍历所有层
- if isinstance(layer.params, dict):
- if not os.path.exists(save_dir):
- os.mkdir(save_dir)
- torch.save(layer.params, os.path.join(save_dir, layer.name + ".pdparams"))
- def load_model(self, model_dir):
- # 获取所有层参数名称和保存路径之间的对应关系
- model_file_names = os.listdir(model_dir)
- name_file_dict = {}
- for file_name in model_file_names:
- name = file_name.replace(".pdparams", "")
- name_file_dict[name] = os.path.join(model_dir, file_name)
- # 加载每层参数
- for layer in self.model.layers: # 遍历所有层
- if isinstance(layer.params, dict):
- name = layer.name
- file_path = name_file_dict[name]
- layer.params = torch.load(file_path)
注意,邱老师的代码不能直接用,因为没有判定文件夹是否存在,需要加一个判断才可。详情关注save_model模块。
2.6 模型训练
- torch.seed()
- epoch_num = 1000
- model_saved_dir = "model"
- # 输入层维度为2
- input_size = 2
- # 隐藏层维度为5
- hidden_size = 5
- # 输出层维度为1
- output_size = 1
- # 定义网络
- model = Model_MLP_L2(input_size=input_size, hidden_size=hidden_size, output_size=output_size)
- # 损失函数
- loss_fn = BinaryCrossEntropyLoss(model)
- # 优化器
- learning_rate = 0.2
- optimizer = BatchGD(learning_rate, model)
- # 评价方法
- metric = accuracy
- # 实例化RunnerV2_1类,并传入训练配置
- runner = RunnerV2_1(model, optimizer, metric, loss_fn)
- runner.train([X_train, y_train], [X_dev, y_dev], num_epochs=epoch_num, log_epochs=50, save_dir=model_saved_dir)
训练结果如下:
可视化观察训练集与验证集的损失函数变化情况,代码如下:
- plt.figure()
- plt.plot(range(epoch_num), runner.train_loss, color="#e4007f", label="Train loss")
- plt.plot(range(epoch_num), runner.dev_loss, color="#f19ec2", linestyle='--', label="Dev loss")
- plt.xlabel("epoch", fontsize='large')
- plt.ylabel("loss", fontsize='large')
- plt.legend(fontsize='x-large')
- plt.savefig('fw-loss2.pdf')
- plt.show()

2.7 性能评价
使用测试集对训练中的最优模型进行评价,观察模型的评价指标。代码实现如下:
- # 加载训练好的模型
- runner.load_model(model_saved_dir)
- # 在测试集上对模型进行评价
- score, loss = runner.evaluate([X_test, y_test])
- print("[Test] score/loss: {:.4f}/{:.4f}".format(score, loss))
结果如下:

从结果来看,模型在测试集上取得了较高的准确率。
下面对结果进行可视化,代码如下:
- import math
- # 均匀生成40000个数据点
- x1, x2 = torch.meshgrid(torch.linspace(-math.pi, math.pi, 200), torch.linspace(-math.pi, math.pi, 200))
- x = torch.stack([torch.flatten(x1), torch.flatten(x2)], dim=1)
- # 预测对应类别
- y = runner.predict(x)
- y = torch.squeeze(torch.tensor((y >= 0.5), dtype=torch.float32)) # 但去除了所有大小为1的维度
- # 绘制类别区域
- plt.ylabel('x2')
- plt.xlabel('x1')
- plt.scatter(x[:,0].tolist(), x[:,1].tolist(), c=y.tolist(), cmap=plt.cm.Spectral)
- plt.scatter(X_train[:, 0].tolist(), X_train[:, 1].tolist(), marker='*', c=torch.squeeze(y_train,dim=-1).tolist())
- plt.scatter(X_dev[:, 0].tolist(), X_dev[:, 1].tolist(), marker='*', c=torch.squeeze(y_dev,dim=-1).tolist())
- plt.scatter(X_test[:, 0].tolist(), X_test[:, 1].tolist(), marker='*', c=torch.squeeze(y_test,dim=-1).tolist())
- plt.show()
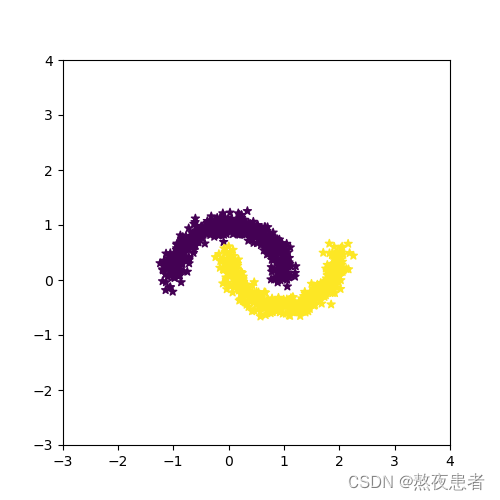
可视化结果如下:

3.总结
1.这次主要做的工作是搭建了一个两层的前馈神经网络,较为容易,基本上遇到debug也都会改,不存在什么特别难的问题,基础记牢了也没那么难理解。
2.因为同为二分类问题嘛,写完博客的时候就不想继续写下一个实验了,就闲来无事,翻了翻之前的博客,找到Logistic回归模型的结果对比了以下,看没啥大的区别吧,得分都差不太多吧1个点左右,神经网络没我幻想的那么优秀,抱着帮他正名的态度搜了一下,可能是因为隐藏层太少的缘故,毕竟神经网络可是说越深越优秀的不是。
3.有没有发现我的公式变得好看了,我发现在线编辑器美观程度远远高于他自带的,算是一个小收获吧~
Logistic回归的结果:

4.修正
本着想看看大佬博客关注的点自己关注没,结果发现,哇,我数据集也错了耶,
X, y = make_moons(n_samples=n_samples, shuffle=True, noise=0.5)都源于这句话,noise太大不行,太小也不行,不然没有月牙的形状,害,本来想着休息的,结果休息休息加班了又

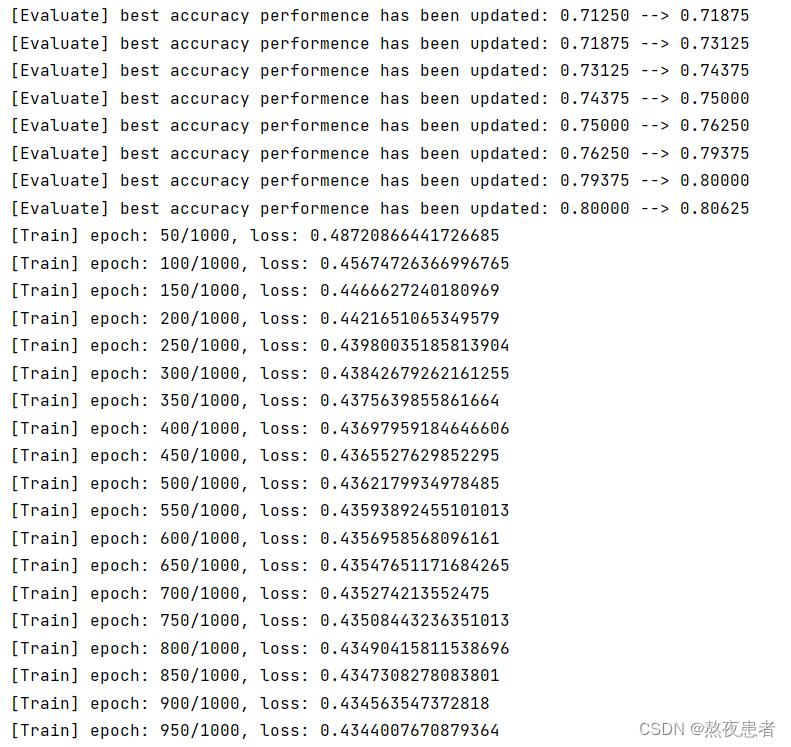
noise应取0.1~0.3之间,为了验证大佬的理论我偷摸自己跑了一下
noise = 0

noise = 0.1
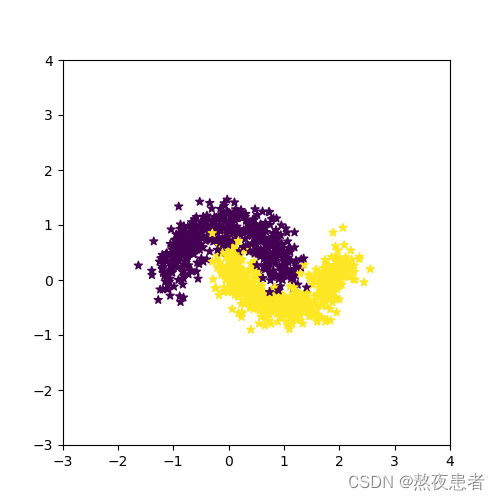
noise = 0.2
noise = 0.3

看起来确实,noise越大,高斯噪声参数越大,这会使得原本弯月数据集样本点过于分散,失去了数据集原本的特征,到0.3看起来就已经不太行了。发现noise=0.1神经网络跑的结果为1分,于是尝试了一下


没有1分,骗人都都是骗人的,就是为了让我加班,哆啦A梦要不干了

但是觉得跑了就不能白跑,看看Logistic回归的正确率啥样
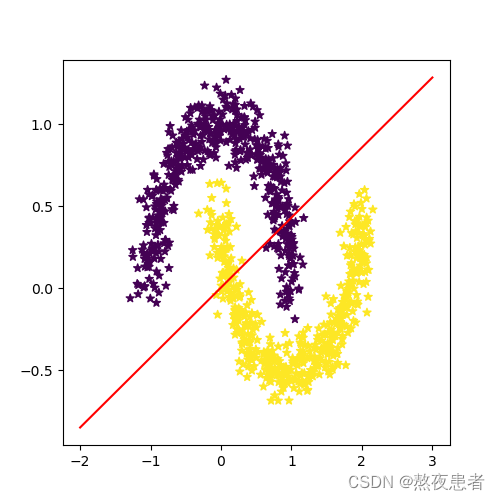

这么看来确实神经网络还是好哈~,可以安心睡觉了太不容易了

5.参考博客
-
相关阅读:
【推荐系统】GBDT + LR模型 笔记
web网页设计期末课程大作业:美食餐饮文化主题网站设计——中华美德6页面HTML+CSS+JavaScript
如何选择和使用腾讯云服务器的方法新手教程
基于神经网络的预测控制,神经网络预测系统应用
怎么从零开始运行github / 现成的项目
更改表的CHARSET
Python学习 day02(注意事项)
【PAT A-1038】Recover the Smallest Number
LeetCode 744. 寻找比目标字母大的最小字母
学习笔记-.net安全之SiteServer远程下载分析
- 原文地址:https://blog.csdn.net/m0_70026215/article/details/133888145
