-
一致性哈希算法
目录
一、普通哈希算法
1.1 概念及其使用情况
假设现在线上部署了三台缓存服务器,分别为0号、1号、2号。现有3万张图片需要缓存,最佳情况下希望图片被均匀的分配到3台缓存服务器上,即每台机器1万张左右
可采用普通哈希算法进行操作,对缓存项的键进行哈希,将hash后的结果对缓存服务器的数量进行取模操作,通过取模后的结果,决定缓存项将会缓存在哪一台服务器上
hash(图片名称) % 机器数量
下面假设图片名称是不重复的。对同一个图片名称进行hash得到的结果是不变的,假设有3台服务器,将hash后的结果对3进行求余,那么余数一定是0、1或者2。若求余的结果为0, 就将当前图片缓存在0号服务器上,依次类推
访问任意图片时,只要再次对图片名称进行上述运算,即可得出图片应该存放在哪一台缓存服务器上,只要在这一台服务器上查找图片即可,若图片在对应的服务器上不存在,则证明对应的图片没有被缓存,也不用再去查找其他缓存服务器了

1.2 缺陷
当服务器已经不能满足缓存需求,就需增加服务器数量。假设增加了一台缓存服务器,此时若仍使用上述方法对同一张图片进行读取,那么这张图片计算出的服务器编号必定与3台服务器时计算出的服务器编号不同,因为机器数量由3变为了4,导致缓存失效
当应用无法从缓存中获取数据时,则会向后端服务器请求数据;同理,假设突然有一台缓存服务器出现了故障,那么则需要将故障机器移除,那么缓存服务器数量从3台变为2台,同样会导致大量缓存在同一时间失效,造成了缓存的雪崩,后端服务器将会承受巨大的压力,整个系统很有可能被压垮。为了解决这种情况,就有了一致性哈希算法
二、一致性哈希算法
2.1 概念
一致性哈希算法也需要进行取模,但普通算法是对服务器的数量进行取模,而一致性哈希算法是对
 取模。具体步骤如下:
取模。具体步骤如下:- 一致性哈希算法将整个哈希值空间按照顺时针方向组织成一个虚拟的圆环,称为 Hash 环
- 接着将各个服务器使用Hash函数进行哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,从而确定每台机器在哈希环上的位置
- 最后使用算法定位数据访问到相应服务器:将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针寻找,遇到的第一台服务器就是其定位的服务器
具体案例说明
- 哈希环的组织
将整个哈希表想象成一个圆,由2^32个点组成的圆。圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、5、6……直到
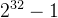 ,即0点左侧的第一个点代表2^32-1,将这个由 2^32 个点组成的圆环称为hash环
,即0点左侧的第一个点代表2^32-1,将这个由 2^32 个点组成的圆环称为hash环
- 确定服务器在哈希环上的位置
hash(服务器IP地址) % (2^32)上述公式的计算结果一定是0到
之间的整数,hash环上必定有一个点与这个整数对应,所以可以使用这个整数代表服务器,即将服务器映射到hash环上。假设有ABC三台服务器,这3台服务器在哈希环上的示意图如下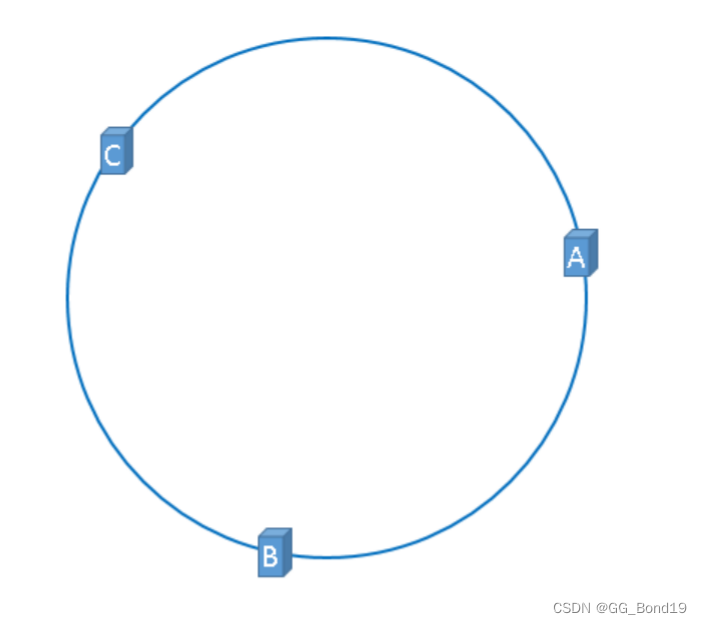
- 将数据映射到哈希环上并定位
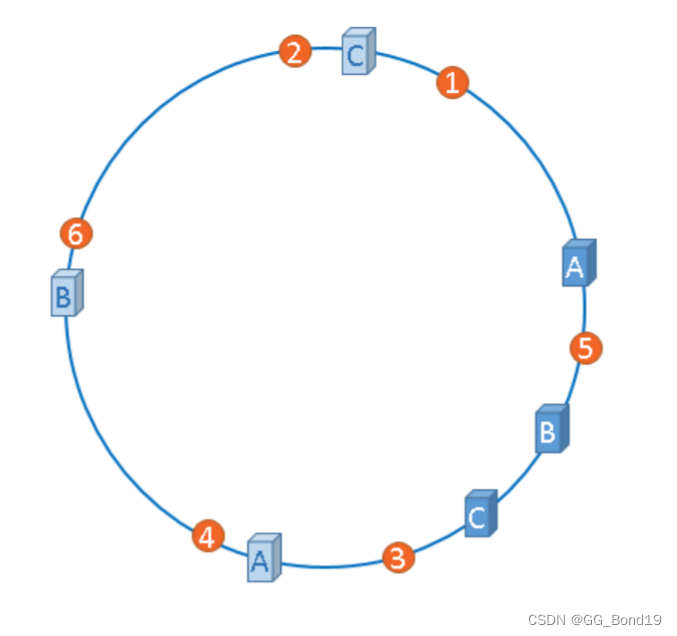
hash(图片名称) % (2^32)假设有4张图片,映射后的示意图如下,其中橘黄色的点表示图片:

从图片的位置开始,顺时针方向遇到的第一个服务器就是图片存放的服务器。1号、2号图片将会被缓存到服务器A上,3号图片将会被缓存到服务器B上,4号图片将会被缓存到服务器C上
2.2 优点
若简单对服务器数量进行取模,那么当服务器数量发生变化时,会产生缓存雪崩,很有可能导致系统崩溃,而一致性哈希算法可以很好的缓解这个问题,因为一致性Hash算法对于节点的增减都只需重定位环空间中的一小部分数据,只有部分缓存会失效,不至于将所有压力都在同一时间集中到后端服务器上,具有较好的容错性和可扩展性
假设服务器B出现了故障,需要将服务器B移除,那么移除前后的示意图如下图所示:

只需要将原本落点在A、B服务器之间的数据,重定位到C服务器上即可
2.3 hash倾斜与虚拟结点
一致性哈希算法在服务节点太少的情况下,容易因为节点分部不均匀而造成数据倾斜问题,即被缓存的对象大部分集中缓存在某一台服务器上,从而出现数据分布不均匀的情况

为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制。即对每一个服务器计算多个哈希,每个计算结果位置都放置一个服务节点,即虚拟节点,一个实际物理节点可以对应多个虚拟节点。虚拟节点越多,hash环上的节点就越多,缓存被均匀分布的概率就越大,数据定位算法不变,只多了一步虚拟节点到实际节点的映射
具体做法可以在服务器ip或主机名的后面增加编号来实现,加入虚拟节点以后的hash环如下:
-
相关阅读:
分布式存储--类Redis存储
【FAQ】HarmonyOS SDK 闭源开放能力 —Push Kit(3)
2023研究生数学建模E题思路+模型+代码+论文(持续更新中) 出血性脑卒中临床智能诊疗建模
设计模式学习笔记 - 设计原则 - 6.KISS原则和YAGNI原则
Java和Kotlin的Field在继承中的不同表现
【GUI】Python图形界面(三)
射频微波芯片设计3:射频微波芯片设计基础知识
JavaScript数据类型转换
3D人物建模用哪个软件入门比较快?
Vue2组件通信的方式
- 原文地址:https://blog.csdn.net/GG_Bruse/article/details/131873406