-
处理大数据的基础架构,OLTP和OLAP的区别,数据库与Hadoop、Spark、Hive和Flink大数据技术
处理大数据的基础架构,OLTP和OLAP的区别,数据库与Hadoop、Spark、Hive和Flink大数据技术
2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开
测开的话,你就得学数据库,sql,oracle,尤其sql要学,当然,像很多金融企业、安全机构啥的,他们必须要用oracle数据库
这oracle比sql安全,强大多了,所以你需要学习,最重要的,你要是考网络警察公务员,这玩意你不会就别去报名了,耽误时间!
与此同时,既然要考网警之数据分析应用岗,那必然要考数据挖掘基础知识,今天开始咱们就对数据挖掘方面的东西好生讲讲 最最最重要的就是大数据,什么行测和面试都是小问题,最难最最重要的就是大数据技术相关的知识笔试
处理大数据的基础架构
处理大数据的基础架构主要有以下几种:
分布式计算框架。
如Hadoop、Spark、Hive和Flink等,这些框架可以处理大规模的数据,并支持分布式存储和计算。分布式文件系统。
如HDFS(Hadoop Distributed File System)和Google File System等,这些系统可以存储大规模的文件,并支持分布式访问和读取。数据库集群。
如MySQL集群、PostgreSQL集群等,这些集群可以提高数据处理效率和可用性,并支持分布式事务处理。NoSQL数据库。
如MongoDB、Cassandra和Redis等,这些数据库可以处理半结构化和非结构化的数据,并支持高并发写入和读取。云平台。
如Amazon AWS、Google Cloud和阿里云等,这些云平台可以提供虚拟化资源、弹性伸缩和自动化运维等功能,使得处理大数据更加灵活和高效。这些基础架构可以相互组合和扩展,以适应不同的大数据处理场景和需求。
之后我们一个个来学习上述提到的东西,形成一个大数据处理的框架,备考大数据类的试题
冲
Hadoop、Spark、Hive和Flink

小数据问题不大OLTP是啥?
OLTP( On-Line Transaction Processing ) 联机事务处理过程,
通常也可以成为面向交易的处理系统。个人理解为主要场景针对用户人机交互频繁,数据量小,操作快速响应的实时处理系统中。
Mysql以及Oracle等数据库软件可以理解为OLTP的工业应用软件体现。OLAP( On-Line Analytical Processing),联机分析处理过程。
个人理解为主要场景针对大批量数据,实时性无要求,基于数仓多维模型,进行分析操作的系统中。
Hadoop体系中MapReduce、Hive、Spark、Flink等都可以进行为OLAP实现。原来如此了,数据库做不了大数据的分析类的问题
T是事务
A是分析为什么要大数据?

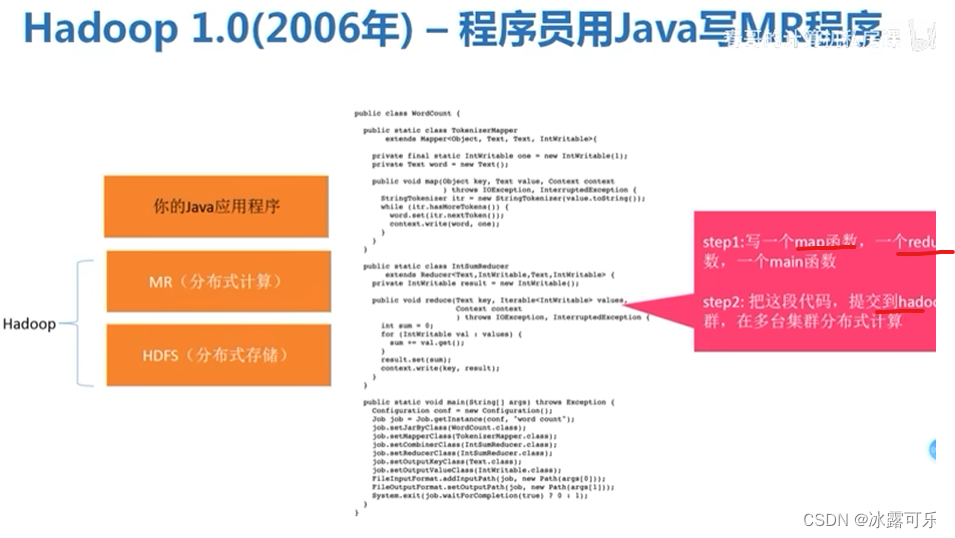
06年写Java的MapReduce程序,难理解后来写sql得了,很简单


yarn出来就调度一把
美滋滋
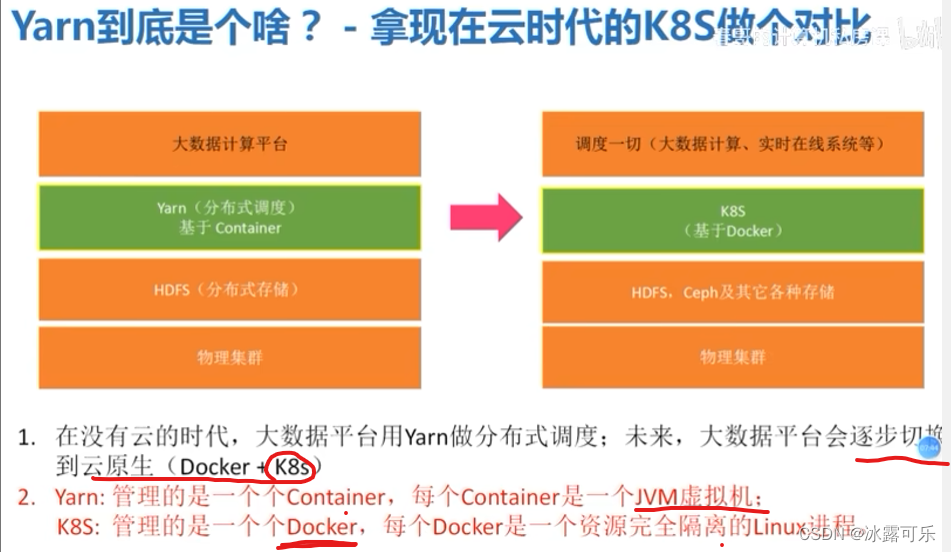
docker现在听说得很多:隔离空间
yarn是container集装箱

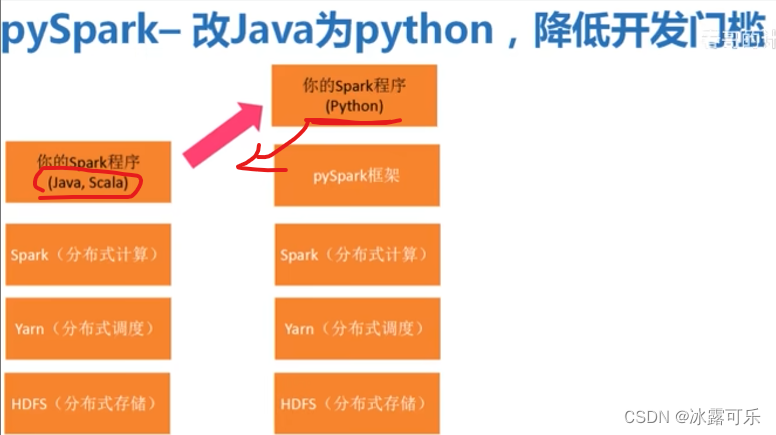
只写sql然后转译为hive那边的Java
还有pyspark,写Python很容易
相当于是兼容超级多的程序批处理,这些是【离线一大批】
下面是流式计算【实时快速处理】

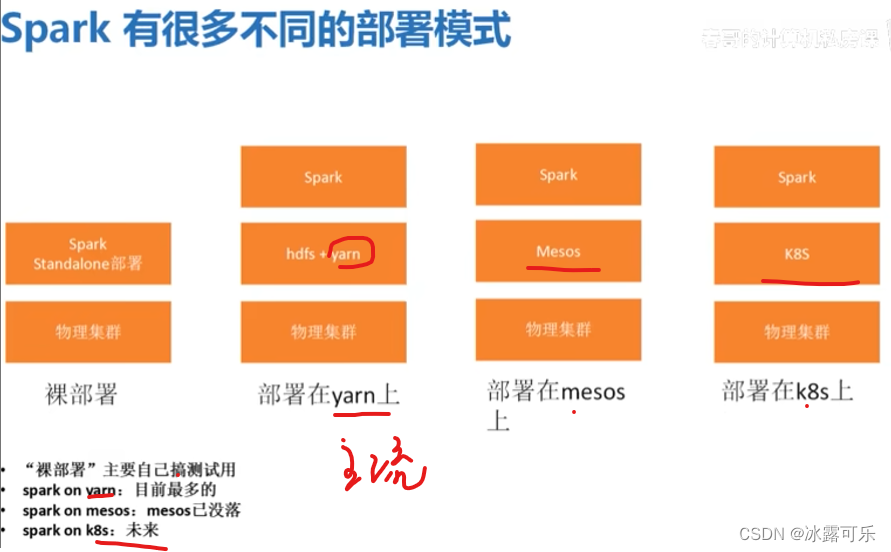

两家很骚,后来俩都能处理了
各种技术你看看是不是穿起来了………………
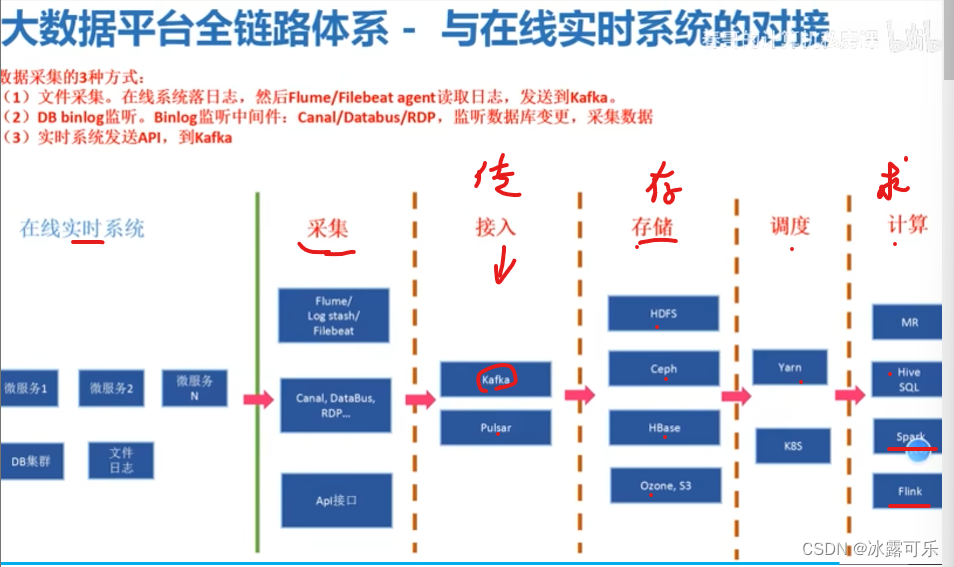

你是做那一层呢?

kafka传输技术,快速
我们从传输开始学起
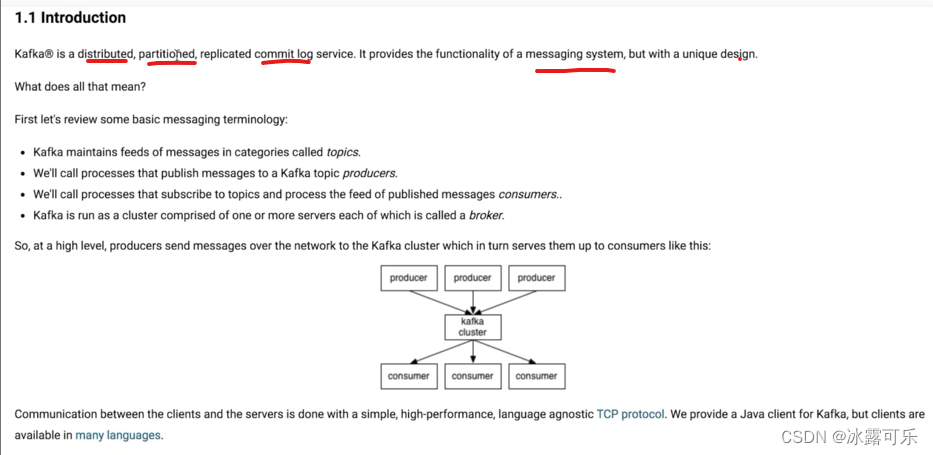

TB级别量的数据,后续可以对接很多大数据处理技术框架
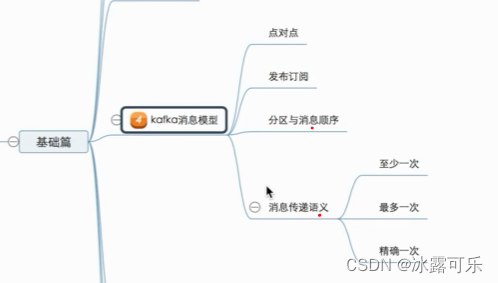
有点厉害了现有的消息模型?


半结构化的东西kafka是分布式消息系统

使得kafka有扩展性

offset不可重复
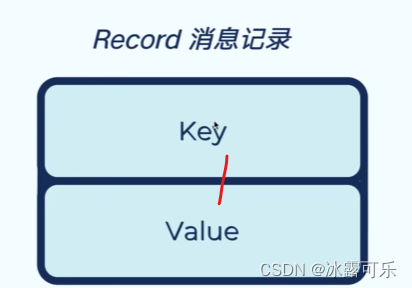
map消息
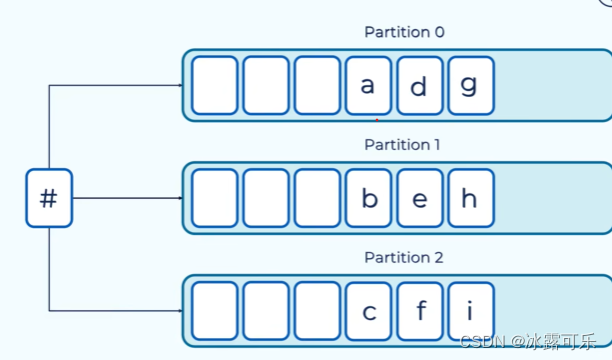
不给key那就随机分配
否则分区

同样的key,同样的key放一起
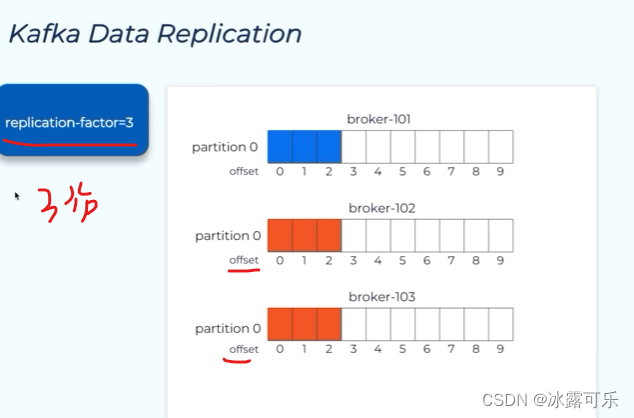

follower就去复制数据,同步,保持数据的可恢复性
这样的话,就不会丢失了
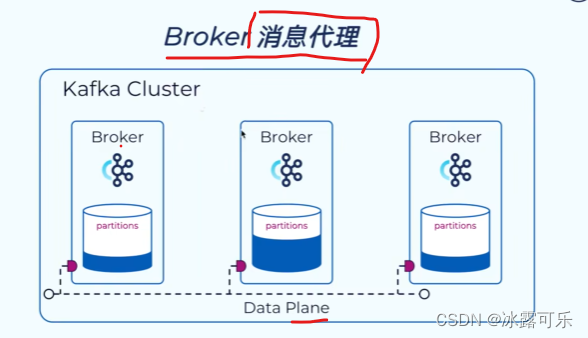
broker就是一台服务器,负责读写
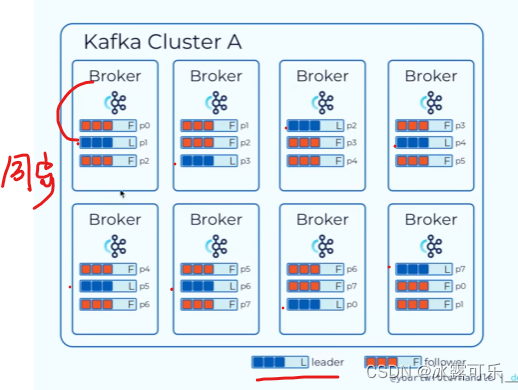
主分区由broker读写kafka监听器



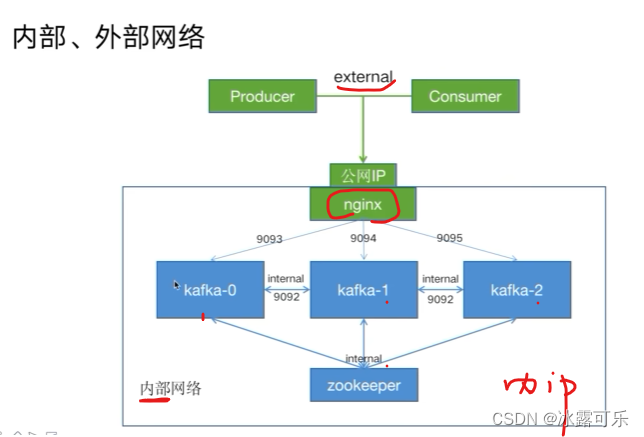
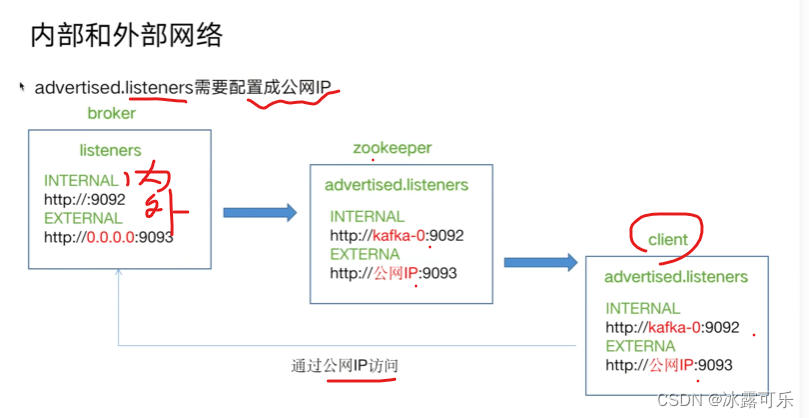
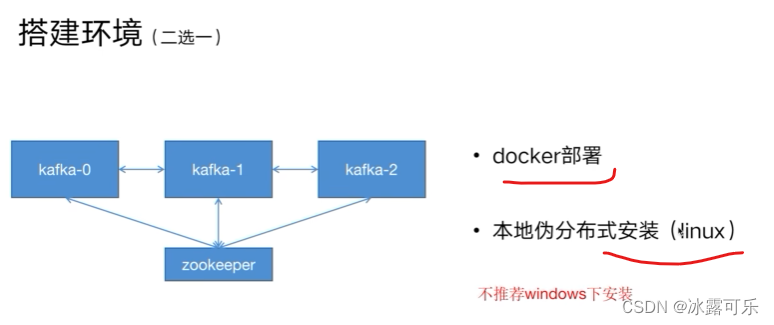
docker去部署kafka的内外网监听端口
kafka的消息模型

处于性能和开销的考虑
否则还要维护锁,加锁,减锁
否则就会引入竞争,麻烦
最大化我们要提升性能和吞吐量
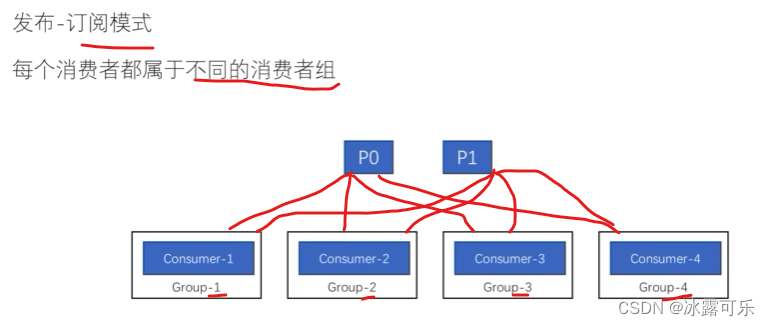

这种是一对一


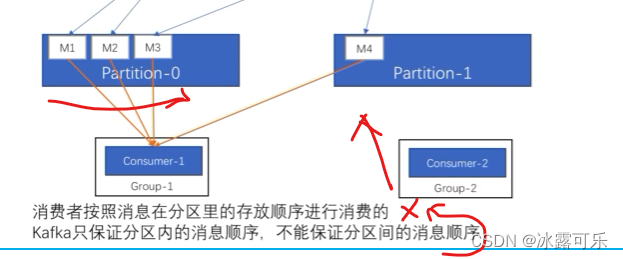
不同分区之间的消费顺序不知道
offset早的是先消费

你想要保证顺序会设置key同
tcp?
ack确认信息

先读信息,至少读一次

给位置,最多读一次,可以不读

生产者api

生产者只大量生产,不管消费,现在就是中国缓冲区满了,老百姓没钱消费,导致生产过剩需要通过一带一路出去消费,这时候美国不乐意

物流系统?


就是网购系统,一次精确消费
我扣款那边就要收款
我失败他不能收款
我付款了,他不能允许说没收到这就是原子性
数据库就这样的特性

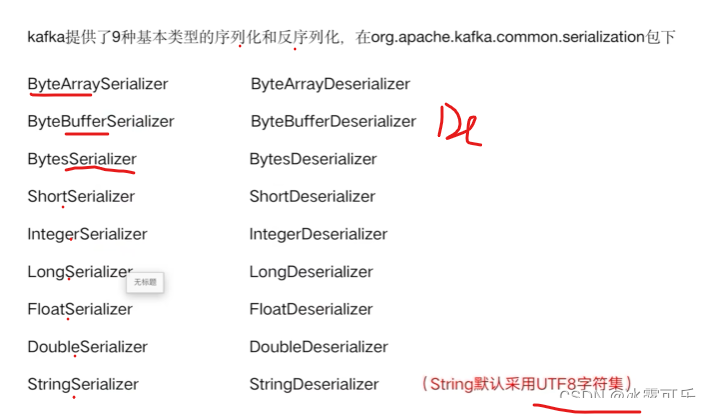
kafka序列化

前序、中序、后序序列化
跟买电脑一样
一堆零件,你送到了,找师傅安装


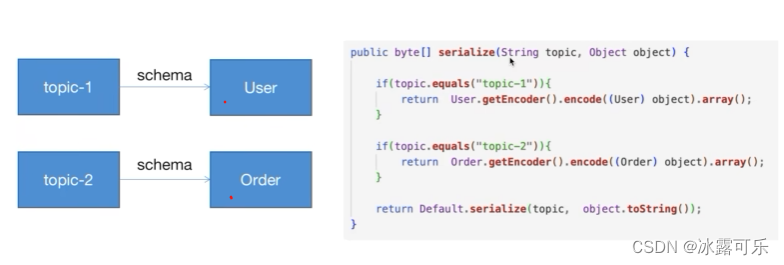
实际上

要卡主时间顺序的骚
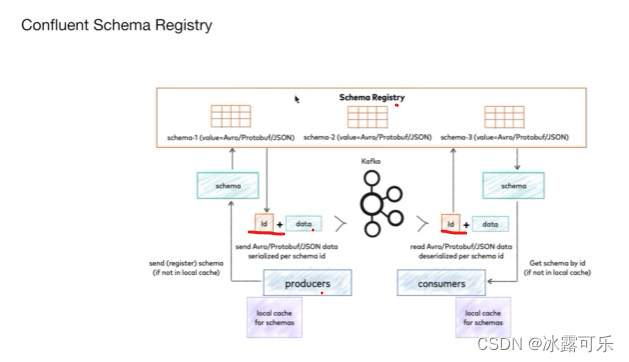
注册制

header标识一下

实际订餐和菜品看不到

如果前面完不成,后面就gg
网络延时导致的
异步重试顺序如何保证
一会上菜,半天看不到,gg
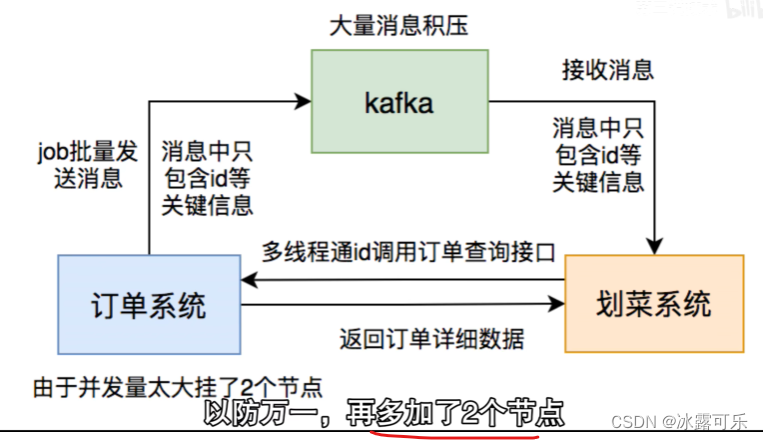
消息积压很恶心
不看所有信息,只看id

又有问题,看日志
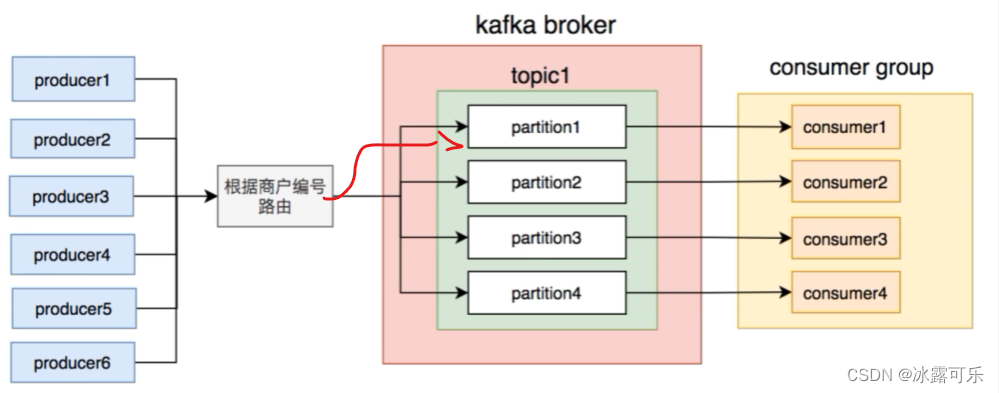
有几个商户的订单贼多,都放一个partition,怎么办?那按照用户编号来放,这样,某个订单就走同一个partition
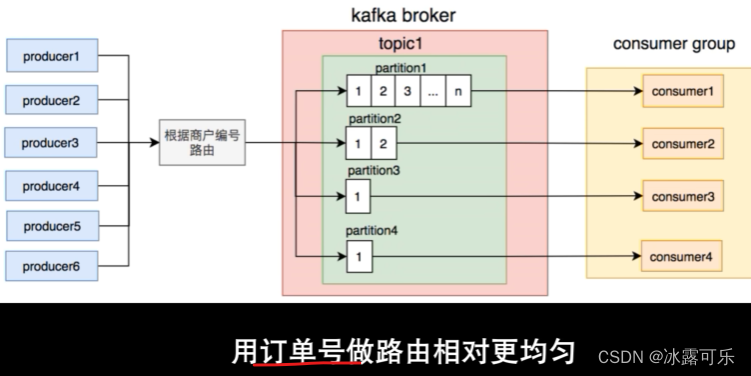
这样好多了
后面呢?

促销……

太骚了






哈哈哈技术太难了
消息积压有不同的原因单表存了太多的菜品


并发太大,俩请求同事查到,id不存在
同时插入,第二个就gg
加锁?Redis分布式锁怎么说?
不行,消费着网络超时gg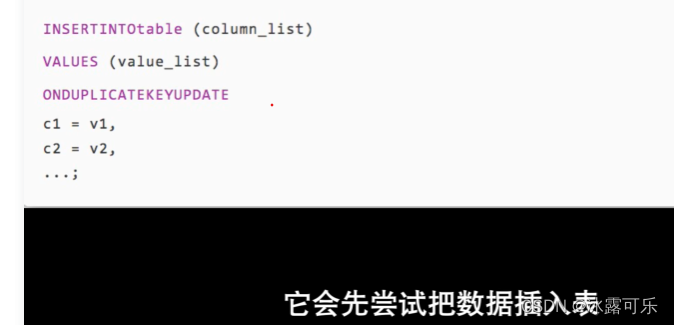
尝试插入,不行就改key

主从服务器
有订单,但是没有菜
主从数据库同步延时
就查不到数据
或者查不到最新数据


精确传才行kafka默认就是容易重复

不存在插入,存在就更新
公用数据库和kafka系统在不同环境中切换容易出错
所以配置要搞清楚cpu容易挂的话,gg
kafka是牛逼的,很少出问题,大多都是逻辑出了问题。
总结
提示:重要经验:1)
2)学好oracle,即使经济寒冬,整个测开offer绝对不是问题!同时也是你考公网络警察的必经之路。
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。 -
相关阅读:
01 kafka 记录的存储
【ARMv8/v9 GIC- 700 系列 2 -- GIC-700 上电控制寄存器 GICR_PWRR】
java计算机毕业设计ssm中小学信息技术课程考试系统
给大家分享下做短视频运营的干货
c++普通平衡树(treap)模版,板子
Qt学习总结之布局管理
企业级数据安全,天翼云是这样理解的
【前端性能】性能优化手段-高频面试题
js/axios/umi-request 根据后端返回的二进制流下载文件
spfa 算法找负环
- 原文地址:https://blog.csdn.net/weixin_46838716/article/details/134088711